Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Web, Ops, Data et Time Series - Juillet 2021
kubernetes gitlab-ci buildah podman kaniko golang scaleway ia aws frenchtech euclidia vector sécurité opnsense wireguard katz facebook prophet arima sarima holt-winters lstmCI/CD
- Builder simplement des images Docker avec Gitlab-CI (sans DinD) : Personnellement, j’avais migré sous Kaniko depuis un moment. Je ne savais pas que Buildah pouvait ingérer directement des Dockerfile - il me semblait qu’il fallait passer par Podman pour ça. En reprenant le changelog, il semblerait que la fonctionnalité existe depuis un moment.
Cloud
- AWS’s Egregious Egress : Réflexions de Cloudflare sur la tarification du traffic sortant chez AWS et la marge réalisée. A priori, cela ne se base pas uniquement sur des raisons objectives…
- 23 entreprises européennes de technologie du cloud forment l’Alliance industrielle européenne du cloud (EUCLIDIA) : nouvelle association en faveur du cloud européen sur la base de technologies et de sociétés europénnes.
- « Service après-vente bonjour ! » : Le futur de la French Tech ? : tribune d’acteurs français suite à la doctrine du “cloud souverain” et l’utilisation de licences américaines.
Container & Orchestration
- Kubernetes API and Feature Removals In 1.22: Here’s What You Need To Know : les habituelles dépréciéations d’API prévus pour la version 1.22 (Aout 2021)
- Kubernetes Kosmos : sCaleway lance son offre kuberentes multi-cloud et piloté par leur controle plane. En mode private beta pour le moment.
Golang
- Learning Go by examples: Introduction : Après ses explications sur Docker, Istio et Kubernetes, Aurélie Vache s’attaque à Go.
- Learning Go by examples: part 2 - Create an HTTP REST API Server in Go
- Learning Go by examples: part 3 - Create a CLI app in Go
IA
- AI Days 2020 : la playlist youtube des AI Days 2021 est disponible, avec un angle industriel qui change de d’habitude.
Monitoring
- Vector v0.15.0 release notes : de nouveaux sinks & sources, des transformations et de la visualisation. Vector s’améliore au fil des versions.
Sécurité
- Remote code execution in cdnjs of Cloudflare : cdnjs est un CDN pour des ressources en javascript. Mais que peut-il se passer en cas de faille ou de compromission de ce CDN ? C’est le propos de ce billet.
Time Series
- Covid Tracker built with Warp 10 and Discovery : un tutoriel pour apprendre plein de choses sur Discovery, la solution de dashboard as code de SenX pour Warp 10.
- Kats: a Generalizable Framework to Analyze Time Series Data in Python : j’avais évoqué Katz dans une édition précédente, voici un billet qui rentre un peu plus dans le détail des fonctionnalités disponibles.
WireGuard
- WireGuard Site to Site Configuration : si la documentation pour une configuration itinérante (“Road Warrior”) est assez bien documentée, pour du site à site, c’est plus rare. Une explication simple et efficace.
- OPNsense WireGuard VPN Site-to-Site configuration : la même chose mais appliquée à un routeur géré par OPNSense
- OPNsense WireGuard VPN for Road Warrior configuration : la version “Road Warrior” du tutoriel précédent
- WireGuard Road Warrior Setup : la documentation officielle d’OPNSense pour la version “Road Warrior”
Web, Ops, Data et Time Series - Mai 2021
hashicorp nomad ovh time leap second gitlab-ci python dbt metabase datatask warp10 monitoring wasm sécurité spectre timescale sql cli readme bootstrap influxdata kapacitor chronografCI
- GitLab CI Python Library : une librairie en python pour créer des pipelines Gitlab-CI plutôt qu’en YAML.
Cloud
Conteneur et orchestration
- Announcing General Availability of HashiCorp Nomad 1.1 : 10 nouvelles fonctionnalités au programme (7 en OSS, 3 en entreprise) : surallocation de mémoire (soft et hard limit), les CPU peuvent être réservés en tant que tel (et non plus uniquement via une fraction), amélioration d’UI, amélioration coté support CSI, distinction entre les “readyness checks” et “liveness checks” au niveau des health checks, exécution distante sur AWS Lambda et AWS ECS (tech preview). Pour la version entreprise : supper des namespaces consul, chargement automatique des licences lors du déploiement de nouveaux noeuds, amélioration de l’autoscaling.
Data
- Hosting SQLite databases on Github Pages : avec une petite pointe de WASM, exemple de pouvoir utiliser une base sqlite en lecture hébergé en statique et un peu de javascript. Intéressant pour mettre à disposition des applications en “lecture seule” et leur scalabilité.
