Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Warp 10 - Interactions avec une instance InfluxDB
warp10 timeseries influxdb warpscript warpfleetAprès les premiers pas avec Warp10 et en attendant que l’extension FLoWS soit disponible pour la version 2.7.0, j’ai mis à jour mon instance Warp 10 en 2.7.0 et j’ai voulu jouer avec l’extension warp10-ext-influxdb. Cette extension permet de requêter une instance InfluxDB 1.x ou 2.x avec du WarpScript.
Attention à ne pas confondre le plugin natif InfluxDB qui permet d’envoyer des métriques au format Line Protocol d’InfluxDB dans Warp10 et l’extension InfluxDB qui permet d’interagir avce une base InfluxDB en WarpScript.
Pré-requis: warpfleet
Installons déjà warpfleet, le gestionnaire de package conçu pour Warp 10.
# Installation de npm
sudo dnf install -y npm
# installation de warpfleet
sudo npm install -g @senx/warpfleet
# Vérification de la bonne installation de warpfleet
wf version
___ __ _______________ _____
__ | / /_____ __________________ ____/__ /___________ /_
__ | /| / /_ __ `/_ ___/__ __ \_ /_ __ /_ _ \ _ \ __/
__ |/ |/ / / /_/ /_ / __ /_/ / __/ _ / / __/ __/ /_
____/|__/ \__,_/ /_/ _ .___//_/ /_/ \___/\___/\__/
/_/ ™
version: 1.0.31
1.0.31
Installation de l’extension warp10-ext-influxdb
Sans trop rentrer dans les détails de warpfleet, il utilise un système de namespace appelés “Groups” pour ces packages et qui permettent de définir ses propres dépots. Pour l’extension warp10-ext-influxdb, le “group” est io.warp10.
Ce qui pour l"installation donne la commande suivante :
# Si votre utilisateur n'a pas accès à /path/to/warp10, il vous faudra utiliser sudo
(sudo) wf g -w /path/to/warp10 io.warp10 warp10-ext-influxdb
warpfleet va vous demander quelle version de l’extension vous souhaitez puis va procéder à son téléchargement et son installation.
Cela donne :
sudo wf g -w /opt/warp10 io.warp10 warp10-ext-influxdb
___ __ _______________ _____
__ | / /_____ __________________ ____/__ /___________ /_
__ | /| / /_ __ `/_ ___/__ __ \_ /_ __ /_ _ \ _ \ __/
__ |/ |/ / / /_/ /_ / __ /_/ / __/ _ / / __/ __/ /_
____/|__/ \__,_/ /_/ _ .___//_/ /_/ \___/\___/\__/
/_/ ™
version: 1.0.31
? Which revision do you want to retrieve? latest
✔ ext io.warp10:warp10-ext-influxdb#1.0.1-uberjar retrieved
✔ Download successful: gradle-wrapper.jar
✔ Download successful: gradle-wrapper.properties
✔ Download successful: gradlew
✔ Download successful: gradlew.bat
✔ Dependency warp10-ext-influxdb-1.0.1-uberjar.jar successfully deployed
✔ Done
Note: Pour éviter un bug dans la fonction INFLUXDB.UPDATE identifié lors de la rédaction de ce billet, assurez-vous d’avoir une version >= 1.0.1
Ensuite, il faut créer le fichier /path/to/warp10/etc/conf.d/90--influxdb-extension.conf et y ajouter la ligne suivante:
warpscript.extension.influxdb = io.warp10.script.ext.influxdb.InfluxDBWarpScriptExtension
Je préfère créer un fichier plutôt que d’éditer un fichier existant pour le suivi des mises à jour et j’ai utilisé le prefix 90 car il n’est pas utilisé par les fichiers de Warp10.
Relancer ensuite Warp 10 pour que le plugin soit chargé au démarrage de l’instance :
(sudo) /path/to/warp10/bin/warp10-standalone.init restart
Dans /path/to/warp10/logs/warp10.log, vous devriez voir apparaitre :
2020-09-17T10:59:23,742 main INFO script.WarpScriptLib - LOADED extension 'io.warp10.script.ext.influxdb.InfluxDBWarpScriptExtension'
Requêtage d’une instance InfluxDB 1.x
Note: La librairie influxdb-java ne semble pas supporter un reverse proxy http/2 devant l’instance InfluxDB. Il faut donc accéder à InfluxDB en direct via le port 8086.
# Requête INFLUXQL et informations de connection à InfluxDB 1.X
{ 'influxql' "select * from cpu where host=%27myHost%27 and time > now() - 1h" 'db' "myDatabase" 'password' "myPassword" 'user' "myUser" 'url' "http://url.to.influxdb:8086" }
INFLUXDB.FETCH
# On récupère une liste de liste de séries GTS. Il n'y a qu'un seul élément dans cette liste. Nous le prenons pour n'avoir plus qu'une liste de séries GTS.
