Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Exporter les métriques Traefik dans InfluxDB dans un contexte Kubernetes
kubernetes traefik influxdb métrique timeseriesTraefik, depuis sa version V1, permet d’envoyer des métriques vers différents backends (StatsD, Prometheus, InfluxDB et Datadog). J’ai enfin pris le temps d’activer cette fonctionnalité et de creuser un peu le sujet étant donné que le dashboard de Traefik V2 n’affiche plus certaines de ses statistiques.
La documentation de Traefik sur le sujet :
Commençons par créer une base traefik dans InfluxDB (version 1.7.8)
influx
Connected to http://localhost:8086 version 1.7.8
InfluxDB shell version: 1.7.9
> auth
username: XXX
password: XXX
> CREATE DATABASE traefik
> CREATE USER traefik WITH PASSWORD '<password>'
> GRANT ALL ON traefik to traefik
> SHOW GRANTS FOR traefik
database privilege
-------- ---------
traefik ALL PRIVILEGES
> quit
Dans mon cas, l’accès à InfluxDB se fait en https au travers d’une (autre) instance Traefik. J’utilise donc la connexion en http plutôt qu’en udp.
Cela donne les instructions suivantes en mode CLI :
--metrics=true
--metrics.influxdb=true
--metrics.influxdb.address=https://influxdb.domain.tld:443
--metrics.influxdb.protocol=http
--metrics.influxdb.database=traefik
--metrics.influxdb.username=traefik
--metrics.influxdb.password=<password>
J’ai gardé les valeurs par défaut pour addEntryPointsLabels (true), addServicesLabels (true) et pushInterval (10s).
Cela donne le Deployment suivant :
apiVersion: apps/v1
kind: Deployment
metadata:
name: traefik2-ingress-controller
labels:
k8s-app: traefik2-ingress-lb
spec:
replicas: 2
selector:
matchLabels:
k8s-app: traefik2-ingress-lb
template:
metadata:
labels:
k8s-app: traefik2-ingress-lb
name: traefik2-ingress-lb
spec:
serviceAccountName: traefik2-ingress-controller
terminationGracePeriodSeconds: 60
containers:
- image: traefik:2.0.6
name: traefik2-ingress-lb
ports:
- name: web
containerPort: 80
- name: admin
containerPort: 8080
- name: secure
containerPort: 443
readinessProbe:
httpGet:
path: /ping
port: admin
failureThreshold: 1
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 2
livenessProbe:
httpGet:
path: /ping
port: admin
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 2
args:
- --entryPoints.web.address=:80
- --entryPoints.secure.address=:443
- --entryPoints.traefik.address=:8080
- --api.dashboard=true
- --api.insecure=true
- --ping=true
- --providers.kubernetescrd
- --providers.kubernetesingress
- --log.level=ERROR
- --metrics=true
- --metrics.influxdb=true
- --metrics.influxdb.address=https://influxdb.domain.tld:443
- --metrics.influxdb.protocol=http
- --metrics.influxdb.database=traefik
- --metrics.influxdb.username=traefik
- --metrics.influxdb.password=<password>
Appliquer le contenu du fichier dans votre cluster Kubernetes
kubectl apply -f deployment.yml -n <namespace>
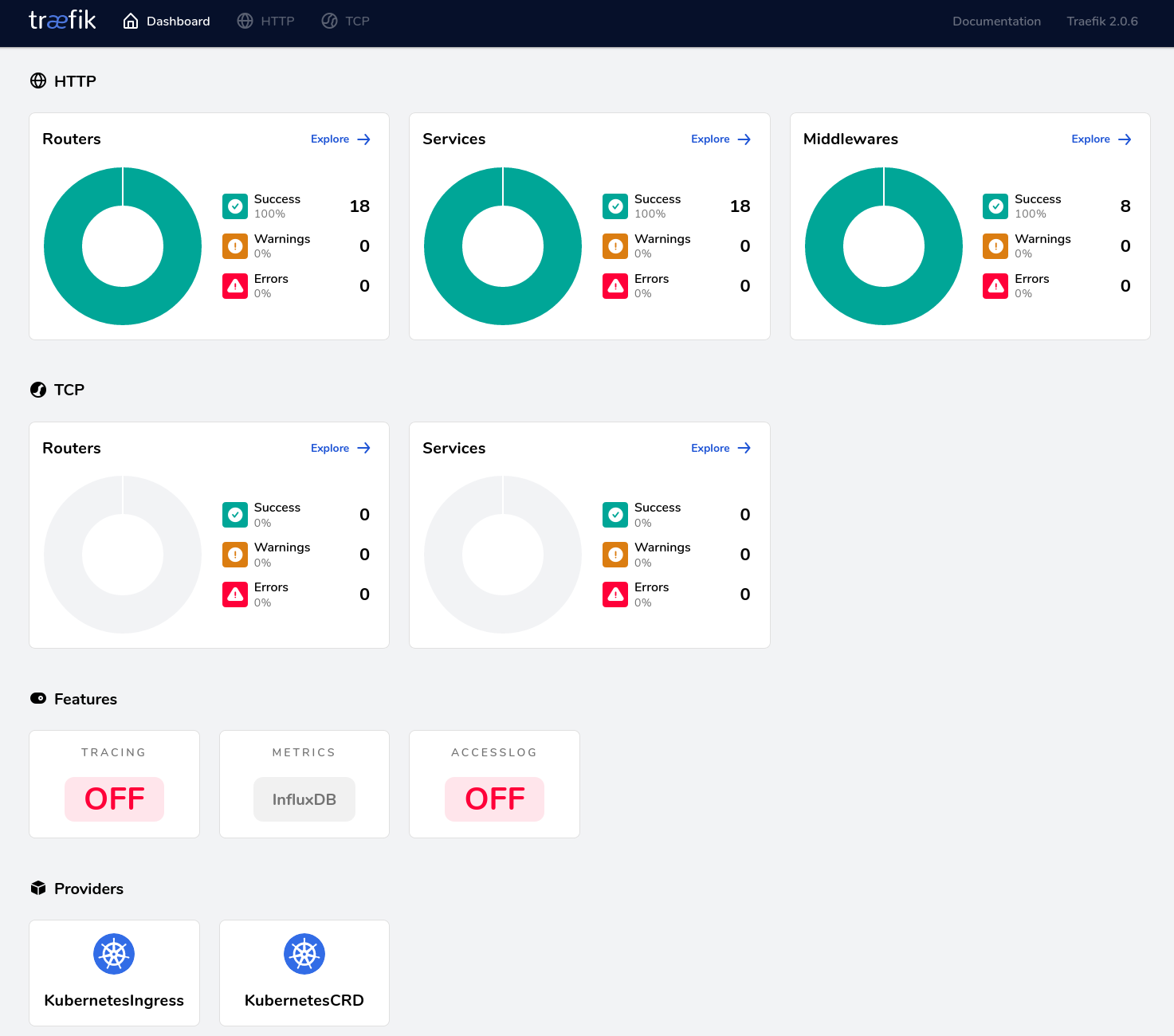
Sur le dashboard Traefik, dans la section “Features”, la boite “Metrics” doit afficher “InfluxDB”, comme ci-dessous :
Vous pouvez alors vous connecter à votre instance InfluxDB pour valider que des données sont bien insérées :
influx
Connected to http://localhost:8086 version 1.7.8
InfluxDB shell version: 1.7.9
> auth
username: traefik
password:
> use traefik
Using database traefik
> show measurements
name: measurements
name
----
traefik.config.reload.lastSuccessTimestamp
traefik.config.reload.total
traefik.entrypoint.connections.open
traefik.entrypoint.request.duration
traefik.entrypoint.requests.total
traefik.service.connections.open
traefik.service.request.duration
traefik.service.requests.total
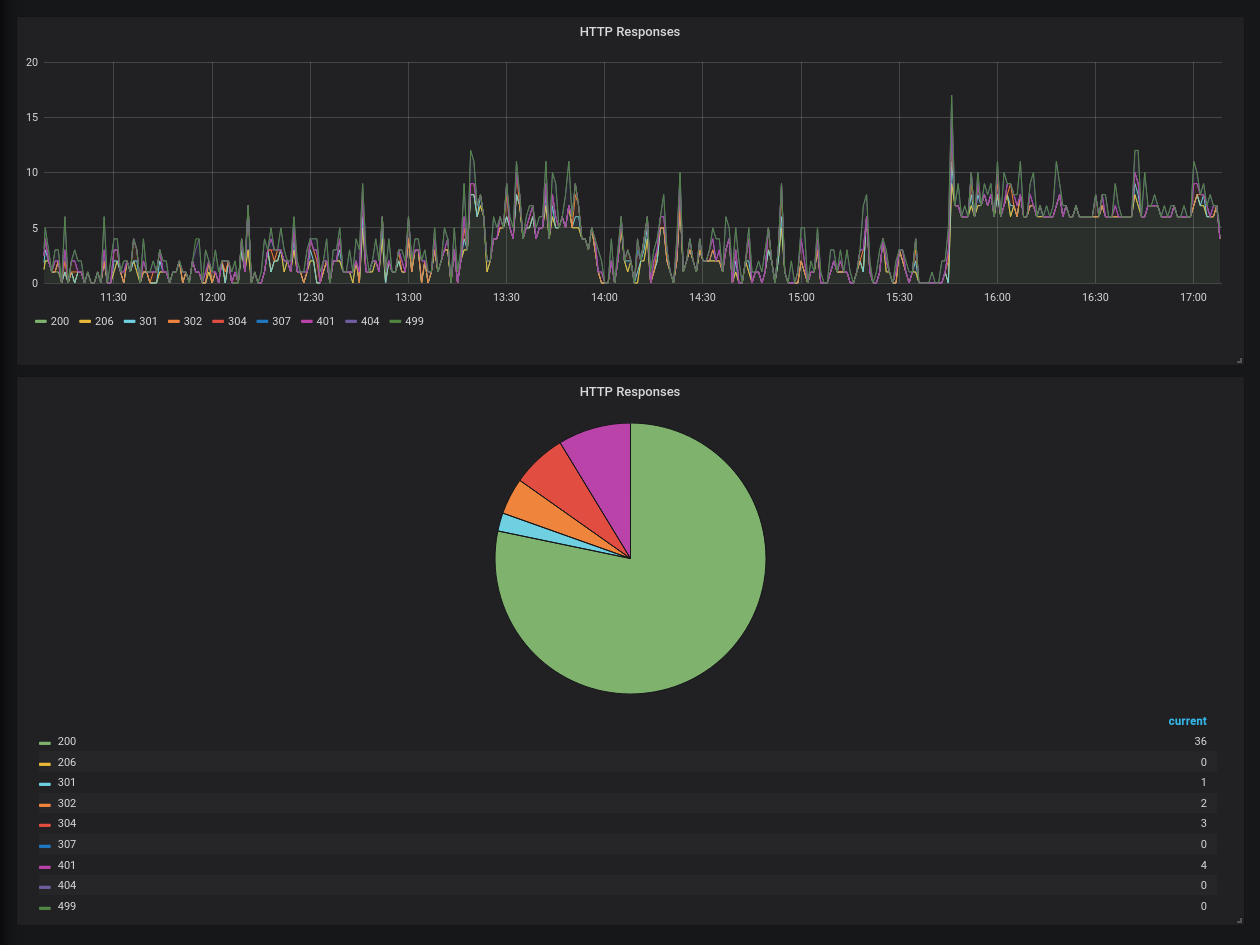
Il ne vous reste plus qu’à utiliser Chronograf ou Grafana pour visualiser vos données et définir des alertes.
Un exemple rapide avec la répartition des codes HTTP dans Grafana :
Web, Ops & Data - Novembre 2019
docker docker-compose docker-hub kubernetes registry quay redhat scanner sécurité helm k3s pod jenkins pipeline redis timeseries machine learning prediction ksql kafka-streamsRendez-vous le 17 décembre prochain à la troisième édition du Paris Time Series Meetup consacré à TSL (billet introductif à TSL : TSL: a developer-friendly Time Series query language for all our metrics) et le module RedisTimeSeries qui apporte des fonctionnalités et des structures Time Seriies à Redis.
Cloud
- The RIPE NCC has run out of IPv4 Addresses : Le RIPE NCC vient d’annoncer avoir attribué son dernier bloc d’IP v4 en /22. La réserve d’IPv4 est donc épuisée mais pour autant cela ne veut pas dire que toutes les IPv4 sont utilisées. Par ailleurs le RIPE NCC précise que de nouveaux blocs devraient voir le jour au fur et à mesure que des organisations revendent des plages inutilisées ou cessent leur activité. Le mécanisme d’attribution se fera alors sous la forme d’une liste d’attente. Ce n’est donc pas l’IPcalypse même si on s’en rapproche de plus en plus et s’il faut prévoir de passer à IPV6 de plus en plus rapidement.
Container et Orchestration
- Red Hat Introduces open source Project Quay container registry : De la même manière que RedHat publie l’upstream d’Ansible Tower avec le projet AWX, RedHat va fournir l’upstream de Quay (registry docker) et Clair (scanner vulnérabilités) sous le nom de Project Quay
- Helm 3.0.0 has been released! : si tout le monde attendait la suppression de tiller, ce n’est pas la seule nouveauté. Le billet donne aussi plein de liens sur la migration vers helm 3, la politique de support de Helm 2 (bug & sécurité pour 6 mois et sécurité uniquement les 6 mois suivants), etc.
- Mirantis acquires Docker Enterprise, Docker Restructures and Secures $35 Million to Advance Developer Workflows for Modern Applications et Docker’s Next Chapter: Advancing Developer Workflows for Modern Apps : Mirantis rachète la branche “Entreprise” de Docker Inc et les actifs associés (employés et propriété intellectuelle). Docker Inc va se focaliser sur l’expérience utilisateur (Docker Desktop, Docker-Compse, Docker-Apps, etc). Pour cela, en plus d’une restructuration du capital, ils ont sécurisé 35 millions de dollars. Il est quand même étonnant de voir qu’à court terme, en dehors de la vente à Mirantis, Docker Inc n’a plus de sources de revenus…
- What Docker Inc’s Reorganization Means For Docker Swarm : Suite à l’annonce précédente, il est légitime de se demander ce que va devenir Swarm. Le produit est donc géré par Mirantis et ces derniers ont embauché la personne en charge de Swarm et lui ont apparemment donné des garanties de pérénité du projet. Il conviendra de rester prudent sur le sujet même si j’espère que le projet Swarm continuera à exister. En effet, il est bien pratique et léger dans beaucoup de cas qui ne requiert pas Kubernetes.
- k3s 1.0 : k3s, la version allégée mais certifiée de k8s atteint la version 1.0. Très pratique pour faire du k8s sur des raspberry pi et assimilés.
- KSS - Kubernetes pod status on steroid : un petit script python qui permet d’avoir un status d’un pod et de son/ses container(s)
Data
- Introducing ksqlDB : Confluent, l’entreprise derrière Apache Kafka et la Confluent Platform sort une nouvelle version de ksql qui est renommé ksqlDB. ksql se voit donc ajouter un connecteur sql pour des enrichissements depuis des sources de données externes, ainsi qu’un système de requêtage dynamiques de topics Kafka pour le présenter sous la forme d’une base de données et prendre en compte les changements au fur et à mesure qu’ils arrivent. Ce n’est donc pas une base de données à proprement parler mais nommer les choses en informatique, c’est une chose compliquée…
Outillage
- Welcome to the Matrix : Le plugin Declarative Pipeline se dote d’une propriété
matrixqui va permettre de faire la même action avec des configurations différentes plutôt que d’avoir un jenkinsfile pour chaque option/déclinaison du job. Le parallelisme semble supporté par défaut et un système d’inclusion/exclusion permet de mieux définir la combinaison des possibles. Dans l’exemple donné qui croise des systèmes d’exploitation et des navigateurs, cela permet par ex de ne pas lancer le job utilisant Micrsoft Edge sous Linux (même si…).
Tech
- Zalando Tech Radar : Zalendo publie son Tech Radar à la ThoughtWorks et open source l’outil de rendu pour que chaque société puisse publie son tech radar
- ThoughtWorks Tech Radar Vol 21 - Nov 2019 : La dernière édition du Tech Radar Thoughtworks en 4 grands axes : techniques, platformes, outils, langages & frameworks. Va falloir lire le PDF pour aller apprécier cette édition.
Time Series
- How to Use Redis TimeSeries with Grafana for Real-time Analytics (version française) : Mise en oeuvre du module RedisTimeSeries et exploitation des données au travers de Grafana.
- Time Series Prediction - A short introduction for pragmatists : une introduction aux différents algorithmes de prévision sur des données temporelles. L’article montre que l’on peut obtenir des résultats assez probants avec des moyens assez simples et sans se comliquer la vie.
- Using Gradient Boosting for Time Series prediction tasks : une autre introduction assez pédagogique à la prédiction basée sur des séries temporelles avec l’outil XGBoost et en appliquant le Gradient Bootsting.
Kubernetes @ OVH - Traefik2 et Cert Manager pour le stockage des certificats en secrets
kubernetes traefik ovh secrets cert-managerAvec la sortie de Traefik 2, il était temps de mettre à jour le billet Kubernetes @ OVH - Traefik et Cert Manager pour le stockage des certificats en secrets pour tenir compte des modifications.
L’objectif est toujours de s’appuyer sur Cert-Manager pour la génération et le stockage des certificats Let’s Encrypt qui seront utilisés par Traefik. L’idée est de stocker ces certificats sous la forme d’un objet Certificate et de ne plus avoir à provisionner un volume pour les stocker. On peut dès lors avoir plusieurs instances de Traefik et non plus une seule à laquelle le volume serait attaché.
Installation de cert-manager :
# Install the CustomResourceDefinition resources separately
kubectl apply --validate=false -f https://raw.githubusercontent.com/jetstack/cert-manager/release-0.11/deploy/manifests/00-crds.yaml
# Create the namespace for cert-manager
kubectl create namespace cert-manager
# Add the Jetstack Helm repository
helm repo add jetstack https://charts.jetstack.io
# Update your local Helm chart repository cache
helm repo update
# Install the cert-manager Helm chart
helm install \
--name cert-manager \
--namespace cert-manager \
--version v0.11.0 \
jetstack/cert-manager
Nous allons ensuite devoir créer un Issuer dans chaque namespace pour avoir un générateur de certificats propre à chaque namespace. Cela est notamment du au fait que Traefik s’attend à ce que le secret et l’ingress utilisant ce secret soient dans le même namespace. Nous spécifions également que nous utiliserons traefik comme ingress pour la génération des certificats.
cert-manager/issuer.yml:
apiVersion: cert-manager.io/v1alpha2
kind: Issuer
metadata:
name: letsencrypt-prod
spec:
acme:
# The ACME server URL
server: https://acme-v02.api.letsencrypt.org/directory
# Email address used for ACME registration
email: user@example.com
# Name of a secret used to store the ACME account private key
privateKeySecretRef:
name: letsencrypt-prod
# Enable HTTP01 validations
solvers:
- selector: {}
http01:
ingress:
class: traefik
Puis créons le “issuer” dans la/les namespace(s) voulu(s) :
# Create issuer in a given namespace
kubectl create -n <namespace> -f cert-manager/issuer.yml
Installons ensuite traefik V2
Créons le namespace traefik2 :
# Create namespace
kubectl create ns traefik2
# Change context to this namespace so that all commands are by default run for this namespace
# see https://github.com/ahmetb/kubectx
kubens traefik2
En premier lieu, Traefik V2 permet d’avoir un provider Kubernetes qui se base sur des Custom Ressources Definition (aka CRD).
Créeons le fichier traefik2/crd.yml :
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: ingressroutes.traefik.containo.us
spec:
group: traefik.containo.us
version: v1alpha1
names:
kind: IngressRoute
plural: ingressroutes
singular: ingressroute
scope: Namespaced
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: middlewares.traefik.containo.us
spec:
group: traefik.containo.us
version: v1alpha1
names:
kind: Middleware
plural: middlewares
singular: middleware
scope: Namespaced
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: ingressroutetcps.traefik.containo.us
spec:
group: traefik.containo.us
version: v1alpha1
names:
kind: IngressRouteTCP
plural: ingressroutetcps
singular: ingressroutetcp
scope: Namespaced
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: ingressrouteudps.traefik.containo.us
spec:
group: traefik.containo.us
version: v1alpha1
names:
kind: IngressRouteUDP
plural: ingressrouteudps
singular: ingressrouteudp
scope: Namespaced
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: tlsoptions.traefik.containo.us
spec:
group: traefik.containo.us
version: v1alpha1
names:
kind: TLSOption
plural: tlsoptions
singular: tlsoption
scope: Namespaced
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: tlsstores.traefik.containo.us
spec:
group: traefik.containo.us
version: v1alpha1
names:
kind: TLSStore
plural: tlsstores
singular: tlsstore
scope: Namespaced
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: traefikservices.traefik.containo.us
spec:
group: traefik.containo.us
version: v1alpha1
names:
kind: TraefikService
plural: traefikservices
singular: traefikservice
scope: Namespaced
Vous pouvez retrouver les sources de ces CRD.
Continuons avec traefik2/rbac.yml - le fichier défini le compte de service (Service Account), le rôle au niveau du cluster (Cluster Role) et la liaison entre le rôle et le compte de service (Cluster Role Binding). Si vous venez d’une installation avec Traefik 1, ce n’est pas tout à fait la même définition des permissions.
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: traefik2-ingress-controller
namespace: traefik2
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: traefik2-ingress-controller
namespace: traefik2
rules:
- apiGroups:
- ""
resources:
- services
- endpoints
- secrets
verbs:
- get
- list
- watch
- apiGroups:
- extensions
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- extensions
resources:
- ingresses/status
verbs:
- update
- apiGroups:
- traefik.containo.us
resources:
- middlewares
- ingressroutes
- traefikservices
- ingressroutetcps
- ingressrouteudps
- tlsoptions
- tlsstores
verbs:
- get
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: traefik2-ingress-controller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: traefik2-ingress-controller
subjects:
- kind: ServiceAccount
name: traefik2-ingress-controller
namespace: traefik2
Nous pouvons alors songer à déployer Traefik V2 sous la forme d’un Deployment. Mais avant de produire le fichier, ce qu’il faut savoir ici :
- lorsque cert-manager fait une demande de certificat, il crée un ressource de type
Ingress. Dès lors, il faut activer les deux providers kubernetes disponibles avec Traefik V2 :KubernetesCRDetKubernetesIngress. Le premier provider permettra de profiter des nouveaux objets fournis par la CRD et le second permet que Traefik gère les Ingress traditionnelles de Kubernetes et notamment celles de cert-manager. - Contrairement à la version 1 de Traefik, le provider
KubernetesIngressne supporte pas les annotations - En activant le provider
KubernetesIngress, on se simplifie aussi la migration d’un socle Traefik V1 vers V2, au support des annotations près.
traefik2/deployment.yml :
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: traefik2-ingress-controller
labels:
k8s-app: traefik2-ingress-lb
spec:
replicas: 2
selector:
matchLabels:
k8s-app: traefik2-ingress-lb
template:
metadata:
labels:
k8s-app: traefik2-ingress-lb
name: traefik2-ingress-lb
spec:
serviceAccountName: traefik2-ingress-controller
terminationGracePeriodSeconds: 60
containers:
- image: traefik:2.1.1
name: traefik2-ingress-lb
ports:
- name: web
containerPort: 80
- name: admin
containerPort: 8080
- name: secure
containerPort: 443
readinessProbe:
httpGet:
path: /ping
port: admin
failureThreshold: 1
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 2
livenessProbe:
httpGet:
path: /ping
port: admin
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 2
args:
- --entryPoints.web.address=:80
- --entryPoints.secure.address=:443
- --entryPoints.traefik.address=:8080
- --api.dashboard=true
- --api.insecure=true
- --ping=true
- --providers.kubernetescrd
- --providers.kubernetesingress
- --log.level=DEBUG
Pour permettre au cluster d’accéder aux différents ports, il faut définir un service via le fichier traefik2/service.yml :
---
kind: Service
apiVersion: v1
metadata:
name: traefik2-ingress-service-clusterip
spec:
selector:
k8s-app: traefik2-ingress-lb
ports:
- protocol: TCP
port: 80
name: web
- protocol: TCP
port: 8080
name: admin
- protocol: TCP
port: 443
name: secure
type: ClusterIP
Et pour avoir un accès de l’extérieur, il faut instancier un load-balancer via le fichier traefik/traefik-service-loadbalancer.yml
---
kind: Service
apiVersion: v1
metadata:
name: traefik-ingress-service-lb
spec:
selector:
k8s-app: traefik2-ingress-lb
ports:
- protocol: TCP
port: 80
name: web
- protocol: TCP
port: 443
name: secure
type: LoadBalancer
Pour donner l’accès au dashboard via une url sécurisée par un certificat Let’s Encrypt, il faut déclarer un Ingress, dans le fichier traefik2/api-ingress.yml :
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: traefik2-web-ui
spec:
entryPoints:
- secure
routes:
- match: Host(`traefik2.k8s.cerenit.fr`)
kind: Rule
services:
- name: traefik2-ingress-service-clusterip
port: 8080
tls:
secretName: traefik2-cert
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: traefik2-web-ui-http
spec:
entryPoints:
- web
routes:
- match: Host(`traefik2.k8s.cerenit.fr`)
kind: Rule
services:
- name: traefik2-ingress-service-clusterip
port: 8080
L’idée est donc de rentre le dashboard accessible via l’url traefik2.k8s.cerenit.fr.
La section tls de l’ingress indique le nom d’hôte pour lequel le certificat va être disponible et le nom du secret contenant le certificat du site que nous n’avons pas encore créé.
Il nous faut donc créer ce certificat :
apiVersion: cert-manager.io/v1alpha2
kind: Certificate
metadata:
name: traefik2-cert
namespace: traefik2
spec:
secretName: traefik2-cert
issuerRef:
name: letsencrypt-prod
commonName: traefik2.k8s.cerenit.fr
dnsNames:
- traefik2.k8s.cerenit.fr
Il ne reste plus qu’à faire pour instancier le tout :
kubectl apply -f traefik2/
Pour la génération du certificat, il conviendra de vérifier la sortie de
kubectl describe certificate traefik2-cert
A ce stade, il nous manque :
- L’authentification au niveau accès
- La redirection https
C’est là que les Middlewares rentrent en jeu.
Pour la redirection https: traefik2/middleware-redirect-https.yml
apiVersion: traefik.containo.us/v1alpha1
kind: Middleware
metadata:
name: https-only
spec:
redirectScheme:
scheme: https
Pour l’authentification : traefik2/middleware-auth.yml
apiVersion: traefik.containo.us/v1alpha1
kind: Middleware
metadata:
name: auth-traefik-webui
spec:
basicAuth:
secret: traefik-auth
Il faut alors créer un secret kubernetes qui contient une variable users contenant la/les ligne(s) d’authentification :
apiVersion: v1
kind: Secret
metadata:
name: traefik-auth
namespace: traefik2
data:
users: |2
dGVzdDokYXByMSRINnVza2trVyRJZ1hMUDZld1RyU3VCa1RycUU4d2ovCnRlc3QyOiRhcHIxJGQ5aHI5SEJCJDRIeHdnVWlyM0hQNEVzZ2dQL1FObzAK
Cela correspond à 2 comptes test/test et test2/test2, encodés en base64 et avec un mot de passe chiffré via htpasswd.
test:$apr1$H6uskkkW$IgXLP6ewTrSuBkTrqE8wj/
test2:$apr1$d9hr9HBB$4HxwgUir3HP4EsggP/QNo0
On peut alors mettre à jour notre fichier traefik2/api-ingress.yml et rajouter les deux middlewares que nous venons de définir :
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: traefik2-web-ui
spec:
entryPoints:
- secure
routes:
- match: Host(`traefik2.k8s.cerenit.fr`)
middlewares:
- name: auth-traefik-webui
kind: Rule
services:
- name: traefik2-ingress-service-clusterip
port: 8080
tls:
secretName: traefik2-cert
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: traefik2-web-ui-http
spec:
entryPoints:
- web
routes:
- match: Host(`traefik2.k8s.cerenit.fr`)
middlewares:
- name: https-only
kind: Rule
services:
- name: traefik2-ingress-service-clusterip
port: 8080
Et pour le prendre en compte:
kubectl apply -f traefik2/
Vous devez alors avoir une redirection automatique vers le endpoint en https et une mire d’authentification.
Pour ceux qui font une migration dans le même cluster de Traefik V1 vers Traefik V2 :
- Si vous avez chaque instance Traefik avec son LoadBalancer et donc son IP dédiée, alors pour que les demandes de certificats ne soient pas interceptées par Traefik V1, il faudra personnaliser l’
ingressClassde Traefik et créer un issuer cert-manager qui utilise cette mêmeingressClass. - Si vous utilisiez les annotations pour générer vos certificats, il vous faut passer par un object
Certificate - Comme dit plus haut, en activant le provider kubernetesIngress, vous pouvez directement migrer sur un socle Traefik v2 puis migrer progressivement vos Ingress vers des IngressRoute. Pas besoin de faire une migration en mode big bang.
Sources utiles:
Web, Ops & Data - Octobre 2019
kafka traefik kubernetes ksql kafka-streams gke anthos helmRendez-vous le 5 Novembre prochain à la seconde édition du Paris Time Series Meetup consacré à QuasarDB pour des cas d’usages autour de la finance et des transports.
Cloud
- The $10m engineering problem : retour d’expérience intéressant sur l’optimisation de sa facture cloud et donc l’accroissement de sa marge opérationnelle.
Container et Orchestration
- What’s Going on with GKE and Anthos? : Si on rapproche ça avec le fait que Google ait gardé le lead sur knative plutôt que de le confier à une fondation, on peut avoir quelques sueurs froides sur le potentiel lock-in ou alors d’une offre k8s à 2 vitesses (GKE tel qu’on le connait actuellement et Anthos GKE avec des fonctionnalités & souscriptions additionnelles…). La seule limite que je vois à ça pour le moment est le fait que Google a vendu k8s comme runtime universel de workload et qu’ils ont besoin de garder cela pour piquer des parts de marché à AWS & Azure…
- Traefik 2.0 with Kubernetes et Advanced Traefik 2.0 with Kubernetes : pas encore implémenté mais a priori tout ce qu’il faut savoir pour passer de Traefik 1.x vers Traefik 2.x sous Kubernetes
- Helm 2.15.0 Released : dernière version stable à apporter des nouveautés a priori avant migration vers la version 3.0. La version 2.x va passer en maintenance (correctifs de bugs & sécurité) et s’éteindra progressivement (6 mois après la release de Helm 3, elle ne prendra que des correctifs de sécurité et fin du support au bout d’un an). En attendant, cette version apporte notamment le paramètre
--output <table|json|yaml>à certaines commandes. Pratique quand on manipule les sorties de Helm dans des scripts… - Comparing Ingress controllers for Kubernetes : une comparaison de 11 Ingress Controller (Nginx, Traefik, Kong, HAProxy, etc) sur une douzaine de fonctionnalités.
(Big) data
- Why I Recommend My Clients NOT Use KSQL and Kafka Streams : la gestion des états et la capacité à pouvoir savoir à quel offset d’un topic kafka reprendre sa consommation peut être un sujet surtout dans le cadre d’une grosse volumétrie qui peut empêcher que le cas de reprendre la consommation du topic depuis son origine. Si Kafka Streams était doté de ce fameux “checkpoint” cela pourrait simplifier la chose. L’autre cas étant sur l’absence de “shuffle sort” utilisé dans des contexte analytiques. Du coup Kafka streams crée des topics supplémentaires pour le besoin et cela peut nuire au bon fonctionnement de votre cluster.
- Change data capture in production with Apache Flink - David Morin & Yann Pauly : un retour d’expérience très riche et très complet sur l’utilisation de Flink chez OVH, les problématiques qu’ils ont rencontré et comment ils ont itéré sur leur pipeline d’ingestion de données. La version française donnée à DataOps.rocks devrait être disponible sous peu.
Paris Time Series Meetup - Edition 2
timeseries quasardb meetup ptsmLe mardi 5 novembre, j’ai le plaisir d’organiser la seconde édition du Paris Time Series Meetup - il reste quelques places, vous pouvez encore vous inscrire et nous rejoindre !
Pour cette séance, nous faisons un focus sur la plateforme de séries temporelles QuasarDB dans des cas d’usages autour de la finance et du transport.
- Talk 1 : “Time Series sans limites avec QuasarDB” : la technologie en mode cloud ou embarquée permet de gérer des cas d’usages « extrêmes » dans des secteurs aussi variés que la Finance de Marché, le Transport ou l’Industrie. Un aperçu des principes de base de la technologie ainsi que de quelques cas d’usage par Jean-Claude TAGGER , COO et co-fondateur et Vianney PLOTTON, ingénieur R&D chez QuasarDB
- Talk 2 : “Véhicules Connectés et Time-Series / Cas d’usage chez un Equipementier Automobile” par Mickaël Gervais (Agaetis)
Cette édition du meetup se déroulera chez Novencia GROUP, en plein centre de Paris.
Retrouvez toutes les informations sur la page de l’événement sur Meetup.
