Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Web, Ops, Data et Time Series - Octobre 2021
postgresql timeseries bi datatask dbt metabase singer timescale influxdb quasardb vector nomad clever-cloud yield pivot warp10 flows vscode kapacitor chronograf telegraf clickhouseBI
- Smart Data Analytics : Exploration des données comptables : pour changer des outils de séries temporelles, je me suis livré au même exercice d’ingestion et de traitement des FEC avec la Smart Data Analytics (SDA) de DataTask. Basée sur singer, dbt et metabase, la SDA permet via une Web UI de définir son flow d’ingestion et de transformation. Une fois ces transformations réalisées, il ne reste plus qu’à explorer les données avec Metabase et produire ses dashboards.
Code
- vscode.dev : l’ère de l’IDE dans le navigateur continue après gitpod ou githuab codspaces, c’est au tour de vscode.dev qui permet d’avoir une IDE dans son navigateur. Affaire à suivre…
Observabilité et monitoring
- Vector 0.17.0, Vector 0.17.1, Vector 0.17.2 & Vector 0.17.3 avec l’adaptive concurrency qui permet de gérer le “back pressure” pour les destinations accessibles via HTTP, et pour les sources une gestion simplifiée pour le décodage d’éléments et leur “framing”.
- Vector Remap Language : extension Vector pour VSCode
Orchestration & conteneurs
- damon, un dashboard pour nomad en ligne de commande.
- Announcing HashiCorp Nomad 1.2 Beta : ajout des “System Batch” qui sont des (petits) jobs globaux au cluster, des améliorations de l’interface et l’ajout des Nomad Pack, une sorte de catalogue d’applications prêtes à être déployées dans votre cluster.
SQL
- PostgreSQL 14 Released! ou en français PostgreSQL 14 ou un thread twitter pour découvrir les nouveautés de cette version : amélioration du support de JSONB, type multirange, fonctions autour des dates, etc.
Sécurité
- Popular NPM library hijacked to install password-stealers, miners : analyse de la librairie ua-parser-js compromise dans ses version 0.7.29, 0.8.0 et 1.0.0 avec l’ajout un mining de crypto et un voleur de mot de passes. Le passage en version 0.7.30 / 0.8.1 et 1.0.1 est à faire dans les plus brefs délais. Pour les dépendances indirectes, il est possible d’ajouter dans son fichier
package.json:"resolutions": { "ua-parser-js": "^0.7.30" }via Security issue: compromised npm packages of ua-parser-js (0.7.29, 0.8.0, 1.0.0) - Questions about deprecated npm package ua-parser-js
Time Series
Annonces & Produits :
- InfluxDB OSS 2.0.9
- InfluxDB OSS 1.8.10
- InfluxDB Entreprise 1.9.5 - avec des fixes sur l’utilisation mémoire et les index TSI :sourire_narquois:
- Telegraf 1.20.2 (avec un fix de memory leak sur le parser influx notamment)
- Kapacitor 1.6.2
- QuasarDB 3.10.0 Stable Released : Nouvelle version de la base QuasarDB avec son lot d’améliorations et de corrections ; pour une présentation de QuasarDB, voir Time Series France - Edition 2 - QuasarDB, les séries temporelles appliquées à la finance & aux transports.
- Announcing the new Timescale Cloud, and a new vision for the future of database services in the cloud et le thread twitter associé : Timescale partage sa vision de ce que doit être une base managée et de la developer experience qu’elle doit offrir. Timescale indique également avoir 3 millions de bases actives par mois (très loin devant les derniers chiffres d’InfluxData ; environ 6 fois mais faut-il encore s’accorder ce qu’est une base: une instance ? un schema ?). Timescale annonce les principes de Timescale Cloud (ex Timescale Forge) qui veut être simple, scalable, connu et flexible. Les deux premiers sont inspirés du monde serverless (découplage compute/storage, auto scalabilité, etc) et les deux derniers du monde de la base de données managiées (du SQL plutôt qu’une API et le fait de bénéficier de tout l’écosystème associé). 10 annonces sont prévues durant le mois d’octobre, quelques-une sont déjà en fin de billet.
- Announcing Time Series on Clever Cloud, with TARDIS, Clever Cloud lance son offre Time Series as a Service, basée sur Warp 10 et avec une compatiblité InfluxQL, PromQL, etc.
- FLoWS ♡ VS Code WarpScript extension 2.0.0 - SenX : nouvelle version de l’extension Warp 10 pour VSCode avec le support de FLoWS et Discovery.
- October 2021: Warp 10 release 2.9.0 : nouvelles capacités (CAPABILITY) autour de fetch & exec, GUARD doit éviter les fuites de données sensibles, ajout support de KML/GML en plus des habituels ajouts de fonctions, améliorations de fonctions et divers corrections de bugs
Articles & Vidéos :
- How NOT to Analyze Time Series : article sympathique sur les erreurs de jeunesse d’analyse de séries temporelles.
- Penser le monde en time series, la nouvelle solution à vos problèmes d’analyse (M.Herberts/Q.Adam) : conférence à DevoxxFR de Quentin et Mathias pour une introduction aux séries temporelles. Intéressant même si un peu au lance pierre sur la fin.
- Les TSDB ne sont pas toujours la bonne solution : approche db ou plateforme ? approche table ou séries ? faible ou forte profondeur d’analyse ? Revue de quelques critères pouvant impacter la façon dont vous manipulez vos séries temporelles.
- TL;DR InfluxDB Tech Tips: Multiple Aggregations with yield() in Flux :
yield()peut être très pratique pour débugguer son code flux mais permet aussi de récupérer le résultat de plusieurs requêtes pour faire des aggrégations - How to Pivot Your Data in Flux: Working with Columnar Data : InfluxDB, contrairement à une RDBMS, stocke ses valeurs via une approche colonne, qui peut dérouter dans un premier temps. Le billet montre comment utiliser
pivot()pour revenir à des manipulations en ligne. - Function pipelines: Building functional programming into PostgreSQL using custom operators : quand un Query Langage (ici SQL) ne suffit plus pour manipuler les séries temporelles, arrivent les fonctions et les opérateurs.
- What is ClickHouse, how does it compare to PostgreSQL and TimescaleDB, and how does it perform for time-series data? : un benchmark très complet pour se faire une opinion et même si ClickHouse n’est pas une TSDB.