0 GET
# Sauvegarde de la liste dans une variable cpu
'cpu' STORE
# Affichage de la liste de GTS
$cpu
Dans ce qu’il faut noter ici:
INFLUXDB.FETCHprend ses paramètres dans une MAP ayant pour paramètres:influxql,db,password,usereturl.- Pour la directive where, il faut encoder les apostrophes via
%27: en InfluxQL, on écrirait... where host='myHost'; là, il faut écrirewhere host=%27myHost%27 - Si dans InfluxDB, on a un measurements (cpu) avec n items (usage_guest, usage_idle, etc), on a une conversion en une liste de n GTS avec une valeur chacune.
influxqlprend une ou plusieurs requêtes séparées par des points virgules. Cela donnera en sortie plusieurs listes de listes de GTS (vu que comme dit au dessus, pour une requête influxql sur un measurement on a 1 à n GTS ; donc pour y requêtes, on aura y listes de n listes de GTS)
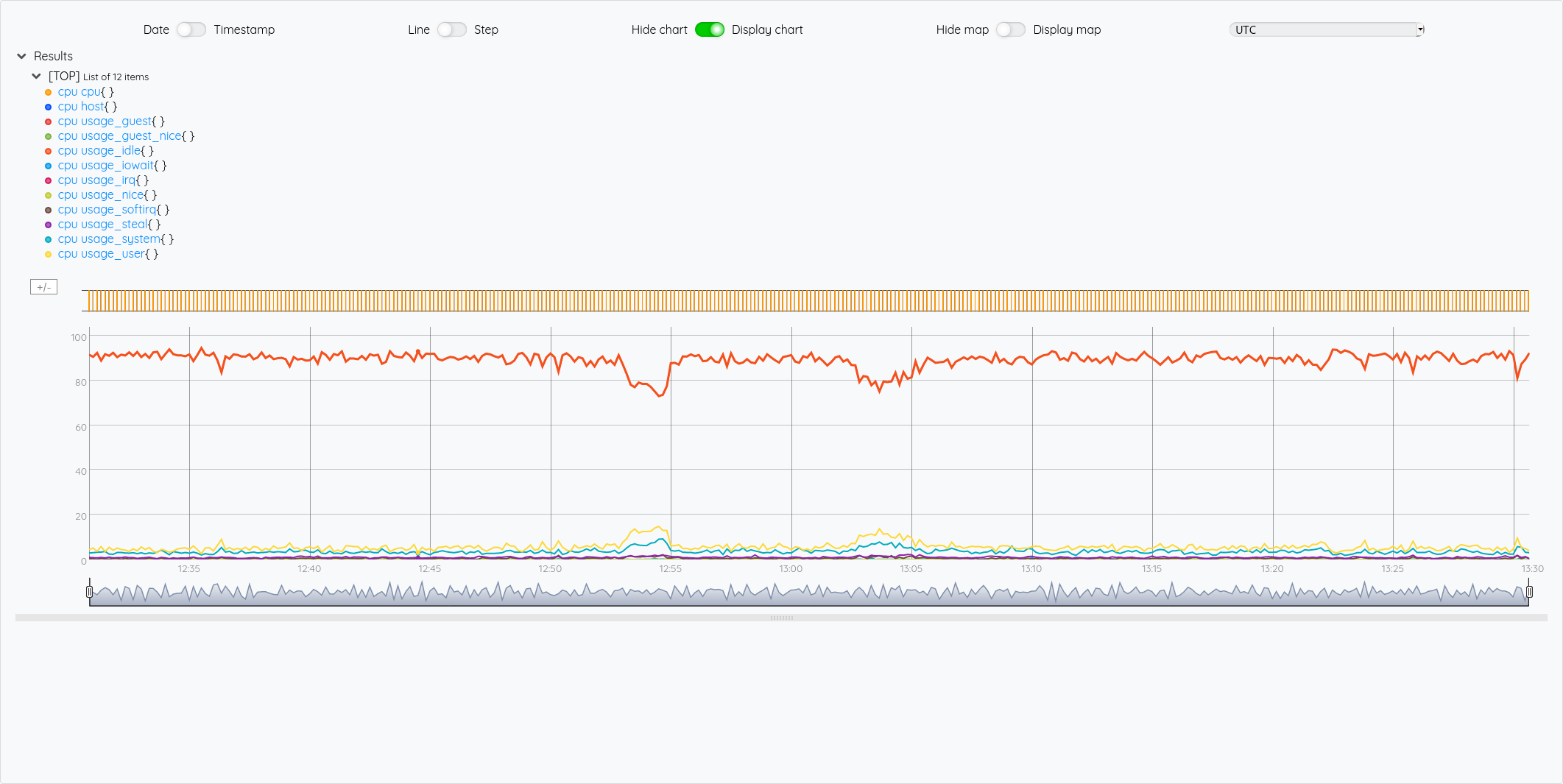
Pour illustrer cette liste de liste de GTS, si on veut récupérer la GTS du cpu idle, on voit dans le graphique que c’est la 5ème courbe, donc un indice 4.