- DataTask pour construire une self-service BI, Revue des principaux concepts de dbt et création d’un premier modèle dans DataTask, DBT : Workflows, Matérialisations et Documentation, Metabase : Les concepts de question, visualisation et dashboard, DBT et la gouvernance des données : tests de validité/qualité et documentation : S&rie de billets sur la mise en place d’une solution de BI avec dbt et Metabase et l’intégration au sein de la plateforme DataTask
- xo/usql (via MACI #42) : une CLI universelle pour des bases SQL comme MySQL, Postgres, SQLite mais aussi des solutions SaaS comme Snowflake, Spanner et même SAP Hana.
Docs
- readme.so (via MACI #42) : Vous ne savez pas quoi mettre dans votre README ? Ce site est fait pour vous et peut aussi vous aider à réorganiser vos fichiers.
Europe
- Souveraineté et cloud, quel rapport ? : remise en perspective du cloud souverain et implications des décisions européenes. La remise en cause du Privacy Shield et les clauses contractuelles font qu’au final : “tout transfert de données personnelles sous juridiction américaine est illégal.”. La reglementation européene, centré sur le respect des droits des personnes permettrait de fiare un protectionnisme reglementaire dans l’idée de développer un écosystème numérique européen et conforme aux valeurs européennes. A lire et méditer !
License
- Third Party Dependencies that have been Relicensed to AGPL : la position de la CNCF sur les projets passant sous licence AGPL et leur éventuelle intégration dans des projets CNCF. Plutôt mal parti…
Système
- negative leap second news! : une seconde est intercallée de temps à autre pour se resynchroniser avec la rotation terrestre. En général, on ajoutait une seconde. Là, on va retirer une seconde - c’est apparemment la première fois que cela se passe.
Sécurité
- Defenseless: UVA Engineering Computer Scientists Discover Vulnerability Affecting Computers Globally : Vous pensiez en avoir fini avec SPECTRE ? Les correctifs arrivaient assez tard dans la chaine de traitement, des chercheurs ont réussi à intervenir avant pour récupérer des informations. Publications à compter du mois de juin.
- Everything Old is New Again: Binary Security of WebAssembly : si certains pensaient être sauvés par WebAssembley, c’est raté. La VM WebAssembly peut avoir ses propres failles d’une part et d’autre part, un code source vulnérable en WebAssembly présenterait les mêmes failles une fois compilé.
Time Series
- $40 million to help developers measure everything that matters : Timescale annonce une levée en série B de 40 Millions de dollars - environ 2 millions d’instances actives et une dizaine de sorties produits pour le mois de Mai.
- How we made DISTINCT queries up to 8000x faster on PostgreSQL : dans le cadre de la sortie de TimescaleDB 2.2.1, l’arrivée de “Skip Scan” permet d’accélérer les
SELECT DISTINCTentre 28x et 8000x. Cela est valable tant pour les données Timescale que les données natives Postgres. Une contribution upstream est prévue. - TimescaleDB 2.3: Improving columnar compression for time-series on PostgreSQL : Après le rajout des ALTER/RENAME des colonnes compressées en 2.1 - le rajout des INSERT avec une compression en deux temps (compression de l’insert en lui même puis recompaction des données au niveau du chunk)
- QuestDB 6.0 : implémentation de la gestion du Out Of Order, amélioration sur le InfluxDB Inline Protocol ainsi que sur l’UI et la couche SQL.
- How we achieved write speeds of 1.4 million rows per second : retour plus détaillé sur la gestion du Out Of Order dans QuestDB.
- InfluxDB OSS and Enterprise Roadmap Update from InfluxDays EMEA : InfluxData juge qu’à partir de la version 2.0.6, la mise à jour depuis une version 1.8 est stable. La version 1.8 sera donc maintenue jusqu’à la fin d’année. Au-delà de cette date, les correctifs ajoutés seront dans la branche master mais il n’y aura plus de packaging de la version 1.8 OSS. Seule la version 1.8 Entreprise aura de nouveaux binaires. Abandon des binaires en 32 bits pour InfluxDB 2.x. Concernant la version Entreprise, InfluxDB 1.9 va apporter des améliorations notamment concernant le support de Flux. Par ailleurs Chronograf 1.9 et Kapacitor 1.6 vont sortir en juin avec diverses améliorations. Ces deux produits seront compatibles avec InfluxDB 2.x pour aider à la montée de version vers InfluxDB 2.x. Enfin, InfluxDB 0SS 2.1 va sortir aussi en juin avec notamment l’ajout des notebooks, les annotations sur les dashboards et des améliorations de Flux.