Pour le retour sur les InfluxDays North America qui ont lieu cette semaine, ce sera pour un prochain billet ou édition du Time Series France Meetup
Web, Ops & Data - Octobre 2020
kubernetes ingress yaml pipeline gitlab traefik rootless mesh yq jq devops data maturité mariadb s3 flows warp10 timeseries influxdb pulsar amqp mqtt kafka python git vscode arm nvidiaDes nouvelles du Paris Time Series Meetup : l’éditions 6 sur TimescaleDB et l’édition 7 sur QuestDB
CI/CD
- 3 YAML tips for better pipelines : la troisième est certainement la plus intéressante - il est possible d’avoir des mécanismes de “composabilité” / “héritage” avec YAML et Gitlab. Si les
includeetextendssont déjà sympathiques, lesanchorsont l’air de faire des choses intéressantes aussi !
Code
- What’s New In Python 3.9 et un thread twitter qui donne des exemples des principales nouveautés : au programme nouvelle syntaxe pour la fuston des dictionnaires, des méthides pour supprimer des suffixes/préfixes sur les strings, du typage et plein d’autres améliorations et corrections.
- Fortunately, I don’t squash my commits : s’il peut être tentant sur une MR/PR de faire un squash des commits, l’article vous confortera dans l’idée que ce n’est pas une bonne idée. En écrasant l’historique des commits, on y perd sur nos capacités de debug. Par ailleurs, il est conseillé de faire des petits commits pour capturer un ensemble de changements traduisant un moment précis du développement.
Container et orchestration
- Kubernetes Ingress Goes GA : l’apparition de IngressClassName dans k8s 1.19 va plus loin qu’un simple renommage de champ comme je l’avais compris initialement. C’est une vraie ressource et cela ouvre aussi des possibilités. Avant de l’utiliser, vérifiez aussi que vos ingress controller le supporte (en plus d’attendre d’être en 1.19)
- Houston, we have Plugins! Traefik 2.3 Announcement : la version 2.3 dont on a déjà parlé ici, est arrivé en version stable avec son support des plugins, son intégration avec Traefik Pilot, le support d’Amazone ECS et le support de la ressource IngressClassName. Au passage, Containous, la société éditrice de Traefik s’appelle maintenant Traefik Labs.
- Introducing Traefik Pilot 1.0: the Traefik Control Center : Version 1.0 de ce nouveau “Control Plane” de Traefik qui permet d’avoir une vision globale sur ses instances traefik, d’utiliser les plugins et d’avoir un monitoring et des alertes autour de la disponibilité, des performances et de la sécurité.
- Rootless mode : A voir si cela pourra être inclus dans la version 1.20 mais le rootless mode est clairement une tendance de fond dans kubernetes et les conteneurs en général. Si vous ne vous y êtes pas déjà mis, ne tardez pas !
- Announcing Traefik Mesh 1.4 - New Name, New Features : nouvelle version du service mesh par Traefik Labs et qui s’appelle maintenant Traefik Mesh (et non uniquement Maesh). Le reste des améliorations semble porter sur le filtrage des headers et des paths.
- yq : A command line tool that will help you handle your YAML resources better : vous voulez faire des opératoins sur des fichiers YAML sans faire un chart helm ou sortir kustomize, vous pouvez faire des choses minimalistes avec yq (le pendant yaml de jq).
- Bridge to Kubernetes GA, “bridge to kubernetes” est une extension pour vscode permettant de connecter une application tournant en local avec d’autres applications situées dans un ckuster kubernetes et faciliter ainsi l’expérience des développeurs.
Culture DevOps
- La culture de la résilience à travers le DevOps, DevPO, et DevQA : article intéressant de Paul Leclerq sur la résilience et la collaboration au sein d’une équipe.
Data
- How to Measure Your Organization’s Data Maturity : les différents stade de maturité de votre organisation concernant la gestion et l’exploitation des données.
- Announcing MQTT-on-Pulsar: Bringing Native MQTT Protocol Support to Apache Pulsar: Apache Pulsar, la plateforme de message distribué et de streaming, se dote d’un plugin “MQTT On Pulsar” (MoP) permettant ainsi de migrer vos applications MQTT sur Apache Pulsar. Après le plugin Kafka (KoP) il y a quelques mois en partenariat avec OVHCloud, Pulsar ajoute une corde à son arc pour devenir la plateforme universelle. Le protocole AMQP est déjà aussi supporté depuis plusieurs mois.
- Building An Event-Driven Orchestration Engine : retour d’expérience sur les raisons de la migration à Apache Pulsar e la simplificaiton apportée en ayant une platforme riche et complète (streaming + queue + fonctions + data tiering sur S3 + …)
Hardware
- NVidia’s Planned Acquisition of Arm Portends Radical Data Center Changes : une analyse assez en profondeur sur le rachat d’arm par nvidia et les autres acteurs du marché comme AMD.
IaC
- Announcing HashiCorp Terraform 0.14 Beta: la capacité à marquer des variables comme sensibles pour éviter que leur valeur soit visible dans les logs/diff/…, un diff plus concis, un lock sur les providers et des binaires disponibles pour arm64.
Monitoring
- Long-term store for Prometheus, with the combined power of SQL and PromQL : Timescale s’ajoute à la liste des solutions permettant un stockage long terme à vos données Prometheus. En plus de ce stockage long terme, elle fournit une couche d’analytics. Un connecteur récupère les données dans Prometheus et les injecte dans TimescaleDB. On en parle dans l’édition 6 du PTSM.
Pratique
- endoflife.date : recense les dates de fin de support de vos langages et technologies préférées. Tout n’est pas complètement à jour mais cela permet de récupérer rapidement les informations.
SQL
- Exciting and New Features in MariaDB 10.5 : évoqué au mois d’aout, le support de S3 dans MariaDB est disponible en version GA dans la version 10.5. D’autres améliorations existent comme le support du type INET6, des améliorations sur ColumnStore, la gestion des privilèges, le cluster Galera supporte complètement le GTID, du refactoring au niveau d’InnoDB et enfin les binaires mariadb vont enfin s’appeler mariadb et non plus mysql (avec une couche de compatibilité via des liens symboliques)
Time Series
- Introducing FLoWS, a functional language for Time Series Analytics : FLoWS est arrivé - il vous faudra utiliser une version 2.7.1+ de Warp10 pour profiter de cette approche fonctionnelle en alternative à Warpscript.
- How can you tell which Time Series Database is suited to your needs? : un petit rappel sur les critères à prendre en compte pour choisir une base de données séries temporelles ; j’avais déjà parlé du guide de Senx sur le sujet - il est disponible en fin de billet.
- InfluxDB 2.0 Release Candidate Now Available : la première Relese Candidate (RC0) pour InfluxDB 2.0 OSS avec le retour du moteur de stockage de la V1 - qui contrairement à ce que j’ai pu dire le mois dernier ne concernerait que la façon dont les données sont stockées sur disque et pas le reste d’une part et sera maintenu et amélioré par Influxdata d’autre part. Quelques changements sur le port (retour au port 8086). Pour ceux qui étaient en version alpha/beta, il faudra suivre une procédure de migration. La migration depuis une version 1.x n’est pas encore disponible, cela devrait être dans une prochaine RC. Vous pourrez tester néanmoins les API 1.x, les templates, une version récente de Flux ou encore les améliorations de la CLI.
- Release Announcement: InfluxDB 2.0.0 RC 1 : cette version apporte essentiellement l’upgrade des données 1.x vers 2.x et une mise à jour de Flux.
- Store and Access Time Series Data at Any Scale with Amazon Timestream – Now Generally Available - Getting Started with Amazon Timestream - AWS Releases Amazon Timestream into General Availability : AWS sort enfin son produit orienté time series après l’avoir annoncé il y a deux ans.
Sur la base des informations disponibles pour le moment :
- vous définissez une période de rétention en mémoire (entre 1h et 1 an) et une période de rétention sur stockage magnétique (1 jour à 200 ans),
- le requêtage des données se fait en SQL (via Presto ?),
- les données à requêter communément sont à mettre dans la même table,
- le join est limité à la même table,
- des mesures simples (pas de multi mesures pour un même enregistrement),
- une intégration avec l’écosystème comme telegraf, grafana, etc en plus de l’intégration avec différents composants AWS
Pour les moins bons côtés :
- pas d’UPDATE/DELETE sur vos données ; en cas de doublons, c’est le premier arrivé qui gagne
- pas de bulk import de vos données, donc pas de reprise de vos données existantes. En effet, il n’est pas possible d’ingérer des données plus vieille que la période en mémoire,
- dans la même veine, si un incident de production dépasse votre période de rétention, vous ne pourrez pas réinjecter vos données
- il ne semble pas possible de mettre à jour ses durées de rétention - donc pas de ménage possible ou d’ajustements en cours de route
Une solution a priori très orienté pour du monitoring et qui semble souffir des mêmes travers qu’InfluxDB avec InfluxQL et pourtant en passe d’être résolus avec Flux.
On devrait en parler plus en détail dans une prochaine édition du Paris Time Series Meetup avec des personnes de chez AWS ;-)
Work
- Virtual First Toolkit : toolkit proposé par Dropbox dans le cadre de leur passage non pas à Remote first mais à virtual first.
Warp 10 - Interactions avec une instance InfluxDB - FLoWS edition
warp10 timeseries influxdb warpscript warpfleet flowsMaintenant que FLoWS est officiellement disponible, je vous propose de revisiter l’article de la semaine dernière Warp 10 - Interactions avec une instance InfluxDB en utliisant FLoWS à la place de WarpScript pour se faire une idée.
Pré-requis: warpfleet
Installons déjà warpfleet, le gestionnaire de package conçu pour Warp 10.
# Installation de npm
sudo dnf install -y npm
# installation de warpfleet
sudo npm install -g @senx/warpfleet
# Vérification de la bonne installation de warpfleet
wf version
___ __ _______________ _____
__ | / /_____ __________________ ____/__ /___________ /_
__ | /| / /_ __ `/_ ___/__ __ \_ /_ __ /_ _ \ _ \ __/
__ |/ |/ / / /_/ /_ / __ /_/ / __/ _ / / __/ __/ /_
____/|__/ \__,_/ /_/ _ .___//_/ /_/ \___/\___/\__/
/_/ ™
version: 1.0.31
1.0.31
Installation de l’extension warp10-ext-influxdb
Sans trop rentrer dans les détails de warpfleet, il utilise un système de namespace appelés “Groups” pour ces packages et qui permettent de définir ses propres dépots. Pour l’extension warp10-ext-influxdb, le “group” est io.warp10.
Ce qui pour l"installation donne la commande suivante :
# Si votre utilisateur n'a pas accès à /path/to/warp10, il vous faudra utiliser sudo
(sudo) wf g -w /path/to/warp10 io.warp10 warp10-ext-influxdb
warpfleet va vous demander quelle version de l’extension vous souhaitez puis va procéder à son téléchargement et son installation.
Cela donne :
sudo wf g -w /opt/warp10 io.warp10 warp10-ext-influxdb
___ __ _______________ _____
__ | / /_____ __________________ ____/__ /___________ /_
__ | /| / /_ __ `/_ ___/__ __ \_ /_ __ /_ _ \ _ \ __/
__ |/ |/ / / /_/ /_ / __ /_/ / __/ _ / / __/ __/ /_
____/|__/ \__,_/ /_/ _ .___//_/ /_/ \___/\___/\__/
/_/ ™
version: 1.0.31
? Which revision do you want to retrieve? latest
✔ ext io.warp10:warp10-ext-influxdb#1.0.1-uberjar retrieved
✔ Download successful: gradle-wrapper.jar
✔ Download successful: gradle-wrapper.properties
✔ Download successful: gradlew
✔ Download successful: gradlew.bat
✔ Dependency warp10-ext-influxdb-1.0.1-uberjar.jar successfully deployed
✔ Done
Note: Pour éviter un bug dans la fonction INFLUXDB.UPDATE identifié lors de la rédaction de ce billet, assurez-vous d’avoir une version >= 1.0.1
Ensuite, il faut créer le fichier /path/to/warp10/etc/conf.d/90--influxdb-extension.conf et y ajouter la ligne suivante:
warpscript.extension.influxdb = io.warp10.script.ext.influxdb.InfluxDBWarpScriptExtension
Je préfère créer un fichier plutôt que d’éditer un fichier existant pour le suivi des mises à jour et j’ai utilisé le prefix 90 car il n’est pas utilisé par les fichiers de Warp10.