{ 'influxql' "select * from cpu where host=%27myHost%27 and time > now() - 1h" 'db' "myDatabase" 'password' "myPassword" 'user' "myUser" 'url' "http://url.to.influxdb:8086" }
INFLUXDB.FETCH
0 GET
'cpu' STORE
# Récupération de la 5ème liste (indice 4)
$cpu 4 GET
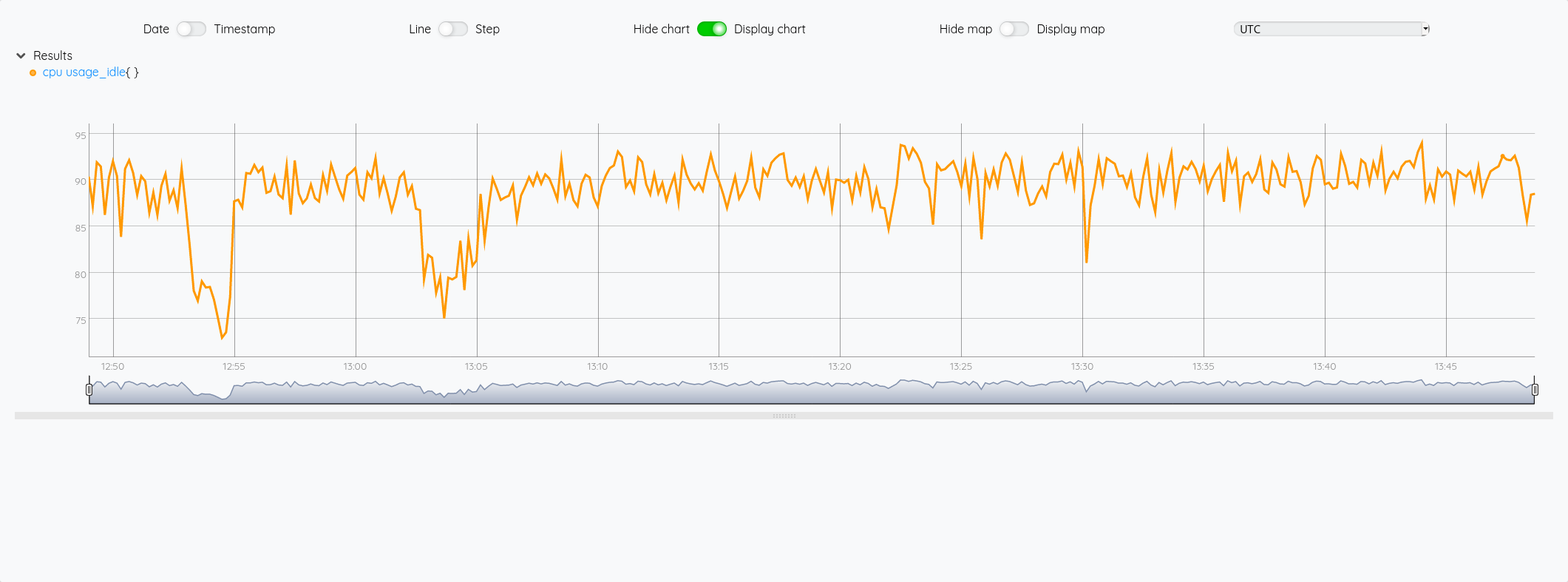
Requêtage d’une instance InfluxDB 2.x
Note: La librairie influxdb-client-java ne semble pas plus supporter un reverse proxy http/2 devant l’instance InfluxDB. Il faut donc accéder à InfluxDB en direct via le port 9999.
Si on fait une requête similaire en flux :
# Requête FLUX et informations de connection à InfluxDB 2.x
{ 'flux' "from(bucket: %22myBucket%22) |> range(start: -1h, stop: now()) |> filter(fn: (r) => r[%22_measurement%22] == %22cpu%22) |> filter(fn: (r) => r[%22cpu%22] == %22cpu-total%22) |> aggregateWindow(every: 1s, fn: mean, createEmpty: false) |> yield(name: %22mean%22)" 'org' "myOrganisation" 'token' "myToken" 'url' "http://url.to.influxdb2:9999" }
INFLUXDB.FLUX
# On récupère une liste de séries GTS
# Sauvegarde de la liste dans une variable cpu
'cpu' STORE
# Affichage de la liste de GTS
$cpu
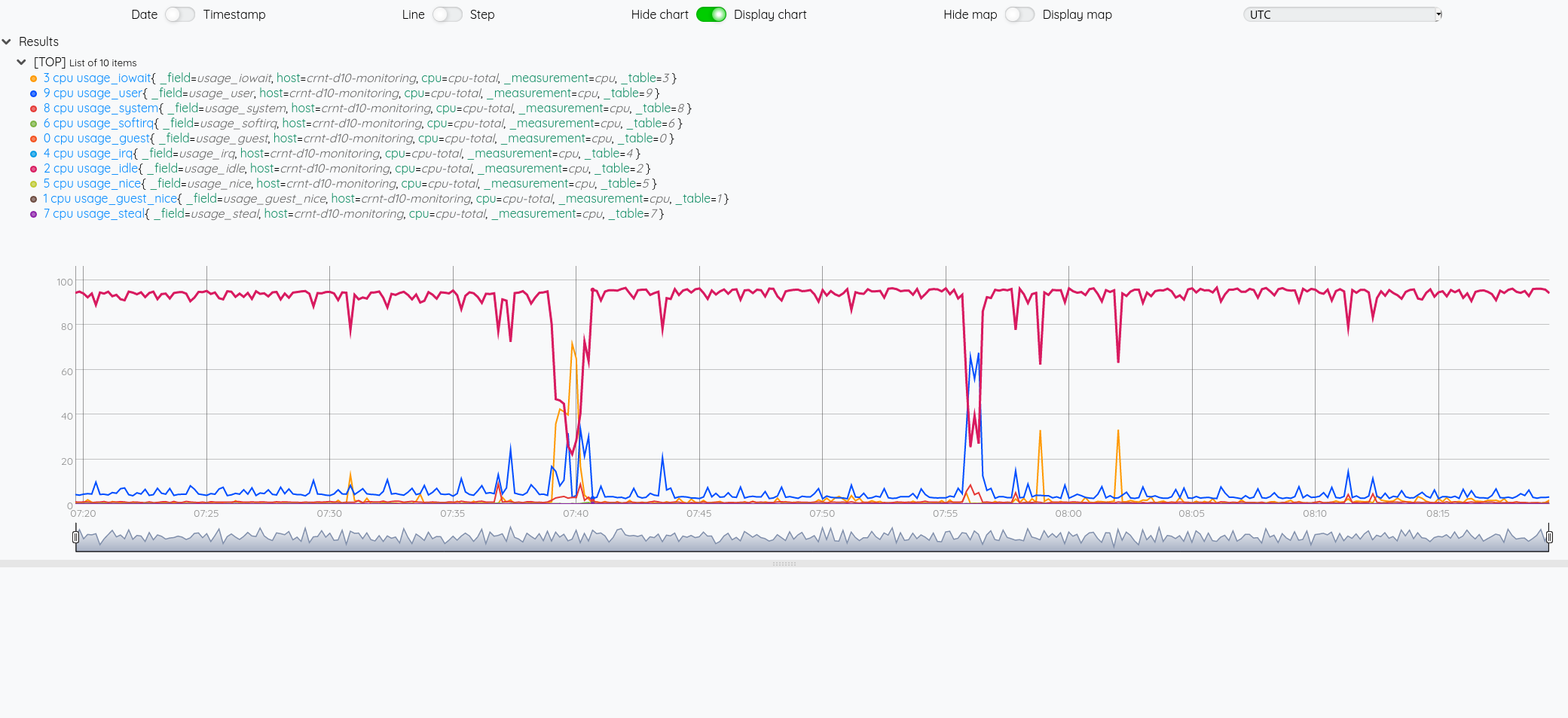
On note que la requête flux n’est pas très lisible de par l’encodage des guillemets et de son coté monoligne. On peut améliorer ça avec une variable STRING en multi-ligne :
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
<'
from(bucket: "crntbackup")
|> range(start: -1h, stop: now())
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> aggregateWindow(every: 1s, fn: mean, createEmpty: false)
|> yield(name: "mean")
'>
'fluxquery' STORE
# Paramètres de la fonction INFLUX.FLUX avec la requête flux (la variable fluxquery) et les informations de connection à InfluxDB 2.x
{ 'flux' $fluxquery 'org' "myOrganisation" 'token' "myToken" 'url' "http://url.to.influxdb2:9999" }
INFLUXDB.FLUX
# Sauvegarde de la liste dans une variable cpu
'cpu' STORE
# Affichage de la liste de GTS
$cpu
On y gagne en lisibilité et pas besoin d’encoder les guillements !