- Release Announcement: InfluxDB OSS and InfluxDB Enterprise 1.8.6 : version de maintenance avec une faille de sécurité pour la version Entreprise.
- Monitorer son infra avec Warp 10 - Partie 1, Partie 2, Partie 3 : Mise en oeuvre des outils de la plateforme Warp 10 pour monitorer son infrastructure. Cela couvre l’installation, la collecte des métriques, l’exploration des données et calcul des premiers métriques, et pour finir la création des dashboards.
- Mon Linky dans Warp 10 avec un joli dashboard : Ingestion des données issues du Linky dans Warp 10 et présentation de ces données dans un Dashboard Discovery.
- May 2021: Warp 10 releases 2.8.0 and 2.8.1 - SenX : En résumé (liste non exhaustive, va falloir qqs billets plus détaillés pour comprendre toutes les nouveautés) : Gestion plus fine des “capabilities” au niveau des tokens, Utilisation de FLoWS simplifié, Intégration avec la blockchain Ethereum, Des fonctions de crypto / signature / …, Des améliorations sur la manipulation de JSON, Une fonction HTTP pour permettre des appels distants, Ajout de mapper.geo.fence pour voir si un point est dans/en dehors d’une zone, Des choses autours des MACRO et plein d’autres améliorations/corrections.
- Working with GEOSHAPEs: code contest results : le corrigé du concours lancé par SenX autour des GEOSHAPEs dans Warp 10. Concours que j’ai remporté et voici mes réponses : partie 1 & partie 2
- Wikipedia / Warp 10 : Warp 10 dispose de sa page Wikipedia
- « Le bateau qui vole » : l’analytique en temps réel au service d’un skipper : de l’utilité des séries temporelles dans le monde de la course au large pour une meilleure appréhension du fonctionnement du bateau et de ses performances. Ce retour d’expérience sera le thème d’une prochaine édition du Time Series France !
Web
- Bootstrap 5 : nouvelle version majeure du framework Boostrap avec la suppression de la dépendance à JQuery et la fin de support de plein de vieux navigateurs notamment.
Web, Ops, Data et Time Series - Avril 2021
falco sysdig sécurité dashboard raspberrypi pico hashicorp vault vector containerd git git-filter-repo psp gitlab-ci podman warp10 sqlite terraform timescale velero docker docker-compose grafana loki tempo kubernetes minio influxdata notebook geospatial agpl bme680 co2Code
- Docteur, j’ai commité 8 Go dans mon Git. C’est grave ? : un petit exemple de l’utilisation de git-filter-repo pour nettoyer son historique git de fichiers inutiles.
- Les pipelines parent-enfant de gitlab-ci : article sur la modularisation de gitlab-ci avec les pipelines parent/enfant au sein d’un même dépôt de code ou entre plusieurs dépot avec passage de variables entre eux.
- Minio Changes License to AGPL : Minio passe (aussi) son code en AGPL, l’annonce officielle n’est pas encore arrivée.
Conteneur et orchestration
- Electro Monkeys - Docker Compose avec Nicolas de Loof : Retour sur la Developper Experience autour de Docker, l’historique et le futur de docker-compose, la création de la spécification Compose, les intégrations AWS/ECS et Azure/ACI, l’intégration Kubernetes, etc.
- nerdctl: Docker-compatible CLI for contaiNERD : une CLI qui imite la CLI Docker mais en interagissant directement avec containerd. Elle permet aussi de bénéficier de certaines fonctionnalités de containerd qui ne sont pas prévues pour tout de suite dans Docker apparemment.
- Blog: Kubernetes 1.21: Power to the Community : au programme de cette nouvelle version : Cronjobs GA, Immutable Secrets and ConfigMaps GA, IPv4/IPv6 dual-stack support, Graceful Node Shutdown, PersistentVolume Health Monitor mais aussi PodSecurityPolicy Deprecation et TopologyKeys Deprecation
- PodSecurityPolicy Deprecation: Past, Present, and Future: article plus détaillé sur la dépréciation des PSP.
- Podman v3.1.0 Released : ajout de la gestion des secrets, améliorations des commandes kube avec notamment la génération des PersistentVolumeClaim ou encore la gestion des propriétaires des volumes.
- Velero 1.6.0 : améliorations diverses comme le support des identifiants par buckets (et non globaux uniquement), mise à jour de restic vers 0.12.0, etc.
- Compose CLI Tech Preview :
composedevrait devenir une sous-commande officiel de la CLI Docker ; on pourra alors fairedocker compose up -d - Docker 20.10.6 : version de maintenance avec le support des puces Apple Silicon M1.