Relancer ensuite Warp 10 pour que le plugin soit chargé au démarrage de l’instance :
(sudo) /path/to/warp10/bin/warp10-standalone.init restart
Dans /path/to/warp10/logs/warp10.log, vous devriez voir apparaitre :
2020-09-17T10:59:23,742 main INFO script.WarpScriptLib - LOADED extension 'io.warp10.script.ext.influxdb.InfluxDBWarpScriptExtension'
Installation de FLoWS
Assurez-vous d’avoir préalablement une version >= 2.7.1 de Warp 10
sudo wf g -w /opt/warp10 io.warp10 warp10-ext-flows
___ __ _______________ _____
__ | / /_____ __________________ ____/__ /___________ /_
__ | /| / /_ __ `/_ ___/__ __ \_ /_ __ /_ _ \ _ \ __/
__ |/ |/ / / /_/ /_ / __ /_/ / __/ _ / / __/ __/ /_
____/|__/ \__,_/ /_/ _ .___//_/ /_/ \___/\___/\__/
/_/ ™
version: 1.0.31
? Which revision do you want to retrieve? latest
✔ ext io.warp10:warp10-ext-flows#0.1.0-uberjar retrieved
✔ Download successful: gradle-wrapper.jar
✔ Download successful: gradle-wrapper.properties
✔ Download successful: gradlew
✔ Download successful: gradlew.bat
✔ Dependency warp10-ext-flows-0.1.0-uberjar.jar successfully deployed
warpscript.extension.flows = io.warp10.ext.flows.FLoWSWarpScriptExtension
? Choose what you want to add (Press <space> to select, <a> to toggle all, <i> to invert selection)warpscript.extension.flows = io.warp10.ext.flows.FLoWSWarpScriptExtension
✔ warpscript.extension.flows = io.warp10.ext.flows.FLoWSWarpScriptExtension added to /opt/warp10/etc/conf.d/io.warp10-warp10-ext-flows.conf
✔ Done
Relancer ensuite Warp 10 pour que le plugin soit chargé au démarrage de l’instance :
(sudo) /path/to/warp10/bin/warp10-standalone.init restart
Dans /path/to/warp10/logs/warp10.log, vous devriez voir apparaitre :
2020-10-08T10:59:51,288 main INFO script.WarpScriptLib - LOADED extension 'io.warp10.ext.flows.FLoWSWarpScriptExtension'
Préalable sur FLoWS
FLoWS ne dispose pas encore d’un endpoint /flows ; nous continuons donc à utiliser les “endpoints historiques warpscript compatibles”.
Ce qui nous amène à réaliser une seule action en RPN/NPI (Notation Polonaise Inversée) lorsque l’on soumet du code FLoWS à Warp 10 :
# Multiligne WarpScript qui permet de mettre son code FLoWS
<'
... Code FLoWS ...
'>
# Applique la fonction FLOWS au code ci-dessus
FLOWS
Pour les types, les notations, etc - je voue renvoie au billet de blog introduisant FLoWS.
Requêtage d’une instance InfluxDB 1.x
La semaine dernière nous écrivions en WarpScript :
# Requête INFLUXQL et informations de connection à InfluxDB 1.X
{ 'influxql' "select * from cpu where host=%27myHost%27 and time > now() - 1h" 'db' "myDatabase" 'password' "myPassword" 'user' "myUser" 'url' "http://url.to.influxdb:8086" }
INFLUXDB.FETCH
# On récupère une liste de liste de séries GTS. Il n'y a qu'un seul élément dans cette liste. Nous le prenons pour n'avoir plus qu'une liste de séries GTS.
0 GET
# Sauvegarde de la liste dans une variable cpu
'cpu' STORE
# Affichage de la liste de GTS
$cpu
Cette semaine, nous écrivons en FLoWS :
<'
# Récupération de la liste de GTS
cpu_fetch = INFLUXDB.FETCH({'influxql':'select * from cpu where host=%27myHost%27 and time > now() - 1h', 'db':'myDatabase', 'password':'myPassword', 'user':'myUser', 'url':'http://url.to.influxdb:8086'})
# Récupération de la GTS en prenant l'index 0 de la liste
cpu = GET(cpu_fetch, 0)
# Affichage de la liste de GTS
return cpu
'>
FLOWS
On peut déjà noter :
- la lecture du code correspond plus à nos habitudes dans les autres lanagage
- les fonctions ont les mêmes noms, leur signature ne change pas non plus
- le mot clé
returnest nouveau ici et permet d’afficher la GTS dans le studio par ex. - les tableaux (MAP) sont plus lisibles (arguments séparés par des virugules, la clé et la valeur sont séparés par deux points) et moins sources d’erreurs (gestion des espaces plus sensibles en WarpScript)
Le résultat est identique :
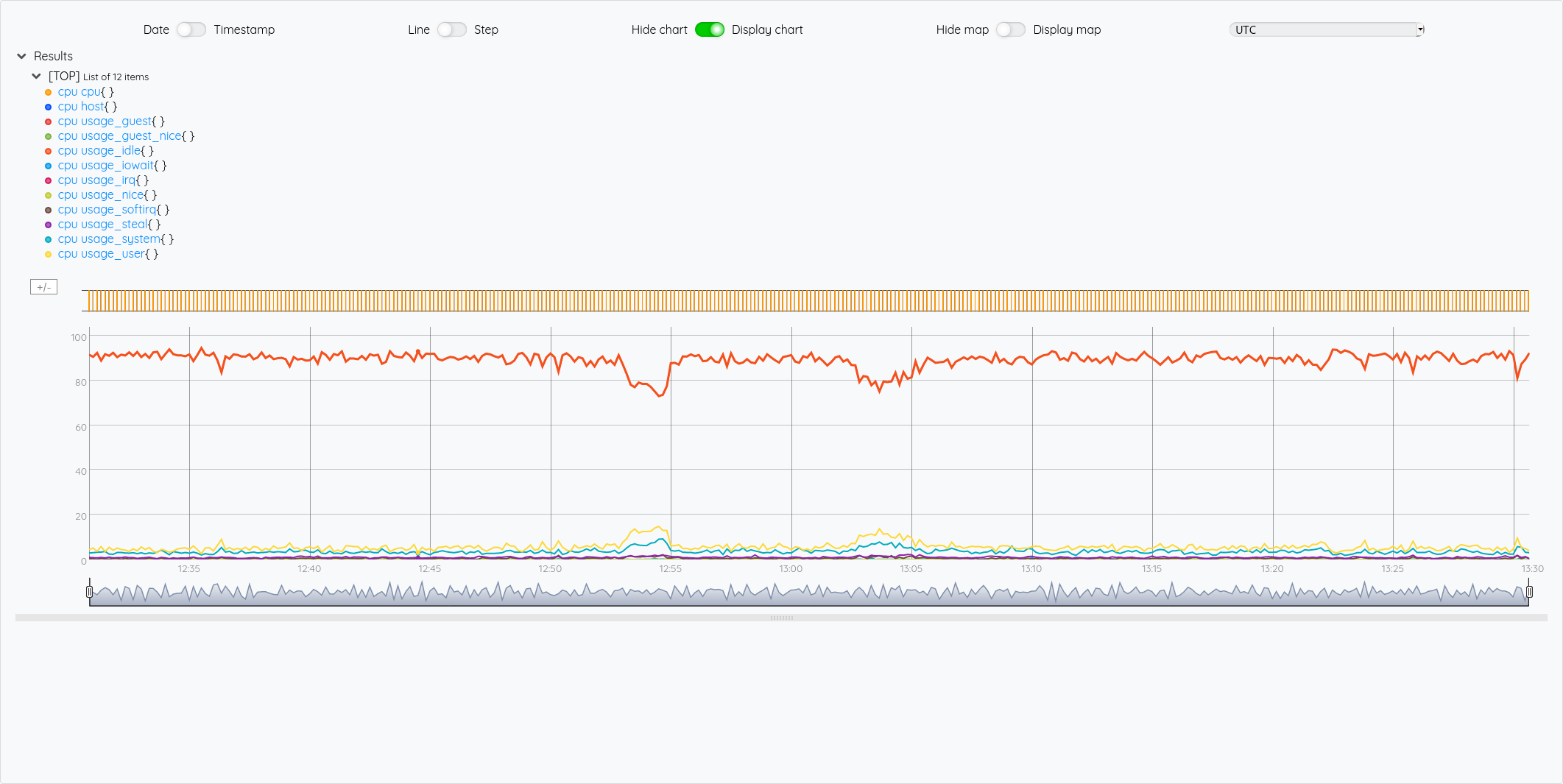
Pour illustrer cette liste de liste de GTS, si on veut récupérer la GTS du cpu idle, on voit dans le graphique que c’est la 5ème courbe, donc un indice 4.
En WarpScript :
{ 'influxql' "select * from cpu where host=%27myHost%27 and time > now() - 1h" 'db' "myDatabase" 'password' "myPassword" 'user' "myUser" 'url' "http://url.to.influxdb:8086" }
INFLUXDB.FETCH
0 GET
'cpu' STORE
# Récupération de la 5ème liste (indice 4)
$cpu 4 GET
En FLoWS :
<'
cpu_fetch = INFLUXDB.FETCH({'influxql':'select * from cpu where host=%27myHost%27 and time > now() - 1h', 'db':'myDatabase', 'password':'myPassword', 'user':'myUser', 'url':'http://url.to.influxdb:8086'})
cpu = GET(cpu_fetch, 0)
# Récupération de la 5ème liste (indice 4)
# on pourrait écrire : return GET(cpu, 4) mais on peut aussi écrire de façon plus concise :
return cpu[4]
'>
FLOWS
Requêtage d’une instance InfluxDB 2.x
La semaine dernière, nous écrivions en WarpScript :
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
<'
from(bucket: "crntbackup")
|> range(start: -1h, stop: now())
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> aggregateWindow(every: 1s, fn: mean, createEmpty: false)
|> yield(name: "mean")
'>
'fluxquery' STORE
# Paramètres de la fonction INFLUX.FLUX avec la requête flux (la variable fluxquery) et les informations de connection à InfluxDB 2.x
{ 'flux' $fluxquery 'org' "myOrganisation" 'token' "myToken" 'url' "http://url.to.influxdb2:9999" }
INFLUXDB.FLUX
# Sauvegarde de la liste dans une variable cpu
'cpu' STORE
# Affichage de la liste de GTS
$cpu
En FLoWS :
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
<'
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
fluxquery = 'from(bucket: "crntbackup")
|> range(start: -1h, stop: now())
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> aggregateWindow(every: 1s, fn: mean, createEmpty: false)
|> yield(name: "mean")'
# Paramètres de la fonction INFLUX.FLUX avec la requête flux (la variable fluxquery) et les informations de connection à InfluxDB 2.x
params = {'flux':fluxquery, 'org':'myOrganisation', 'token':'myToken', 'url':'http://url.to.influxdb2:9999' }
# Sauvegarde de la liste dans une variable cpu
cpu = INFLUXDB.FLUX(params)
# Affichage de la liste de GTS
return cpu
'>
FLOWS
On obtient :
Si on veut comme précédemment avec InfluxQL afficher la courbe du CPU idle.
En WarpScript :
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
<'
from(bucket: "crntbackup")
|> range(start: -1h, stop: now())
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> aggregateWindow(every: 1s, fn: mean, createEmpty: false)
|> yield(name: "mean")
'>
'fluxquery' STORE
# Paramètres de la fonction INFLUX.FLUX avec la requête flux (la variable fluxquery) et les informations de connection à InfluxDB 2.x
{ 'flux' $fluxquery 'org' "myOrganisation" 'token' "myToken" 'url' "http://url.to.influxdb2:9999" }
INFLUXDB.FLUX
# Sauvegarde de la liste dans une variable cpu
'cpu' STORE
# Affiche la 7eme liste (incide 6)
$cpu 6 GET
En FLoWS :
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
<'
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
fluxquery = 'from(bucket: "crntbackup")
|> range(start: -1h, stop: now())
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> aggregateWindow(every: 1s, fn: mean, createEmpty: false)
|> yield(name: "mean")'
# Paramètres de la fonction INFLUX.FLUX avec la requête flux (la variable fluxquery) et les informations de connection à InfluxDB 2.x
params = {'flux':fluxquery, 'org':'myOrganisation', 'token':'myToken', 'url':'http://url.to.influxdb2:9999' }
# Sauvegarde de la liste dans une variable cpu
cpu = INFLUXDB.FLUX(params)
# Affiche la 7eme liste (incide 6)
return cpu[6]
'>
FLOWS
Sauvegarder des données dans InfluxDB
La semaine dernière, nous écrivions en WarpScript :
'<read_token>' 'readToken' STORE
'<write_token>' 'writeToken' STORE
# Récupération des dépenses sous la forme d'une série (GTS)
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
# Récupération du chiffre d'affaires mensuel sous la forme d'une série (GTS)
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
# Calcul du résulat mensuel
$revenue $exp -
# Stockage de la série obtenue dans une série appelée "result"
"result" RENAME
{ "company" "cerenit" } RELABEL
$writeToken UPDATE
# Récupération du résultat mensuel sous la forme d'une série (GTS)
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
# Version 1.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' true 'url' "http://url.to.influxdb:8086" 'measurement' "result" 'db' "crntcompta" 'password' "myPassword" 'user' "myUser" }
'params' STORE
# Utilisatoin de la fonction INFLUXDB.UPDATE qui prend la variable 'params' pour les paramètres de connection et une GTS ou liste de GTS pour les données à sauvegarder
$result $params INFLUXDB.UPDATE
# Version 2.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' false 'url' "http://url.to.influxdb:9999" 'measurement' "result" 'bucket' "crntcompta" 'token' "myToken" 'org' "myOrganisation" }
'params' STORE
$result $params INFLUXDB.UPDATE
En FLoWS, cela donne :
<'
# Gestion des tokens de lecture et écriture
readToken = '<read_token>'
writeToken = '<write_token>'
# Récupération de la liste de GTS dans Warp 10
expense_fetch = FETCH([readToken, 'expense', {'company':'cerenit'}, '2016-12-01T00:00:00Z', '2020-06-01T00:00:00Z'])
# On n'a toujours qu'une liste à 1 élement, on récupère donc la GTS en prenant l'index 0 de la liste
expense = expense_fetch[0]
# Même logique pour le chiffre d'affaires
revenue_fetch = FETCH([readToken, 'revenue', {'company':'cerenit'}, '2016-12-01T00:00:00Z', '2020-06-01T00:00:00Z'])
revenue = revenue_fetch[0]
# On calcule la résultat en faisant la différence entre les 2 GTS revenue et expense
r = revenue - expense
# la GTS obtenue n'ayant pas de nom, on lui en fournit un
RENAME(r, 'result')
# On ajoute les labels manquants
RELABEL(r, {"company":"cerenit"})
# On persiste la GTS dans Warp 10
UPDATE(r, writeToken)
# On récupère la contenu de la GTS result sur le même modèle que revenue et expense précédemment
result_fetch = FETCH([readToken, 'result', {'company':'cerenit'}, '2016-12-01T00:00:00Z', '2020-06-01T00:00:00Z'])
result = result_fetch[0]
# InfluxDB 1.X
# Définition des paramètres de connection
params = {'v1':true, 'url':"http://url.to.influxdb:8086", 'measurement':"result", 'db':"crntcompta", 'password':"myPassword", 'user':"myUser"}
# Persistance des données dans InfluxDB 1.x
INFLUXDB.UPDATE(result, params)
# InfluxDB 2.X
# Définition des paramètres de connection
params = {'v1':false, 'url':"http://url.to.influxdb:9999", 'measurement':"result", 'bucket':"crntcompta", 'token':"myToken", 'org':"myOrganisation" }
# Persistance des données dans InfluxDB 2.x
INFLUXDB.UPDATE(result, params)
'>
# Fin du code FLoWS
# Application de la fonction FLOWS à notre ensemble de code
FLOWS
Coté InfluxDB, on retrouve bien nos données :
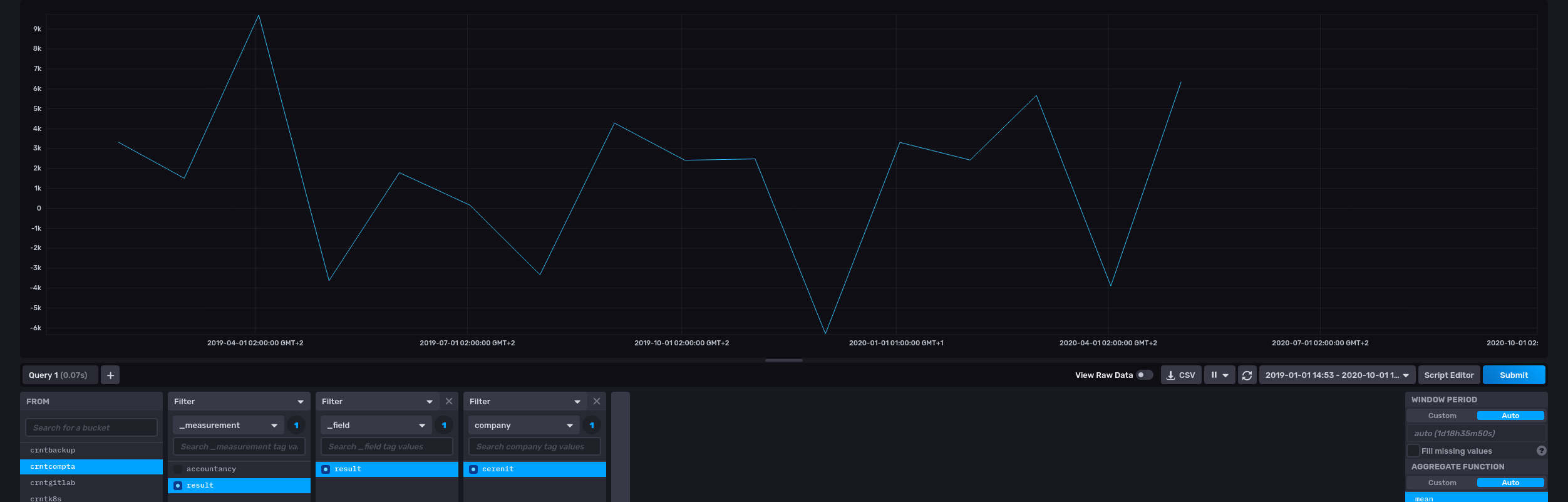
Si au contraire, je veux regrouper plusieurs valeurs dans un même measurement InfluxDB, il faut passer une liste de GTS à INFLUXDB.UPDATE.