Dans les deux cas, on obtient :
On note d’ailleurs que les méta-données (nom du measurement, nom du champ et les tags sont repris sous la forme de labels)
Contraiement à la requête en InfluxQL, on ne peut passer qu’une requête à la fois mais ce qui permet d’avoir directment une liste de GTS puis la GTS. On n’a plus une liste de liste de GTS.
Si on veut comme précédemment avec InfluxQL afficher la courbe du CPU idle:
# Utilisation du string multi-ligne pour améliorer la lisibilité de la requête FLUX et sauvegarde dans une variable fluxquery.
<'
from(bucket: "crntbackup")
|> range(start: -1h, stop: now())
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> aggregateWindow(every: 1s, fn: mean, createEmpty: false)
|> yield(name: "mean")
'>
'fluxquery' STORE
# Paramètres de la fonction INFLUX.FLUX avec la requête flux (la variable fluxquery) et les informations de connection à InfluxDB 2.x
{ 'flux' $fluxquery 'org' "myOrganisation" 'token' "myToken" 'url' "http://url.to.influxdb2:9999" }
INFLUXDB.FLUX
# Sauvegarde de la liste dans une variable cpu
'cpu' STORE
# Affiche la 7eme liste (incide 6)
$cpu 6 GET
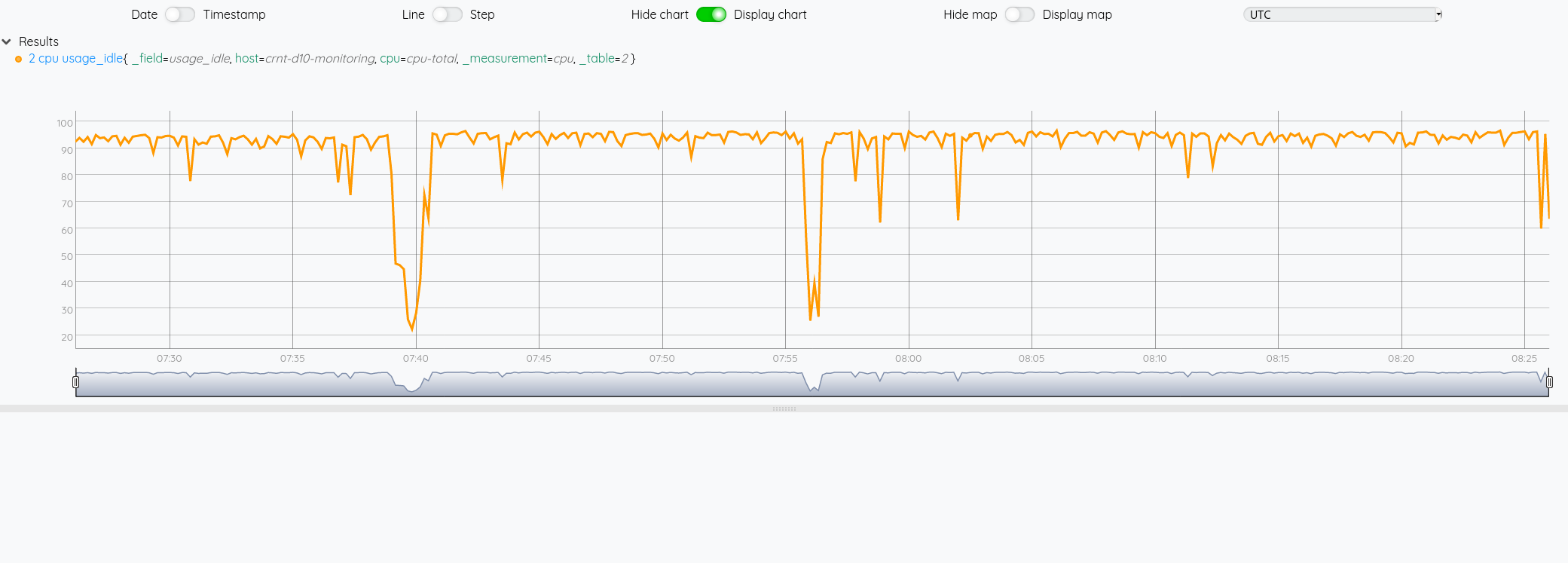
Je ne vais pas pousser l’exemple plus loin, il ne tient qu’à vous de poursuivre la manipulation de vos données en WarpScript. On pourrait se demander où mettre la limite entre la requête en Flux/InfluxQL et les manipulations à faire en WarpScript ensuite. Tout dépendra de votre cas d’usage.