- Kubernetes : vers 3 releases par an au lieu de 4 : de quoi courrir un peu moins derrière les versions et à relier avec le support de chaque version étendue à 1 an depuis la 1.19.
Data
- sq: swiss-army knife for data : le
jqpour les données relationelles. Du SQL ou des fichiers Excel/CSV/JOSN/XML en entrée et les mêmes formats en sortie (et un peu plus). - SQLite is not a toy database : On a souvent une fausse image de sqlite - l’article permet de se mettre à jour…
IaC
- Conditional nested blocks in Terraform : si les dynamic blocks avec terraform sont utiles pour peupler dynamiquement des structures à partir de tableaux/listes/objets, il peut aussi être utiliser pour gérer la présence conditionnelle de blocs.
- Announcing HashiCorp Terraform 0.15 General Availability : la plus grosse annonce étant que la 0.15 initie les travaux en vue de la release 1.0 ; pour ceux qui sont à jour, la mise à jour ne devait pas poser de problèmes (cf guide). Pour plus d’informations, cf CHANGELOG.
- HashiCorp is the latest victim of Codecov supply-chain attack : victime de la supply chain attach de codecov, Hashicorp vient de publier les versions patchées de Terraform des versions 0.11 à 0.15. Faites la mise à jour rapidement même si la clé volée n’a a priori pas été utilisée frauduleusement.
IoT
- Pico 2 Pi Adapter Board : un petit adapteur sympathique pour Raspeberry Pi Pico et vous permettre de brancher facilement vos composants sans soudure et mener ainsi vos expériences.
- Piper Make : Pour programmer facilement votre Raspberry Pi Pico en MicroPython mais avec une logique de blocs à la Scratch.
- Utilisation des BME680 et RV3028 avec Raspberry Pi Pico : le composant BME680 permet d’évaluer la qualité de l’air - le projet permet donc de capturer et d’afficher cette information avec un Raspberry Pi. Son successeur, le BME688 dispose d’une pincée d’IA.
- Projet CO2 et Makers CO2 : pour mieux comprendre les enjeux autour de l’aération des pièces et comment faire vos capteurs.
Observabilité & Monitoring
- Coder ses dashboards Grafana avec Grafonnet : Grafonnet est une extension de jsonnet ; il permet de déclarer ses dashboards Grafana via un lanage formalisé plutôt que de copier/coller des dashboards en JSON. Cela permet ainsi d’avoir une approche un peu plus “Dashboard as code”.
- Grafana 7.5 released: Loki alerting and label browser for logs, next-generation pie chart, and more! : un nouveau panel pour les “camembers” (“pie charts”), des améliorations pour les autres produits grafana (loki, tempo), ainsi qu’Elasticsearch, Postgresql et Cloudwatch et sur la version Entreprise.
- Vector v0.12.0 Release Notes, 0.12.1, 0.12.2 : Comme indiqué en février, la release de Vector apportant leur nouveau langage de traitement “Vector Remap Language est disponible, ainsi que des améliorations sur
vector top, la sourceinternal_logset l’API GraphQL. Un guide de mise à jour vers la nouvelle syntaxe est disponible. - Release Announcement: Telegraf 1.18.1 : version de maintenance
- Grafana, Loki, and Tempo will be relicensed to AGPLv3 & Q&A with Grafana Labs CEO Raj Dutt about our licensing changes : les produits phares de Grafana Labs passent d’une licence Apache 2 à AGPLv3. Les autres produits pourront rester sous licence ASL 2.0. L’AGPL étant contaminante, cela pourrait interdire l’usage de ces produits dans certains contextes, y compris à la CNCF. Vu l’implication de Grafana Labs dans le monde Prometheus, il va falloir suivre comment cela va se passer.
Réseau
- The Mystery of AS8003 : Une entité inconnue jusque là mais liée à l’administration américaine a annoncé la gestion d’une très grande plage réseau. Les implications et les motivations sont encore à éclaircir. Le billet émet différents hypothèses. Le thread twitter associé est intéressant aussi.
Sécurité
- Electro Monkeys - La sécurité dans tous ses états – détection de comportements indésirables grâce à Falco avec Thomas Labarussias : Présentation des projets falco et sysdig qui permettent d’analyser les comportements de vos applications (conteneurisées ou pas) en se basant sur les syscalls.
- Announcing HashiCorp Vault 1.7 : version mineure avec des améliorations internes au produit, sur la version entreprise et un peu au niveau UI.