La semaine dernière, nous écrivions en WarpScript :
# Version 1.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' true 'url' "http://url.to.influxdb:8086" 'measurement' "accountancy" 'db' "crntcompta" 'password' "myPassword" 'user' "myUser" }
'params' STORE
# Passage d'une liste de GTS plutôt qu'une seule série de l'expemple précédent
[ $result $revenue $exp ] $params INFLUXDB.UPDATE
# Version 2.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' false 'url' "http://url.to.influxdb:9999" 'measurement' "accountancy" 'bucket' "crntcompta" 'token' "myToken" 'org' "myOrganisation" }
'params' STORE
# Passage d'une liste de GTS plutôt qu'une seule série de l'expemple précédent
[ $result $revenue $exp ] $params INFLUXDB.UPDATE
Cette semaine en FLoWS :
# InfluxDB 1.X
# Définition des paramètres de connection
params = {'v1':true, 'url':'http://url.to.influxdb:8086', 'measurement':'result', 'db':'crntcompta', 'password':'myPassword', 'user':'myUser'}
# Persistance des données dans InfluxDB 1.x en passant une liste de GTS
INFLUXDB.UPDATE([result, revenue, expense], params)
# InfluxDB 2.X
# Définition des paramètres de connection
params = {'v1':false, 'url':'http://url.to.influxdb:9999', 'measurement':'result', 'bucket':'crntcompta', 'token':'myToken', 'org':'myOrganisation' }
# Persistance des données dans InfluxDB 2.x en passant une liste de GTS
INFLUXDB.UPDATE([result, revenue, expense], params)
'>
FLOWS
Coté InfluxDB, on retrouve bien nos données :
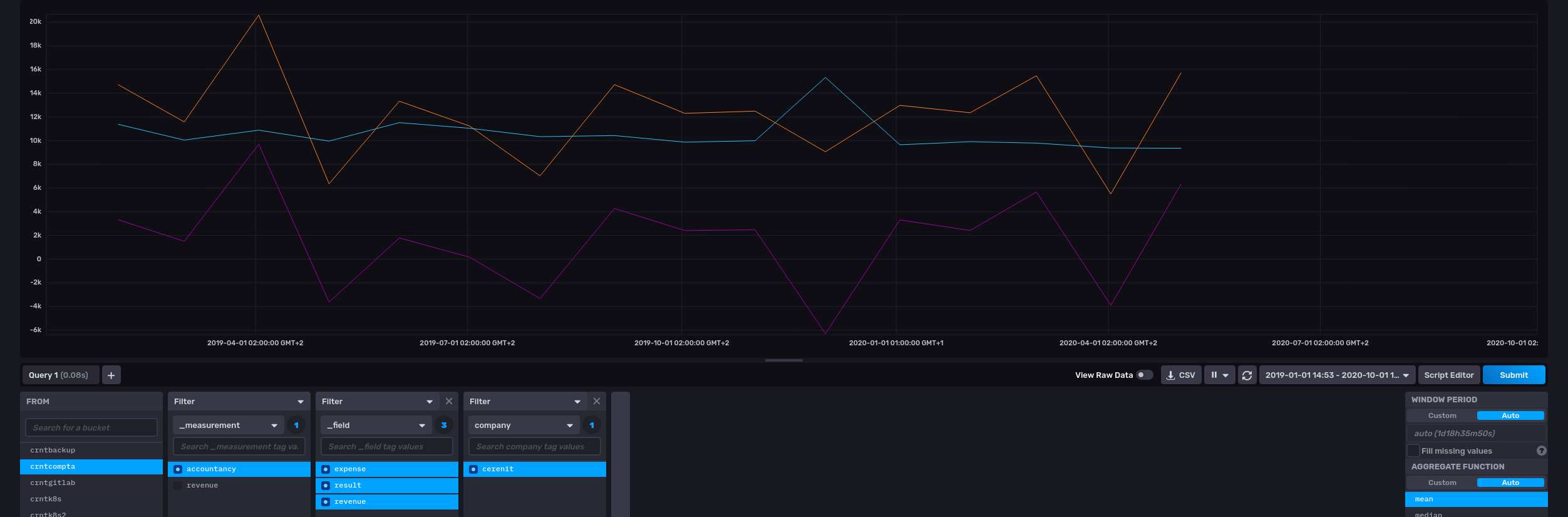
Conclusion
Personnellement, au travers de cette exercice, je trouve FLoWS plutôt agréable à utiliser et il remplit bien son objectif de faciliter la prise en main de Warp 10 :
- Même si je commençais à m’habituer à la NPI/RPN, avoir une approche plus traditionnelle évite de devoir se concentrer sur l’ordre,
- La séparation par des virgules et/ou par des deux points (:) dans les listes et tableaux (MAP) facilitent leur lisiblité
- La migration d’un code en Warpscript vers FLoWS peut se faire de façon très progressive puisque les deux peuvent cohabiter ; c’est d’ailleurs comme ça que j’ai procédé pour ce billet et valider ainsi que je ne perdais rien au fur et à mesure. Il suffit à la fin d’enlever tous les blocs intermédiaires pour n’avoir plus qu’un seul bloc de code en FLoWS. C’est plutôt malin ! Et si une extension ou un code ne serait pas encore disponible en FLoWS, il est possible de débrancher sur du Warpscript.
- Il manque la complétion FLOWS dans le studio (et VSCode je présume) mais c’est pour bientôt !
- Le code gagne en lisiblité car on identifie les blocs qui vont ensemble.
Pour illustrer ce dernier point : quand je repense au code du tutoriel sur les cyclone “Number per year”, nous avons ce code à un moment :
$fetch_wind $end $end $start - TIMECLIP NONEMPTY SIZE
La fonction TIMECLIP prend trois arguments sauf que là, j’en vois potentiellement cinq. Il faut alors comprendre que le troisième argument est en fait le résulat de l’opération $end $start -.
En FLoWS, on aura alors :
TIMECLIP(fetch_wind, end, end - start)
et au global (non testé) :
SIZE(NONEMPTY(TIMECLIP(fetch_wind, end, end - start)))
Ce qui me semble nettement plus clair/lisible.
Le pari de FLoWS était de rendre Warp 10 plus accessible et de rendre les développeurs productifs plus rapidement, il semblerait bien que les objectifs soient remplis.
Web, Ops & Data - Juillet 2020
terraform acme letsencrypt influxdb influxdays questdb timeseries rancher suse stash kubedb maesh warp10 warpscript flows ptsm rgpd safe-harbor données personnelles grafana fluxCloud
- Gestion automatisée de certificats TLS avec Let’s Encrypt via Terraform et Ansible sur AWS : exemple d’utilisation du provider
acmeavec terraform pour la génération et le déploiement d’un certificat Let’s Encrypt dans un contexte AWS. - Custom Variable Validation in Terraform 0.13 : introduite en version expérimentale en 0.12.20, la validation personnalisée de variable sera stable en v ersion 0.13. De quoi valider ses ressources plus simplement.
- Avec l’acquisition d’OpenIO, OVHcloud se donne pour ambition de créer la meilleure offre de Stockage Objet du marché : acquisition d’OpenIO par OVHCloud. OpenIO fournit une solution de stockage compatible S3 et apparemment OVHVloud et OpenIO étaient habituées à travailler ensemble notamment autour de Swift (le stockage objet dans Openstack). Intéressant de voir ce type d’acquisition en Europe d’une part et de voir qu’OVHCloud remonte dans la chaine de valeur et rentre de plus en plus dans le monde du logiciel. A suivre !
Container et orchestration
- Announcing Maesh 1.3 : Maesh continue son chemin et ajoute la capacité de surveiller des namespace particuliées (en plus de pouvoir en ignorer), le support du lookup des ports (http -> 80), le support de CoreDNS chez AKS et d’autres améliorations encore.
- Electro Mpnkeys #9 – Traefik et Maesh : de l’ingress au service mesh avec Michael Matur : si vous voulez en savoir plus sur Traefik et Maesh, je vous conseille cet épisode (et les autres) du podcast Electro Monkeys.
- Introducing Traefik Pilot: a First Look at Our New SaaS Control Platform for Traefik : Containous, la société derrière Traefik, Maesh et Yaegi sort son offre SaaS pour piloter et monitorer ses instances traefik. Un système de plugins pour les middleware fait également son apparaition. Il faut une version 2.3+ (actuellement en RC) de Traefik pour bénéficier de cette intégration.
- Relicensing Stash & KubeDB : KubeDB, l’operateur de bases de données et Stash, l’outil de sauvegarde se cherchent un modèle économique et changent de licence. La version gratuite, avec code source disponible, reste disponible pour des usages non commerciaux (voir les détails de la licence pour une slite exacte). Pour un usage commercial, il faudra passer par la version Entreprise qui apporte aussi des fonctionnalités supplémentaires.
- Suse to acquire Rancher : Suse était sorti de mon radar; c’est donc pour moi l’entrée (ou le retour ?) de Suse dans le monde de kubernetes et de son orchestration. Est-ce une volonté d’aller prendre des parts de marchés à Redhat/Openshift ou de faire face à des rumeurs telles que Google en discussion pour acquérir D2IQ (ex Mesoshphère) ? A voir si cette acquisition va être un tremplin pour Rancher et ses différents projets (rke, rio, k3s, longhorn, etc) comme l’indique son CTO ou pas.
Time Series
- QuestDB nabs $2.3M seed to build open source time series database : QuestDB, historiquement issue du monde du trading à haute fréquence, commence à faire parler d’elle (notamment en récupérant un des DevRel d’InfuxData David G Simmons et vient de lever 2.3 millions de dollars. Elle a une approche SQL sur le traitement des données, se veut performante. A voir si elle reste une spécialiste de la série temporelle financière ou si elle parvient à s’ouvrir à d’autres usages.
- InfluxDays 2020 Virtual Experience : les vidéos et supports des InfluxDays sont disponibles.
- Paris Time Series Meetup #5 : De retour des InfluxDays et FLoWS : Résumé des keynotes autour des annonces produits des InfluxDays et présentation de FLoWS, la nouvelle syntaxte proposée par SenX pour interagir avec Warp10, en alternative à WarpScript. Le but est de faciliter la courbe d’apprentissage autour de Warp10. FLoWS est déjà disponible sur la sandbox et sera disponible cet été ou à la rentrée dans la version 2.7.0 de Warp10.
- Grafana v7.1 released: New features for InfluxDB and Elasticsearch data sources, table panel transformations, and more : grosse nouvelle version mineure de Grafana avec son lots d’amélioration et de nouveautés. Je vous laisse lire l’annonce.
- How to Build Grafana Dashboards with InfluxDB, Flux and InfluxQL : A l’occasion de la sortie de Grafana 7.1 qui apporte le support de Flux, présentation des nouveaux modes d’interaction entre Grafana et InfluxDB
Vie privée & données personnelles
Le Privacy Shield, l’accord entre l’Europe et les USA sur le transfert des données des Européens vers les USA (ou les sociétés américaines) vient d’être invalidé par la cour de justice européene. Les flux “absolument nécessaires” peuvent continuer à se faire pour le moment et la cour a validé “les clauses contractuelles types” définies par la Commission Européenne pourront être utilisées par les entreprises. Néanmoins, pour s’y référer, il semble qu’il faut vérifier que l’entreprise protège effectivement les données. Je vous invite à contacter votre juriste ou avocat pour mieux appréhender les impacts de cette invalidation si vous utilisez les plateformes cloud et des services dont les entreprises sont basées aux USA. En tant qu’individu, il peut être intéressant de se poser des questions également. N’étant pas juriste, je vais donc limiter mon interprétation ici et vous laisse lire les liens ci-dessous.
- La justice européenne sabre le transfert de vos données vers les USA à cause de la surveillance de masse
- L’accord sur le transfert de données personnelles entre l’UE et les Etats-Unis annulé par la justice européenne
- CJEU Judgment - First Statement
- L’accord sur le transfert de données personnelles avec les États-Unis invalidé par la justice européenne
- Invalidation du « Privacy shield » : la CNIL et ses homologues analysent actuellement ses conséquences
- Statement on the Court of Justice of the European Union Judgment in Case C-311/18 - Data Protection Commissioner v Facebook Ireland and Maximillian Schrems
- The End of the Privacy Shield Agreement Could Lead to Disaster for Hyperscale Cloud Providers