Sauvegarder des données dans InfluxDB
Pour le moment, nous avons requêté des données stockées dans InfluxDB 1.x ou 2.x ; mais nous pouvons très bien imaginer un cas où les données sont issues d’une autre source de données ou bien ont été générées avec WarpScript mais qu’on veuille les persister dans InfluxDB 1.x ou 2.x
Reprenons mon exercice de compatbilité et de prédictions et sauvegardons tout ça dans InfluxDB.
Pour rappel, nous avons fait ceci :
'<read_token>' 'readToken' STORE
'<wrtie_token>' 'writeToken' STORE
# Récupération des dépenses sous la forme d'une série (GTS)
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
# Récupération du chiffre d'affaires mensuel sous la forme d'une série (GTS)
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
# Calcul du résulat mensuel
$revenue $exp -
# Stockage de la série obtenue dans une série appelée "result"
"result" RENAME
{ "company" "cerenit" } RELABEL
$writeToken UPDATE
# Récupération du résultat mensuel sous la forme d'une série (GTS)
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
Si je veux sauvegarder une série dans un measurement influxdb :
# Version 1.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' true 'url' "http://url.to.influxdb:8086" 'measurement' "result" 'db' "crntcompta" 'password' "myPassword" 'user' "myUser" }
'params' STORE
# Utilisatoin de la fonction INFLUXDB.UPDATE qui prend la variable 'params' pour les paramètres de connection et une GTS ou liste de GTS pour les données à sauvegarder
$result $params INFLUXDB.UPDATE
# Version 2.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' false 'url' "http://url.to.influxdb:9999" 'measurement' "result" 'bucket' "crntcompta" 'token' "myToken" 'org' "myOrganisation" }
'params' STORE
$result $params INFLUXDB.UPDATE
Coté InfluxDB, on retrouve bien nos données :
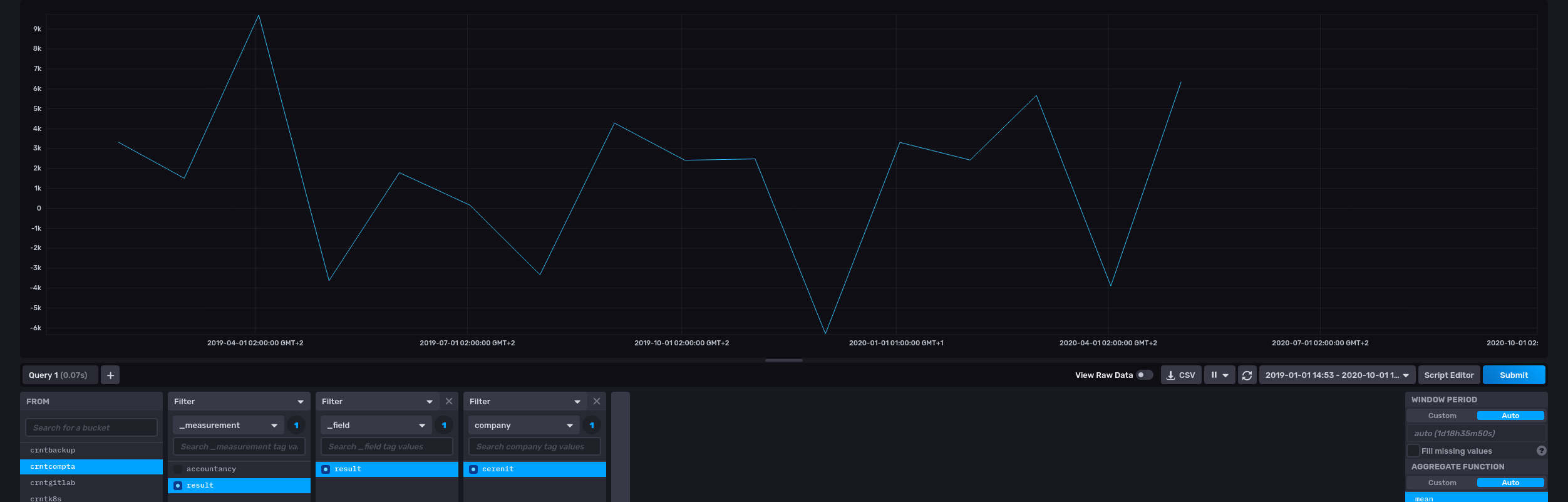
Si au contraire, je veux regrouper plusieurs valeurs dans un même measurement InfluxDB, il faut passer une liste de GTS à INFLUXDB.UPDATE.
# Version 1.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' true 'url' "http://url.to.influxdb:8086" 'measurement' "accountancy" 'db' "crntcompta" 'password' "myPassword" 'user' "myUser" }
'params' STORE
# Passage d'une liste de GTS plutôt qu'une seule série de l'expemple précédent
[ $result $revenue $exp ] $params INFLUXDB.UPDATE
# Version 2.x
# Création d'une MAP 'params' avec les informations de connection à l'instance InfluxDB
{ 'v1' false 'url' "http://url.to.influxdb:9999" 'measurement' "accountancy" 'bucket' "crntcompta" 'token' "myToken" 'org' "myOrganisation" }
'params' STORE
# Passage d'une liste de GTS plutôt qu'une seule série de l'expemple précédent
[ $result $revenue $exp ] $params INFLUXDB.UPDATE
Coté InfluxDB, on retrouve bien nos données :
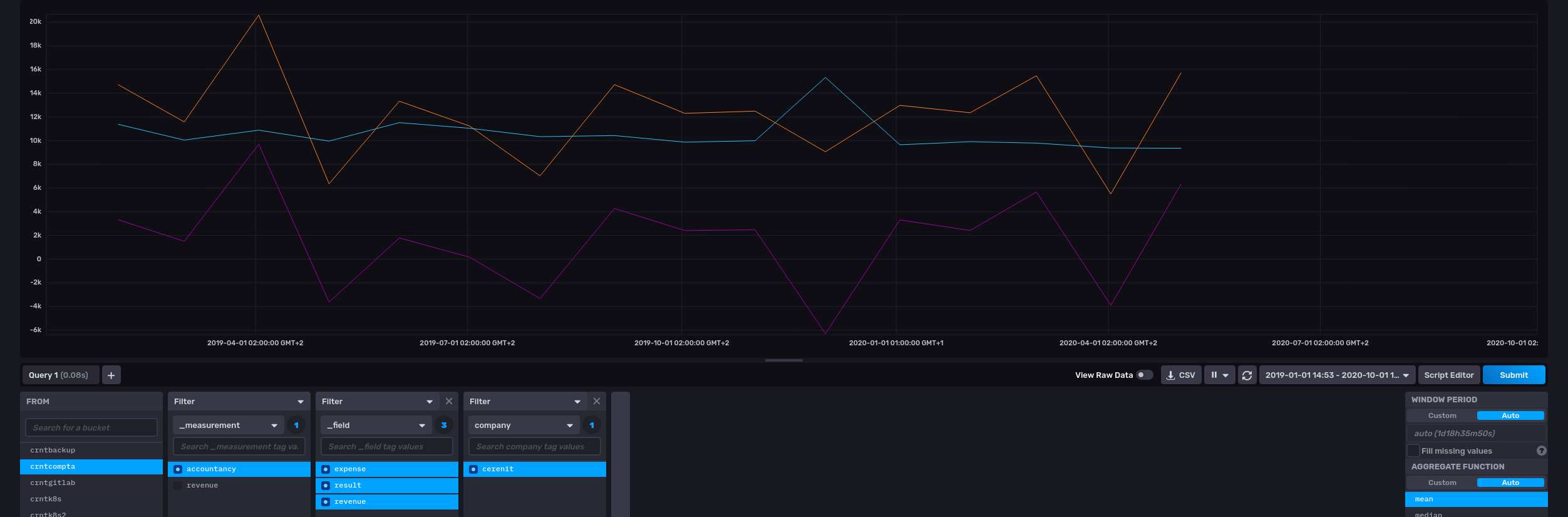
On arrive au bout de ce billet, nous avons vu que nous pouvons :
- En WarpScript, requêter des données stockées dans InfluxDB 1.x et 2.x
- En WarpScript, manipuler des données issues de Warp 10 puis les stocker dans InfluxDB 1.x et 2.x
Nous pourrions aller plus loin avec :
- des scénarios d’enrichissement de données en s’interfaçant par ex avec des données de sources SQL (référentiels, etc)
- des scénarios d’analytics en croisant des données issues de Warp10, InfluxDB ou d’autres sources de données (bases SQL, etc)
- des scénarios de projection en appliquant par exemple les algorythmes de machine learning sur des données issues d’InfluxDB
- …
WarpScript semble ainsi permettre d’avoir un langage de manipulation de séries temporelles multi-sources et d’offrir une expérience unifiée de manipulatoin de ces données. Dans les prochains billets, nous explorerons d’avantage la partie visualisation et alerting.
Web, Ops & Data - Septembre 2020
podman timezone grafana dashboard terraform sécurité terrascan terracost nvidia arm cni csi network storage cilium calico longhorn portworx openebs rancher python gke warp10 influxdb data-engineer date-scientist sqlCloud
- terrascan : terrascan va scanner vos fichiers terraform et les valider contre 500+ règles de sécurité (au format Open Policy Agent) afin d’identifier les éventuels problèmes de sécurité. L’outil supporte AWS, GCP et Azure.
- infracost : estimez le coût de vos projets terraform à l’heure ou au mois. Il est même possible de faire apparaitre les évolutions de vos coûts d’infra lors d’une MR/PR. A défaut d’être forcément précis, cela pourra au moins donner une idée et permettra peut être de sensibiliser les développeurs et/ou les clients aux évolutions de couts de leurs projets.
Code
- All Python versions before 3.6 are now totally unsupported : Python 2 n’est plus supporté depuis le début de l’année - c’est au tour de Python 3.5 de ne plus l’être depuis le 13 sept. Pour Python 3.6, ce sera décembre 2021.
- nackjicholson/aiosql : juste milieu (?) entre du SQL brut et un ORM, aiosql semble permettre d’associer une requête SQL à une fonction pour une manipulation assez simple ensuite dans le code par la suite.
Container et orchestration
- Tick-tock. Does your container know what time it is? : le fichier
/etc/localtimeest en général défini dans votre image de base et peut ne pas convenir à votre fuseau horaire. Podman permet de surcharger cela en précisant à l’exécution ou via un point de configuration le fuseau horaire à utiliser. Pratique plutôt que de modifier le fichier via votre Dockerfile. - Kubernetes Storage Performance Comparison v2 (2020 Updated) : une comparaison des solutions de stockage rook/Ceph, Azure PVC, Azure hosyPath, GlusterFS, Portworx, OpenEBS MayaStor et Rancher Longhorn. La conclusion se termine par un trio de tête emmené par Portworx, OpenEBS et Longhorn. Ce dernier étant plus adapté pour des besoins légers de stockage.
- New GKE Dataplane V2 increases security and visibility for containers & Google announces Cilium & eBPF as the new networking dataplane for GKE : GKE va utilise Cilium comme CNI pour son data plane v2 (il utilise actuellement Calico comme CNI si les network policy sont activées lors de la création de votre cluster)
- Benchmark results of Kubernetes network plugins (CNI) over 10Gbit/s network (Updated: August 2020) : pour des petits clusters, la solution la plus performante serait/resterait Calico et Cilium ne serait efficace que pour des gros clusters.
(Big) data
- #19. Lucien Fregosi - Hugo Larcher - Erika Gelinard - Dessine moi un data engineer : Pour cette saison 2 de DataBuzzWord, des réflexions intéressantes autour du Data Engineer / Data Scientists, le Data Engineer qui fait du Build/Run, les pipelines & job as a service et de l’importance de simplifier / déporter le run pour que le Data Engineer et a fortiori le Data Scientist se concentrent sur leurs pipelines ou leur exploitation et gérer moins d’infrastructure.
Hardware
- NVIDIA to Acquire Arm for $40 Billion, Creating World’s Premier Computing Company for the Age of AI : Nvidia sur le point d’acheter ARM pour en faire un leader des processeurs (CPU/GPU) et de l’IA. On voit que le sujet est politique dans le soin qui est apporté au site ARM de Cambridge et de son développement à venir.
Time Series
- InfluxDB OSS 2.0 General Availability Roadmap : un bon résumé sur les avancées d’Influx 2.0 OSS et la transition 1.x vers 2.x ; Début septembre, j’étais sceptique quand même avec le retour du stockage et du requêtage da la V1 dans la branche v2 (cf la PR “Port TSM1 storage engine”) et ce à un mois de la date de release prévue annoncés aux Influxdays de Londres (ie fin septembre). Au final, la version 2.0 OSS et Entreprise auront les feautres “frontend” de la V2 (Tasks, Dashobards, etc) mais uniquement le moteur de stockage de la V1. Si je comprends le besoin pour ne pas perdre leurs clients dans la migration, c’est un écart de plus entre les version OSS/Entreprise et la version Cloud. Les couches hautes (API, UI, fonctionnalités type Task/Dashboards/…) seront commmunes mais sous le capot (stockage, ingestion), cela diffère. On peut raisonnablement se demander si c’est une phase intermédiaire avant une migration ultérieure sur le moteur de stockage de la 2.0 quand InfluxData aura plus de recul sur le sujet ou bien si les projets Cloud et OSS/Entreprise ne vont pas diverger significativement à moyen terme. Ceux qui ont commencé à alimenter leur base InfluxDB 2.0 sur la base des versions beta devront repartir de zéro du fait de cette incompatibilité de version de moteur de stockage.
- Popular community plugins that can improve your Grafana dashboards : une collection de plugins Grafana pour améliorer vos dashboards.
- September 2020: Warp 10 release 2.7.0, ready for FLoWS : la version 2.7 de Warp 10 est disponible et est la première version qui va supporter FLoWS, la syntaxe fonctionnelle alternative à WarpScript. Pour en savoir plus sur FLoWS, je vous renvoie à l’édition 5 du Paris Time Series Meetup avec la présentation de FLoWS. D’autres améliorations font partie de cette release, tant d’un point de vue fonctionnalités que performances.
Web, Ops & Data - Juillet 2020
terraform acme letsencrypt influxdb influxdays questdb timeseries rancher suse stash kubedb maesh warp10 warpscript flows ptsm rgpd safe-harbor données personnelles grafana fluxCloud
- Gestion automatisée de certificats TLS avec Let’s Encrypt via Terraform et Ansible sur AWS : exemple d’utilisation du provider
acmeavec terraform pour la génération et le déploiement d’un certificat Let’s Encrypt dans un contexte AWS. - Custom Variable Validation in Terraform 0.13 : introduite en version expérimentale en 0.12.20, la validation personnalisée de variable sera stable en v ersion 0.13. De quoi valider ses ressources plus simplement.
- Avec l’acquisition d’OpenIO, OVHcloud se donne pour ambition de créer la meilleure offre de Stockage Objet du marché : acquisition d’OpenIO par OVHCloud. OpenIO fournit une solution de stockage compatible S3 et apparemment OVHVloud et OpenIO étaient habituées à travailler ensemble notamment autour de Swift (le stockage objet dans Openstack). Intéressant de voir ce type d’acquisition en Europe d’une part et de voir qu’OVHCloud remonte dans la chaine de valeur et rentre de plus en plus dans le monde du logiciel. A suivre !
Container et orchestration
- Announcing Maesh 1.3 : Maesh continue son chemin et ajoute la capacité de surveiller des namespace particuliées (en plus de pouvoir en ignorer), le support du lookup des ports (http -> 80), le support de CoreDNS chez AKS et d’autres améliorations encore.
- Electro Mpnkeys #9 – Traefik et Maesh : de l’ingress au service mesh avec Michael Matur : si vous voulez en savoir plus sur Traefik et Maesh, je vous conseille cet épisode (et les autres) du podcast Electro Monkeys.
- Introducing Traefik Pilot: a First Look at Our New SaaS Control Platform for Traefik : Containous, la société derrière Traefik, Maesh et Yaegi sort son offre SaaS pour piloter et monitorer ses instances traefik. Un système de plugins pour les middleware fait également son apparaition. Il faut une version 2.3+ (actuellement en RC) de Traefik pour bénéficier de cette intégration.
- Relicensing Stash & KubeDB : KubeDB, l’operateur de bases de données et Stash, l’outil de sauvegarde se cherchent un modèle économique et changent de licence. La version gratuite, avec code source disponible, reste disponible pour des usages non commerciaux (voir les détails de la licence pour une slite exacte). Pour un usage commercial, il faudra passer par la version Entreprise qui apporte aussi des fonctionnalités supplémentaires.
- Suse to acquire Rancher : Suse était sorti de mon radar; c’est donc pour moi l’entrée (ou le retour ?) de Suse dans le monde de kubernetes et de son orchestration. Est-ce une volonté d’aller prendre des parts de marchés à Redhat/Openshift ou de faire face à des rumeurs telles que Google en discussion pour acquérir D2IQ (ex Mesoshphère) ? A voir si cette acquisition va être un tremplin pour Rancher et ses différents projets (rke, rio, k3s, longhorn, etc) comme l’indique son CTO ou pas.
Time Series
- QuestDB nabs $2.3M seed to build open source time series database : QuestDB, historiquement issue du monde du trading à haute fréquence, commence à faire parler d’elle (notamment en récupérant un des DevRel d’InfuxData David G Simmons et vient de lever 2.3 millions de dollars. Elle a une approche SQL sur le traitement des données, se veut performante. A voir si elle reste une spécialiste de la série temporelle financière ou si elle parvient à s’ouvrir à d’autres usages.
- InfluxDays 2020 Virtual Experience : les vidéos et supports des InfluxDays sont disponibles.
- Paris Time Series Meetup #5 : De retour des InfluxDays et FLoWS : Résumé des keynotes autour des annonces produits des InfluxDays et présentation de FLoWS, la nouvelle syntaxte proposée par SenX pour interagir avec Warp10, en alternative à WarpScript. Le but est de faciliter la courbe d’apprentissage autour de Warp10. FLoWS est déjà disponible sur la sandbox et sera disponible cet été ou à la rentrée dans la version 2.7.0 de Warp10.
- Grafana v7.1 released: New features for InfluxDB and Elasticsearch data sources, table panel transformations, and more : grosse nouvelle version mineure de Grafana avec son lots d’amélioration et de nouveautés. Je vous laisse lire l’annonce.
- How to Build Grafana Dashboards with InfluxDB, Flux and InfluxQL : A l’occasion de la sortie de Grafana 7.1 qui apporte le support de Flux, présentation des nouveaux modes d’interaction entre Grafana et InfluxDB
Vie privée & données personnelles
Le Privacy Shield, l’accord entre l’Europe et les USA sur le transfert des données des Européens vers les USA (ou les sociétés américaines) vient d’être invalidé par la cour de justice européene. Les flux “absolument nécessaires” peuvent continuer à se faire pour le moment et la cour a validé “les clauses contractuelles types” définies par la Commission Européenne pourront être utilisées par les entreprises. Néanmoins, pour s’y référer, il semble qu’il faut vérifier que l’entreprise protège effectivement les données. Je vous invite à contacter votre juriste ou avocat pour mieux appréhender les impacts de cette invalidation si vous utilisez les plateformes cloud et des services dont les entreprises sont basées aux USA. En tant qu’individu, il peut être intéressant de se poser des questions également. N’étant pas juriste, je vais donc limiter mon interprétation ici et vous laisse lire les liens ci-dessous.
- La justice européenne sabre le transfert de vos données vers les USA à cause de la surveillance de masse
- L’accord sur le transfert de données personnelles entre l’UE et les Etats-Unis annulé par la justice européenne
- CJEU Judgment - First Statement
- L’accord sur le transfert de données personnelles avec les États-Unis invalidé par la justice européenne
- Invalidation du « Privacy shield » : la CNIL et ses homologues analysent actuellement ses conséquences
- Statement on the Court of Justice of the European Union Judgment in Case C-311/18 - Data Protection Commissioner v Facebook Ireland and Maximillian Schrems
- The End of the Privacy Shield Agreement Could Lead to Disaster for Hyperscale Cloud Providers
Web, Ops & Data - Juin 2020
terraform telegraf kubernetes operator rancher longhorn raspberrypi prometheus victoria-metrics monitoring influxdb warp10 forecastJe ne peux résister à mentionner la sortie de l’épisode 100 du BigDataHebdo, podcast où j’ai le plaisir de contribuer. Pour ce numéro spécial (épisode 100 et 6 ans du podcast), nous avons fait appel aux membres de la communauté pour partager avec nous leur base de données favorite, la technologie qui les a le plus impressionée durant ces 6 dernières années et celle qu’ils voient comme majeure pour les 6 prochaines années. Allez l’écouter !
Cloud
- Announcing the Terraform Visual Studio Code Extension v2.0.0 : Hashicorp prend en main le support de l’extension Terraform pour VSCode, en sort une nouvelle version et apporte différentes améliorations comme un meilleur support de Terraform 0.12 et l’utilisation du Terraform Language Server.
Container et orchestration
- Introducing the Telegraf Operator: Kubernetes Sidecars Made Simple : Présentation de l’operator kubernetes pour telegraf qui permet de déployer un agent telegraf sous la forme d’un sidecar dans un pod et de récupérer les métriques associés.
- Kubernetes 1.18.x officiellement disponible chez OVHCloud
- Longhorn Simplifies Distributed Block Storage in Kubernetes : Rancher vient de sortir la version 1.0 de Longhorn. C’est une solution de stockage pour Kubernetes que l’on peut utiliser avec ou sans Rancher. Il faut la voir comme une solution de stockage légère et simple à mettre en oeuvre. Un système de réplication permet d’éviter les pertes de données et d’amélioer la durabilité des données. Des fonctionnalités de backup/restore existent également. