Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Ma comptabilité, une série temporelle comme les autres - partie 5 - Les FEC et le compte 512
warp10 timeseries comptabilité trésorerie banque fecSuite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale
- Partie 4 - Dashboards
- Partie 5 - Les FEC et le compte 512 (ce billet)
- Partie 6 - Les FEC et le compte de résultat
Dans ce cinquième billet, nous allons parler de Fichier d’Ecritures Comptables (FEC) et d’un compte simple à analyser : le compte 512 qui correspond à votre compte en banque.
Le Fichier des Ecritures Comptables (FEC)
Le Fichier des Ecritures Comptables (FEC) est un format de fichier normalisé. Sa spécification est disponible et grosso modo, ce qu’il faut en savoir à ce stade :
- C’est un fichier TSV (un CSV avec les champs séparés par des tabulations)
- Il contient 18 champs permettant de décrire les différentes écritures comptables :
- JournalCode
- JournalLib
- EcritureNum
- EcritureDate
- CompteNum
- CompteLib
- CompAuxNum
- CompAuxLib
- PieceRef
- PieceDate
- EcritureLib
- Debit
- Credit
- EcritureLet
- DateLet
- ValidDate
- Montantdevise
- Idevise
En partant de ces informations et après quelques précisions fournies par mon expert-comptable Fabrice Heuvrard sur le fichier, nous avons convenu de commencer par l’analyse du compte 512 correspondant aux opérations bancaires. Facile à calculer (somme des crédits - somme des débits) et facile à vérifier, il me suffit de regarder mon compte en banque et/ou mon bilan en fin d’année.
Continuant à utiliser Warp 10 pour y stocker mes séries temporelles, j’ai réalisé un script en Go qui prend le fichier FEC en entrée et envoie les données dans Warp 10 avec le formalisme suivant : <société>.<bilan ou resultat>.<classe de compte>.<type d'opération: credit ou debit> :
<société>est juste le début de l’arborescence<bilan ou résultat>: le Plan Comptable Général Francais défini que si les comptes de classe 1 à 5 sont des classes de bilan et les classes 6 et 7 sont des classes de compte de résultat. Je suis donc le même principe de séparation des comptes et défiinr la valeurbilanetresultat. Le compte 512 que nous allons étudier commençant par 5, c’est un compte de bilan. Il sera donc dans la sériecerenit.bilan.*<classe de compte>: le plan comptable général est normalisé sur ces trois premiers chiffres. Les trois suivants sont à la discrétion du comptable. Du coup, pour ne pas avoir une série par code comptable, je retrouve par classe du plan de compte. Ainsi, toutes les opérations ayant le code512xxxse retrouvera dans la sériecerenit.bilan.512.*<type d'opération: crédit ou débit> : suivant si l’opération est un débit ou crédit, cela prend la valeur adéquat. Ainsi, toutes les opérations ayant le code512xxxse retrouvera dans la sériecerenit.bilan.512.creditou ``cerenit.bilan.512.debit`- Le montant de l’écriture comptable sera la valeur associée à mon point dans la série.
- Les autres informations seront mises sous la forme de labels (ie meta données de mon point) pour d’éventuelles analyses ultérieures. Il s’agit de couple clé/valeurs.
Ainsi, un crédit de 100€ avec une référence de pièce à 1234 sera représenté sous la forme :
<Timestamp de l'écriture comptable>// cerenit.bilan.512.credit{PieceRef=1234} 100
La modélisation est peut être un peu naive à ce stade, il sera toujours temps de la faire évoluer dans un second temps mais a priori :
- J’ai ma séparation bilan / compte de résultat
- J’ai ma séparation par classe de compte
- J"ai ma séparation débit / crédit
- au pire via les labels, j’ai des axes complémentaires de recherche / sélection.
Contrôle des données
Avant de commencer la moindre analyse, j’ai voulu vérifier l’intégrité de mes données.
