Un client m’a demandé la chose suivante : “Nicolas, je voudrais savoir la durée pendant laquelle mes équipements sont au delà d’un certain seuil ; je n’arrive pas à le faire simplement”.
Souvent, quand on manipule des séries temporelles, la requête est de la forme “Sur la période X, donne moi les valeurs de tel indicateur”. On a moins l’habitude de travailler dans le sens inverse, à savoir : “Donne moi les périodes de temps pour laquelle la valeur est comprise entre X et Y”.
C’est ce que nous allons chercher à trouver.
Influx 1.8 et InfluxQL
Avec l’arrivée imminente d’Influx 2.0, j’avoue ne pas avoir cherché la solution mais je ne pense pas que cela soit faisable purement en InfluxQL.
Influx 1.8 / 2.0 et Flux
Avec Flux, j’ai rapidement trouvé des fonctions comme duration et surtout stateDuration
L’exemple ci-dessous se fait avec une base InfluxDB 1.8.3 pour laquelle Flux a été activé. Le requêtage se fait depuis une instance Chronograf en version 1.8.5.
Pour approcher l’exemple de mon client, j’ai considéré le pourcentage d’inactivité des CPU d’un serveur que l’on obtient de la façon suivante:
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
Cela donne:

Ensuite, j’ai besoin d’une fonction qui va me rajouter une colonne avec mon état. Cet état est calculé en fonction de seuils - par souci de lisibilité, je vais extraire cette fonction de la façon suivante et appliquer la fonction à ma requête :
set_level = (tables=<-) =>
tables
|> map(fn: (r) => ({
r with
level:
if r._value >= 95 then "fully_idle"
else if r._value >= 90 and r._value <95 then "something_is_moving"
else if r._value >= 85 and r._value <90 then "oh_oh"
else if r._value >= 80 and r._value <85 then "hmm"
else if r._value < 80 then "i_have_to_work"
else "overloaded"
})
)
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
|> set_level()
La colonne “level” n’est à ce stade pas persistée en base contrairement aux autres données issue de la base de données.
Cela donne ceci en mode “raw data” - tout à fait à droite

Maintenant que j’ai mon état, je peux application la fonction stateDuration() ; elle va calculer la périodes de temps où le seuil est “something_is_moving” par tranche de 1 seconde. Le résulat sera stocké dans une colonne “stateDuration”. Pour les autres états, la valeur est de -1. La valeur se remet à 0 à chaque fois que l’état est atteint puis la durée est comptée :
set_level = (tables=<-) =>
tables
|> map(fn: (r) => ({
r with
level:
if r._value >= 95 then "fully_idle"
else if r._value >= 90 and r._value <95 then "something_is_moving"
else if r._value >= 85 and r._value <90 then "oh_oh"
else if r._value >= 80 and r._value <85 then "hmm"
else if r._value < 80 then "i_have_to_work"
else "overloaded"
})
)
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
|> set_level()
|> stateDuration(fn: (r) => r.level == "something_is_moving", column: "stateDuration", unit: 1s)
On voit le rajout de la colonne stateDuration en mode “raw data” ; elle n’ont plus n’est pas persistée dans la base à ce stade :

et coté visualisation :

Maintenant que j’ai ces périodes, je vais vouloir savoir quelle est la durée totale de ces différentes périodes que nous avons identifée. On peut en effet imaginer un cas où on sait que l’équipement est à remplacer lorsqu’il a atteint un seuil donné pendant plus de X heures.
Pour cela, je vais:
- filtrer sur un état voulu,
- calculer le différentiel entre chaque valeur de stateDuration pour n’avoir que les écarts non plus la somme des durées en supprimant les valeurs négatives pour gérer les retours à la valeur 0
- et faire la somme de l’ensemble.
set_level = (tables=<-) =>
tables
|> map(fn: (r) => ({
r with
level:
if r._value >= 95 then "fully_idle"
else if r._value >= 90 and r._value <95 then "something_is_moving"
else if r._value >= 85 and r._value <90 then "oh_oh"
else if r._value >= 80 and r._value <85 then "hmm"
else if r._value < 80 then "i_have_to_work"
else "overloaded"
})
)
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
|> set_level()
|> stateDuration(fn: (r) => r.level == "something_is_moving", column: "stateDuration", unit: 1s)
|> filter(fn: (r) => r.level == "something_is_moving")
|> derivative(unit: 10s, nonNegative: true, columns: ["stateDuration"], timeColumn: "_time")
|> sum(column: "stateDuration")
Ce qui me donne un total de 2230 secondes pour l’heure (3600s) qui vient de s’écouler.

C’est un POC rapide pour démontrer la faisabilité de la chose. Le code est surement améliorable/perfectible.