Time Series
- InfluxDays EMEA 2021 Virtual Experience : InfluxData organise la session européenne de sa conférence avec le point sur les différents produits et les développements à venir. Des nouvelles de l’écosystème (Grafana, etc) sont attendues aussi, ainsi que des retours clients. Des formations Flux et Telegraf sont aussi prévues respectivement les 10/11 mai et le 17 Mai.
- InfluxData releases InfluxDB Notebooks to enhance collaboration for teams working with time series data & Build notebooks in InfluxDB Cloud | InfluxDB Cloud Documentation : InfluxData lance son offre de notebook intégré à sa plareforme InfluxDB (version cloud uniquement pour le moment)
- Build a Complete Application with Warp 10, from TCP Stream to Dashboard : exemple complet de l’utilisation de la plateforme Warp 10 depuis l’ingestion des messages AIS des bateaux via un client TCP jusqu’à la visualisation des données après un passage par les étapes de stockage et nettoyage des données. Très intéressant même si je vais devoir relire tranquillement le billet pour bien comprendre certaines astuces et certains “raccourcis” au niveau du code.
- Working with GEOSHAPEs & Working with GEOSHAPEs: code contest! : un billet (et un concours) pour exploiter la dimension géospatiale de Warp 10.
- TimescaleDB 2.2.0 : diverses améliorations mais surtout une annonce sur la fin de support de Postgresql 11 à compter de mi-juin et de la prochaine version de TimescaleDB. C’est justifié par l’absence d’une fonctionnalité dans Postgresql 11.x et requise pour la prochaine version de TimescaleDB.
Docker et déploiement distant : tout est histoire de contexte
docker context ssh gitlab gitlab-ciKubernetes, c’est bien mais parfois on veut faire des choses plus simples et on n’a pas forcément besoin d’avoir un système distribué ou d’une forte disponibilité. Pour autant, il est agréable avec kubernetes de pouvoir interagit à distance avec l’API au travers de kubectl. Je me suis donc mis en quête d’une alternative. Partir sur k3s avec un déploiement mono-node ? Partir sur docker/docker-compose/docker-swarm ?
Je me souvenais que l’on pouvait exposer la socket docker sur le réseau en TCP et authentification par certificat mais cela ne me plaisait pas beaucoup. Je me suis alors rappelé que l’on pouvait interagir avec un hote docker via une connection ssh. En continuant à creuser, je suis tomber sur les contextes dans Docker et ce billet How to deploy on remote Docker hosts with docker-compose. Et là : 🤩
Alors, certes, pas de secrets, configmaps ou cronjobs mais un déploiement remote que je peux automatiser dans gitlab et/ou avec lequel je peux interagir à distance 😍
Création d’un contexte puis utilisation d’un contexte :
# Création du contexte docker
docker context create mon-serveur ‐‐docker “host=ssh://user@monserveur”
# Lister les contextes docker existant
docker context ls
# Utiliser un contexte
docker context use mon-serveur
# Vérifier le bon fonctionnement de la cli docker
docker ps
[liste de conteneurs tournant sur la machine "mon-serveur"]
# Vérifier le bon fonctionnement de la cli docker-compose
cd /path/to/docker/compose/project
docker-compose ps
Pour que cela fonctionne, en plus des versions récentes de docker et docker-compose coté client et serveur. Il vous faut aussi une version récent de paramiko coté client. Celle présente dans Debian 10 n’est pas assez à jour par ex, il a fallu passer par pip3 install paramiko. Il faut aussi avoir une authentification par clé pour se simplifier la vie.
Pour docker-compose, vous avez deux solutions pour utiliser un contexte distant :
# En deux commandes
docker context use <remote context>
docker-compose <command>
# En une commande
docker-compose --context <remote context> <command>
Dans gitlab, dans le fichier .gitlab-ci.yml, on peut alors profiter de cette intégration de la façon suivante ; je prends l’exemple du déploiement du site du Paris Time Series Meetup.
Tout d’abord, dans mon fichier docker-compose.yml, j’ai mis un place holder IMAGE qui sera remplacé par la référence de mon image docker fabriquée par gitlab-ci :
version: '3.8'
services:
web:
image: IMAGE
labels:
[...]
restart: always
Ensuite, dans gitlab-ci :
- le job “publish” génère la version html du site et le stock dans un artefact gitlab.
- le job “kaniko” va générer l’image docker contenant la version html du site. Pour passer la version de l’image, je stocke l’information dans un fichier
docker.env. Ce fichier sera sauvegardé en fin de job sous la forme d’un artefact disponible pour le job “docker”. - le job “docker” recupère ce qui était dans le
docker.envsous la forme de variable d’environnement. Il remplace ensuiteIMAGEpar sa vraie valeur. On initialise le contexte docker pour se connecter au serveur cible et on peut alors réaliser les actions habituelles avecdocker-compose.