"<readToken>" "readToken" STORE
// Récupération des données de 2020 pour le compte 512
[ $readToken 'cerenit.bilan.512.credit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
// Fusion de l'ensemble des séries temporelles en une seule série
MERGE
// Calcul de la somme de l'ensemle des valeurs de la séries -
// MAXLONG permet de tout récupérer sans calculer la taille exacte de la liste (pour peu que votre liste soit plus petite que la valeur de MAXLONG)
// 1 permet de ne sortir qu'une valeur en sortie
[ SWAP mapper.sum MAXLONG MAXLONG 1 ] MAP
// C'est une liste avec une liste à 1 élément, on "applatit" tout ça
MERGE
VALUES
0 GET
// On stocke la valeur finale dans totalCredit
'totalCredit' STORE
// Même opération sur les débits
[ $readToken 'cerenit.bilan.512.debit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
MERGE
[ SWAP mapper.sum MAXLONG MAXLONG 1 ] MAP
MERGE
VALUES
0 GET
'totalDebit' STORE
// Calcul du solde
$totalCredit $totalDebit -
Cela me donne : 27746.830000000075
Exploration de la trésorerie
"<readToken>" "readToken" STORE
// Récupération des données de 2020 pour le compte 512
[ $readToken 'cerenit.bilan.512.credit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
// Fusion de l'ensemble des séries temporelles en une seule série
MERGE
// Tri des points par date
SORT
// Renommage de la série
'credit' RENAME
// Suppression des labels
{ NULL NULL } RELABEL
// Stockage dans une variable
'credit' STORE
// Même opération sur les débits
[ $readToken 'cerenit.bilan.512.debit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
MERGE
SORT
'debit' RENAME
{ NULL NULL } RELABEL
'debit' STORE
// Affichage des deux séries
$credit
$debit
// Création de la série de mouvements
$credit $debit -
'mouvements' RENAME
Cela nous donne ces courbes:
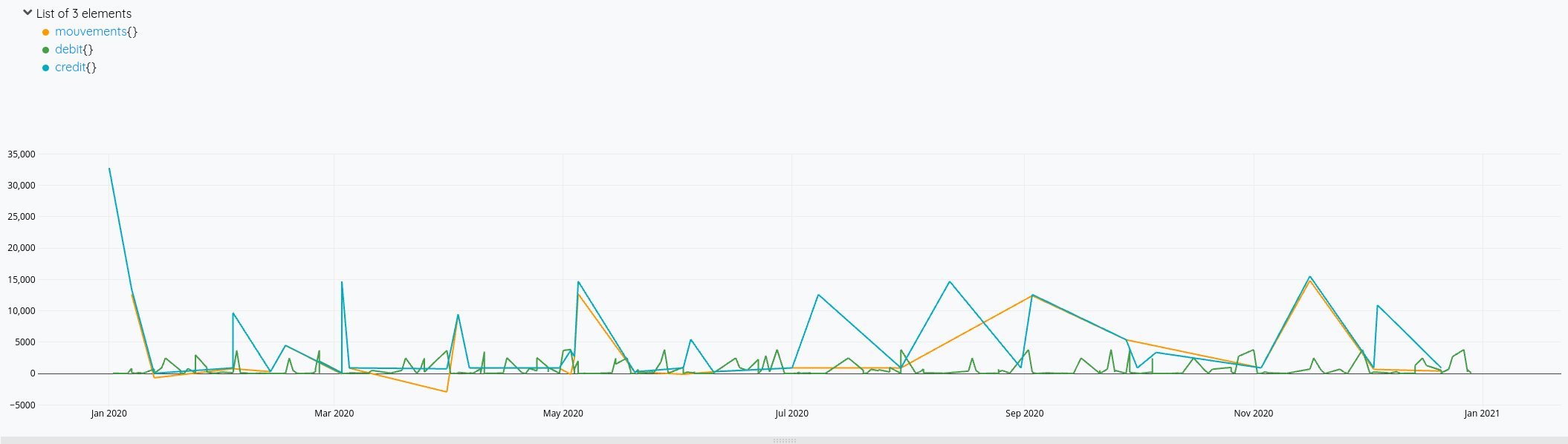
Mais on voit bien à fin décembre qu’il y a des opérations de débit qui ne sont pas prises en compte dans le solde (la ligne orange s’arrête avant la verte).
En cherchant un peu, je me dis qu’il faudrait que je calcule une nouvelle série avec tous les éléments de crédit et débit et faire l’addition de tout cela. Je vois également que FLATTEN (doc)permet de fusionner plusieurs listes en une seule. Mais finalement, seul MERGE sera nécessaire.
Cela me donne la piste suivante :
"<readToken>" "readToken" STORE
// Récupération des données de 2020 pour le compte 512
[ $readToken 'cerenit.bilan.512.credit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
MERGE
SORT
'credit' RENAME
{ NULL NULL } RELABEL
'credit' STORE
// Même opération sur les débits
[ $readToken 'cerenit.bilan.512.debit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
MERGE
SORT
'debit' RENAME
{ NULL NULL } RELABEL
// Je multiplie les debits par -1 pour pouvoir faire l'opération de solde ensuite
[ SWAP -1 mapper.mul 0 0 0 ] MAP
'debit' STORE
// Je fusionne les deux séries avec MERGE
[
$credit
$debit
] MERGE
// Je trie les éléments par date
SORT
'mouvements' RENAME
Cette fois-ci, mon solde prend bien en compte toutes les opérations de l’année.
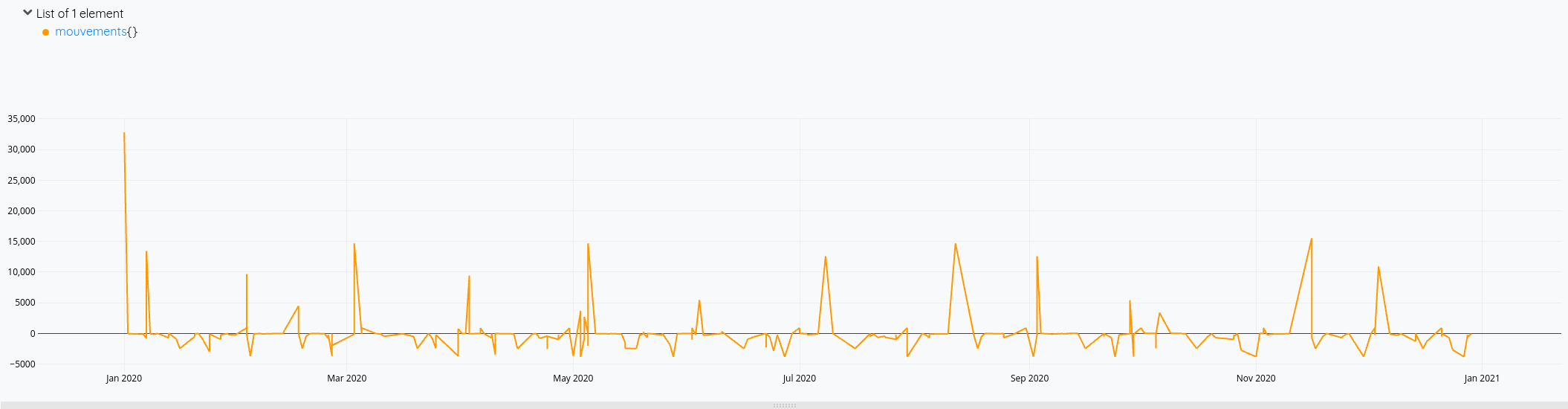
Pour la version consolidée avec le solde du compte :
// Récupération des données de 2020 pour le compte 512
[ $readToken 'cerenit.bilan.512.credit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
MERGE
SORT
'credit' RENAME
{ NULL NULL } RELABEL
'credit' STORE
// Récupération des données de 2020 pour le compte 512
[ $readToken 'cerenit.bilan.512.debit' {} '2020-01-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
MERGE
SORT
'debit' RENAME
{ NULL NULL } RELABEL
-1 *
'debit' STORE
// Fusion des débits/crédits comme vu précédemment
[
$credit
$debit
] MERGE
SORT
'mouvements' RENAME
// On applique mapper.sum sur l'ensemble des points précédents le point qui est considéré
// Le premier point ne va donc prendre que lui même
// Le 2nd point va prendre sa valeur et ajouter celle du précédédent
// Le 3ème point va prendre sa valeur et la somme des points précédents
// Et ainsi de quiste
[ SWAP mapper.sum MAXLONG 0 0 ] MAP
Et le résultat en images :
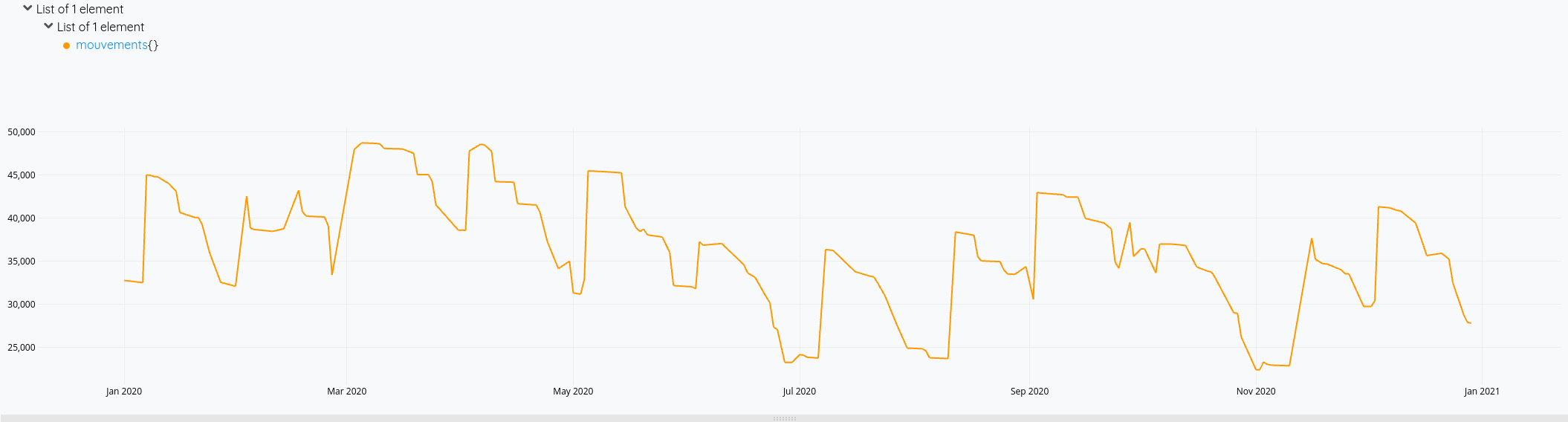
Et voilà !
Il ne me reste plus qu’à :
- ingérer les FEC des autres années pour envisager des comparaisons entre les différents exercices comptables, voire du prédictif pour l’exercice en cours et à venir,
- étendre ces analyses à d’autres comptes maintenant,
- et à créer les dashboards adéquats avec Discovery.