Dans un contexte InfluxDB 2.0, il y a aussi la fonction events.duration qui semble intéressante. Ce billet “TL;DR InfluxDB Tech Tips – How to Monitor States with InfluxDB” montre aussi l’usage de la fonction monitor.stateChanges() qui peut compléter l’approche.
Influx 1.8 / Flux - variante pour les séries irrégulières
La fonction derivative impose d’avoir des durées régulières pour calculer le delta. Dans le cas d’une série irrégulière, cela peut coincer rapidement et fausser les calculs. On peut donc remplacer les deux dernières lignes par la fonction increase. Elle prend la différence entre deux valeurs consécutives (quelque soit leur timestamp) et réalise une somme cumulative. Les différences négatives sont ignorées de la même façon que nous le faisions précédemment.
set_level = (tables=<-) =>
tables
|> map(fn: (r) => ({
r with
level:
if r._value >= 95 then "fully_idle"
else if r._value >= 90 and r._value <95 then "something_is_moving"
else if r._value >= 85 and r._value <90 then "oh_oh"
else if r._value >= 80 and r._value <85 then "hmm"
else if r._value < 80 then "i_have_to_work"
else "overloaded"
})
)
from(bucket: "crntbackup/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_idle" and r.cpu == "cpu-total")
|> window(every: autoInterval)
|> group(columns: ["_time", "_start", "_stop", "_value"], mode: "except")
|> set_level()
|> stateDuration(fn: (r) => r.level == "something_is_moving", column: "stateDuration", unit: 1s)
|> filter(fn: (r) => r.level == "something_is_moving")
|> increase(columns: ["stateDuration"])
La sortie change un peu car au lieu d’un nombre unique, on a l’ensemble des points filtrés et leur somme au fur et à mesure (colonne de droite):
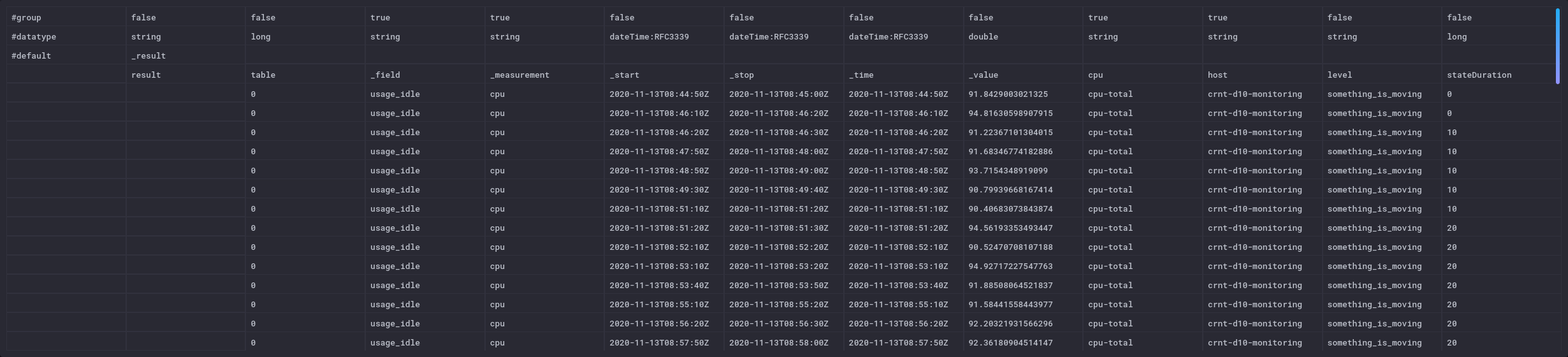
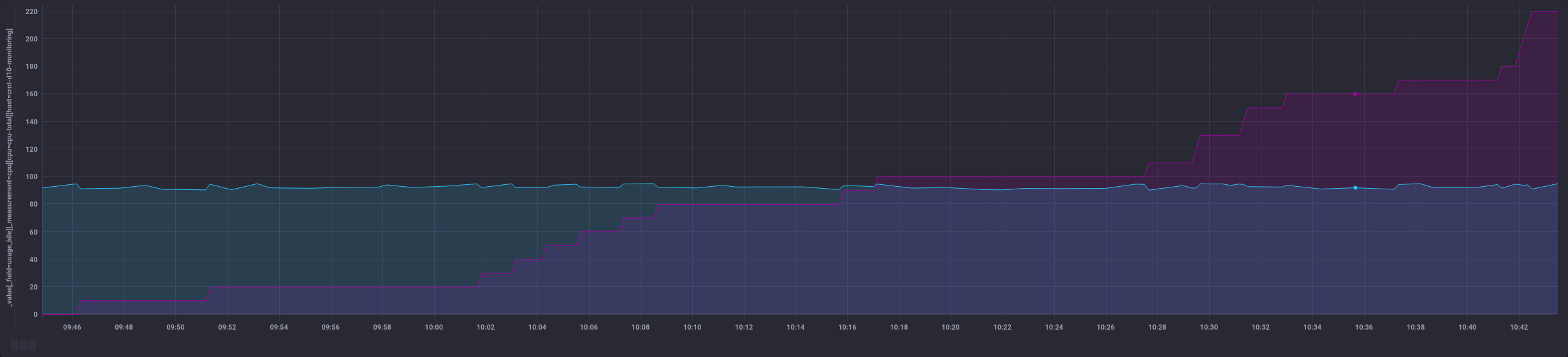
Cela donne des possiblités différentes au niveau dataviz :
Warp 10 / WarpScript
En la même chose en WarpScript avec Warp 10, cela donne quoi ? Regardons cela :
'<readToken>' 'readToken' STORE
// Récupération des données de cpu de type "usage_idle" en ne prenant que le label "cpu-total"
[ $readToken '~crntd10monitoring.cpu.usage_idle' { 'cpu' 'cpu-total' } NOW 1 h ] FETCH
0 GET // Fetch retourne une liste de GTS, on prend donc la première (et unique) GTS
'cpu' STORE // Stockage dans une variable cpu
// Utilisation de BUCKETIZE pour créer une série régulière de données séparées par 1 seconde
// Mes données étant espacées d'environ 10s, cela va donc créer 10 entrées de 1 seconde au final
// Pour chaque espace, on utliise la dernière valeur connue de l'espace en question pour garder les valeurs de la GTS de départ
[
$cpu
bucketizer.last
0
1 s
0
]
BUCKETIZE
// Les espaces insérés n'ont pas encore de valeurs associées
// On remplit les entrées sans valeurs avec les valeurs ci-dessus
// On utilise FILLPREVIOUS et FILLNEXT pour gérer aussi les premières et dernières valeurs
FILLPREVIOUS
FILLNEXT
// A ce stade, on a donc une GTS avec un point toute les secondes et la valeur associée. Cette valeur était la valeur que l'on avait toutes les 10s précédemment.
// On fait une copie de la GTS pour pouvoir comparer avec la version filtrée par ex
DUP
// On filtre sur les valeurs qui nous intéressent, ici on veut les valeurs >= 90 et < 95
[ SWAP 90.0 mapper.ge 0 0 0 ] MAP
[ SWAP 95.0 mapper.lt 0 0 0 ] MAP
// On renomme la liste (pratique si on affiche par ex l'ancienne et la nouvelle liste dans la partie dataviz - cf capture ci-dessous)
'+:above90below95' RENAME
// On compte le nombre d'élément de la GTS qui est sous la forme d'une liste de GTS à l'issu du MAP
0 GET SIZE
// On multiplie le nombre d'entrées par 1 s
1 s *
// on garde une copie de la valeur en secondes
DUP
// On applique le filtre HUMANDURATION qui transforme ce volume de secondes en une durée compréhensible
HUMANDURATION
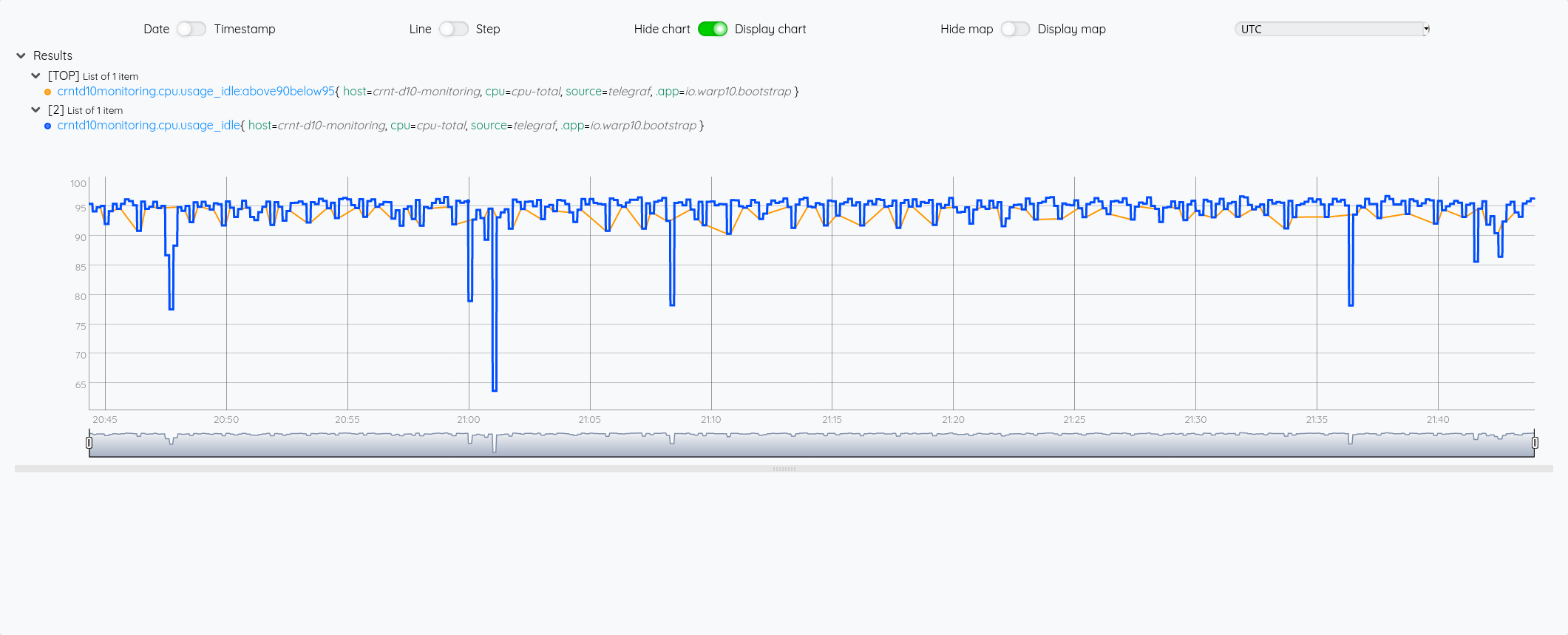
On voit ci-dessous l’usage de DUP avec la valeur humainement lisible, la valeur brute en seconde (puis le reste de la pile):

Si on ne veut pas de dataviz / ne pas conserver les valeurs intermédiaires et n’avoir que la valeur finale, on peut supprimer les lignes avec DUP et RENAME.
'<readToken>' 'readToken' STORE
[ $readToken '~crntd10monitoring.cpu.usage_idle' { 'cpu' 'cpu-total' } NOW 1 h ] FETCH
0 GET
'cpu' STORE
[
$cpu
bucketizer.last
0
1 s
0
]
BUCKETIZE
FILLPREVIOUS
FILLNEXT
[ SWAP 90.0 mapper.ge 0 0 0 ] MAP
[ SWAP 95.0 mapper.lt 0 0 0 ] MAP
0 GET SIZE
1 s *
HUMANDURATION
Et on obtient:
20m20.000000s
Un grand merci à Mathias Herberts pour sa disponiblité, sa patience et son aide face à toutes mes questions pour arriver à produire ce code.
Warp 10 / WarpScript - version agrégée
On peut aussi vouloir avoir une version agrégée de la donnée plutôt que de filter sur un état particulier. Ainsi, on peut avoir la répartition des valeurs que prend un équipement sur un indicateur donnée.
'<readToken>' 'readToken' STORE
// Récupération des métriques comme précédemment
[ $readToken '~crntd10monitoring.cpu.usage_idle' { 'cpu' 'cpu-total' } NOW 1 h ] FETCH
0 GET
'cpu' STORE
// Reformatage des données comme précédemment
[
$cpu
bucketizer.last
0
1 s
0
]
BUCKETIZE
FILLPREVIOUS
FILLNEXT
// Utilisation de QUANTIZE
// QUANTIZE a besoin que l'on définisse des sous-ensembles dans un ensemble
// Notre indicateur CPU étant un pourcentage, on prend par ex 10 sous ensemble compris entre 0 et 100
// QUANTIZE gère aussi les cas où l'on est plus petit que la première valeur et plus grand que la derinère valeur de l'ensemble
0 100 10 LBOUNDS
// On a donc 10+2 = 12 sous-ensembles : ]-infini,0],[1, 10],[11, 20],...,[90, 100],[101, inf+[
// Pour chaque valeur que nous allons passer à QUANTIZE, elle va retourer une valeur associée au sous ensemble dans laquelle la valeur va "tomber".
// Ainsi, un valeur de 95% va aller dans gt90.
// Liste des valeurs pour les 12 sous-ensembles :
[ 'neg' 'gt0' 'gt10' 'gt20' 'gt30' 'gt40' 'gt50' 'gt60' 'gt70' 'gt80' 'gt90' 'gt100' ]
QUANTIZE
// A ce stade, notre GTS de départ ne contient plus les valeurs de cpu mais les valeurs associées au tableau de QUANTIZE
// on passe donc de [<timestamp>, 95.45] à [<timestamp>, 'gt90']
// Utilisation de VALUEHISTOGRAM qui va compter le nombre d'occurences de chaque valeur d'une liste de GTS
VALUEHISTOGRAM
On obtient alors :
[{"gt90":3491,"gt80":40,"gt70":40,"gt60":10}]
Et voilà !