---
stages:
- publish
- image
- deploy
publish:
image: $CI_REGISTRY/nsteinmetz/hugo:latest
artifacts:
paths:
- public
expire_in: 1 day
only:
- master
- web
script:
- hugo
stage: publish
tags:
- hugo
kaniko:
stage: image
image:
name: gcr.io/kaniko-project/executor:debug
entrypoint: [""]
variables:
RELEASE_IMAGE: $CI_REGISTRY_IMAGE:$CI_COMMIT_SHORT_SHA-$CI_PIPELINE_ID-$CI_JOB_ID
script:
- echo "IMAGE=${RELEASE_IMAGE}" >> docker.env
- mkdir -p /kaniko/.docker
- echo "{\"auths\":{\"$CI_REGISTRY\":{\"username\":\"$CI_REGISTRY_USER\",\"password\":\"$CI_REGISTRY_PASSWORD\"}}}" > /kaniko/.docker/config.json
- /kaniko/executor --context $CI_PROJECT_DIR --dockerfile $CI_PROJECT_DIR/Dockerfile --destination $RELEASE_IMAGE
only:
- master
- web
when: on_success
tags:
- kaniko
artifacts:
reports:
dotenv: docker.env
docker:
stage: deploy
before_script:
- docker login -u gitlab-ci-token -p $CI_JOB_TOKEN $CI_REGISTRY
script:
- sed -i -e "s|IMAGE|${IMAGE}|g" docker-compose.yml
- docker context use mon-serveur
- docker-compose pull
- docker-compose up -d
needs:
- job: kaniko
artifacts: true
when: on_success
only:
- master
- web
tags:
- shell
environment:
name: production
url: https://www.ptsm.io/
Et voilà ! 😎
Avec ces contextes (que l’on peut utiliser aussi avec swarm et kubernetes), on a donc un moyen simple et efficace pour déployer des conteneurs à distance et de façon automatisée.
Intégration Gitlab dans Kubernetes pour automatiser ses déploiements
gitlab kubernetes deployment service-account gitlab-ciDepuis que j’ai migré des sites sous kubernetes, j’avais perdu l’automatisation du déploiement de mes conteneurs. Pour ce site, je modifiais donc le site et une fois le git push realisé, j’attendais que Gitlab-CI crée mon conteneur. Je récupérai alors le tag du conteneur que je mettais dans le dépôt git où je stocke mes fichiers de configuration pour kubernetes. Une fois le tag mis à jour, je pouvais procéder au déploiement de mon conteneur. Il était temps d’améliorer ce workflow.
Gitlab propose depuis un moment une intégration avec kubernetes mais je lui trouve quelques inconvénients au regard de mes besoins :
- Il faut créer un compte avec un ClusterRole cluster-admin et je ne suis pas super à l’aise avec cette idée,
- Il est nécessaire de déployer Helm encore en version 2 alors que je suis passé en version 3 pour les rares projets où je l’utilise,
- L’ingress s’appuie sur nginx-ingress, alors que j’utilise Traefik,
- Je n’ai pas l’usage des autres fonctionnalités fournies par Gitlab dans mon contexte de “cluster de test” hébergeant quelques sites et applications web.
Mon besoin pourrait se résumer à pouvoir interagir avec mon cluster au travers de kubectl et de pouvoir y déployer la nouvelle version du conteneur que je viens de créer. Cela suppose alors d’avoir 3 choses :
- le binaire kubectl accessible sous la forme d’un conteneur ou directement en shell dans le runner,
- un fichier
kubeconfigpour m’authentifier auprès du cluster et interagir avec, - la référence de l’image docker fraichement crée par Gitlab-CI à appliquer sur un Deployment kubernetes.
Création d’un compte de service avec authentification par token
Utilisant le service managé d’OVH, je n’ai pas accès à tous les certificats du cluster permettant de créer de nouveaux comptes utilisateurs. Par ailleurs, pour les intégrations comme Gitlab, il est recommandé d’utiliser des Service Accounts. C’est ce que nous allons faire.
En plus du Service Account, il nous faut donner un rôle à notre compte pour qu’il puisse réaliser des actions sur le cluster. Par simplicité pour ce billet, je vais lui donner les droits d’admin au sein d’un namespace. Le compte de service pourra alors faire ce qu’il veut mais uniquement au sein du namespace en question. En cas de fuite du compte, les dégats potentiels sont donc moindres qu’avec un compter qui est admin global du cluster. Le rôle admin existe déjà sous kubernetes, il s’agit du ClusteRole admin mais qui est restreint à un namespace via le RoleBinding.
Créons le fichier gitlab-integtration.yml avec ces éléments :
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: gitlab-example
namespace: example
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: gitlab-admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: admin
subjects:
- kind: ServiceAccount
name: gitlab-example
namespace: example
Déployons notre configuration sur le cluster :
# Apply yml file on the cluster
kubectl apply -f gitlab-integration.yml
serviceaccount/gitlab-example created
rolebinding.rbac.authorization.k8s.io/gitlab-admin created
Pour alimenter notre fichier kubeconfig, il nous faut récupérer le token :
# Get secret's name from service account
SECRETNAME=`kubectl -n example get sa/gitlab-example -o jsonpath='{.secrets[0].name}'`
# Get token from secret, encoded in base64
TOKEN=`kubectl -n example get secret $SECRETNAME -o jsonpath='{.data.token}'`
# Decode token
CLEAR_TOKEN=`echo $TOKEN |base64 --decode`
En prenant votre fichier kubeconfig de référence, vous pouvez alors créer une copie sous le nom kubeconfig-gitlab-example.yml et l’éditer de la façon suivante :
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: <Existing certificate in a base64 format from your original kubeconfig file>
server: <url of your k8s http endpoint like https://localhost:6443/ >
name: kubernetes # adjust your cluster name
contexts:
- context:
cluster: kubernetes # adjust your cluster name
namespace: example # adjust your namespace
user: gitlab-example # adujust your user
name: kubernetes-ovh # adujust your context
current-context: kubernetes-ovh # adujust your context
kind: Config
preferences: {}
users:
- name: gitlab-example # adujust your user
user:
token: <Content of the CLEAR_TOKEN variable>
Vous pouvez tester son bon fonctionnement via :
# Fetch example resources if any:
kubectl --kubeconfig=./kubeconfig-gitlab-example.yml get all
...
# Check you can't access other namespaces information, like kube-system:
kubectl --kubeconfig=./kubeconfig-gitlab-example.yml get all -n kube-system
Error from server (Forbidden): pods is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "pods" in API group "" in the namespace "kube-system"
Error from server (Forbidden): replicationcontrollers is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "replicationcontrollers" in API group "" in the namespace "kube-system"
Error from server (Forbidden): services is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "services" in API group "" in the namespace "kube-system"
Error from server (Forbidden): daemonsets.apps is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "daemonsets" in API group "apps" in the namespace "kube-system"
Error from server (Forbidden): deployments.apps is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "deployments" in API group "apps" in the namespace "kube-system"
Error from server (Forbidden): replicasets.apps is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "replicasets" in API group "apps" in the namespace "kube-system"
Error from server (Forbidden): statefulsets.apps is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "statefulsets" in API group "apps" in the namespace "kube-system"
Error from server (Forbidden): horizontalpodautoscalers.autoscaling is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "horizontalpodautoscalers" in API group "autoscaling" in the namespace "kube-system"
Error from server (Forbidden): jobs.batch is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "jobs" in API group "batch" in the namespace "kube-system"
Error from server (Forbidden): cronjobs.batch is forbidden: User "system:serviceaccount:example:gitlab-example" cannot list resource "cronjobs" in API group "batch" in the namespace "kube-system"
Integration Gitlab : stocker le kubeconfig
Gitlab permet de stocker des variables. Dans le cas d’un fichier kubeconfig, on va vouloir ne jamais afficher son contenu dans les logs ou autre. Pour cela il est possible de masquer vos variables en respectant quelques contraintes et notamment que la valeur de la variable tienne sur une seule ligne.
Nous allons donc encoder le fichier en base64 et rajouter un argument pour que tout soit sur une seule ligne (et non pas sur plusieurs lignes par défaut):
# create a one line base64 version of kubeconfig file
cat kubeconfig-gitlab-example.yml | base64 -w 0
Copier le contenu obtenu dans une variable que nous appelerons KUBECONFIG et dont on cochera bien la case “Mask variable”. Une fois la variable sauvée, vous avez ceci :
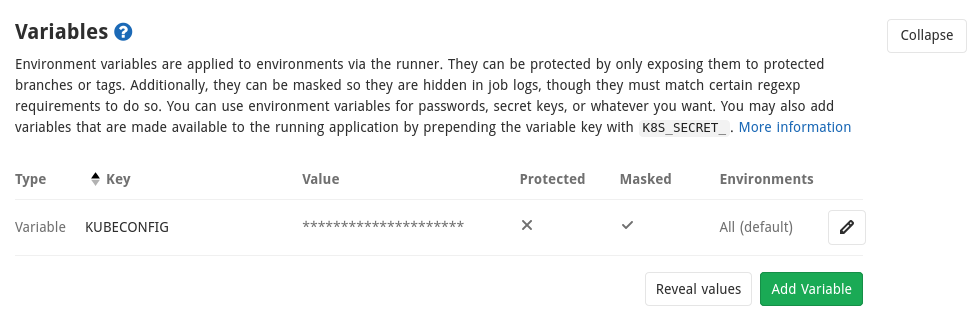
Intégration Gitlab : passer la référence de l’image au job de déploiement
Soit le fichier .gitlab-ci.yml suivant:
---
stages:
- publish
- image
- deploy
publish:
image: $CI_REGISTRY/nsteinmetz/hugo:latest
artifacts:
paths:
- public
expire_in: 1 day
only:
- master
- web
script:
- hugo
stage: publish
tags:
- go
docker:
stage: image
image: docker:stable
services:
- docker:dind
variables:
DOCKER_HOST: tcp://docker:2375
DOCKER_DRIVER: overlay2
RELEASE_IMAGE: $CI_REGISTRY_IMAGE:$CI_COMMIT_SHORT_SHA-$CI_PIPELINE_ID-$CI_JOB_ID
before_script:
- docker login -u gitlab-ci-token -p $CI_JOB_TOKEN $CI_REGISTRY
script:
- echo "IMAGE=${RELEASE_IMAGE}" >> docker.env
- docker build --pull -t $RELEASE_IMAGE .
- docker push $RELEASE_IMAGE
when: on_success
tags:
- go
artifacts:
reports:
dotenv: docker.env
kube:
stage: deploy
script:
- echo $KUBECONFIG | base64 --decode > kubeconfig
- export KUBECONFIG=`pwd`/kubeconfig
- sed -i -e "s|IMAGE|${IMAGE}|g" deployment.yml
- kubectl apply -f deployment.yml
needs:
- job: docker
artifacts: true
when: on_success
tags:
- shell
Petite explication rapide :
- l’étape
publishva générer la version html du site et la stocker sous la forme d’un artefact qui sera passé aux jobs suivants, - l’étape
dockerva créer l’image en mettant l’artefact du job précédent dans un conteneur nginx et le publier dans la registry gitlab avec le nom suivantgitlab.registry/group/project:<short commit>-<pipeline id>-<job id> - l’étape
kubeva récupérer le contenu de la variableKUBECONFIG, le décoder et créer un fichierkubeconfig. On initialise la variable d’environnementKUBECONFIGpour que kubectl puisse l’utiliser. On met à jour la référence de l’image docker obtenue précédemment dans le fichierdeployment.ymlqui sert de modèle de déploiement. On applique le fichier obtenu sur le cluster kubernetes pour mettre à jour le déploiement.
Le point d’attention ici est que le passage de la variable RELEASE_IMAGE se fait via un dotenv qui est créé sous la forme d’un artefact à l’étape docker et est donc disponible à l’étape kube. Cela devrait être automatique mais j’ai ajouté une dépendance explicite via la directive needs. Lors de l’étape kube, le contenu du fichier docker.env est disponible sous la forme de variables d’environnement. On peut alors faire la substitution de notre placeholder par la valeur voulue dans deployment.yml.
Tout ce mécanisme est expliqué dnas la doc des variables gitlab et sur les variables d’environnement héritées. Attention, il vous faut Gitlab 13.0+ pour avoir cette fonctionnalité et en plus, il faut préalablement activer ce feature flag.
sudo gitlab-rails console
Feature.enable(:ci_dependency_variables)
En conclusion, nous avons vu comment :
- Créer un compte de service (Service Account) sous kubernetes avec un rôle d’administrateur de namespace,
- Stocker le fichier
kubeconfigutilisant notre service account dans Gitlab sous la forme d’une variable masquée, - Passer une référence d’un job à un autre via les dotenv au niveau du job amont et les variables d’environnement au niveau du job en aval,
- Récupérer le contenu de la variable kubeconfig pour créer une variable d’environnement et être en mesure d’utiliser kubectl.
Ainsi, toute mise à jour de master conduira à une mise à jour du déploiement associé au sein du cluster kubernetes et ne nécessitera plus d’interventions manuelles comme précédemment. Avec un service account lié à un namespace, on évite aussi de s’exposer inutilement en cas de fuite des identifiants.
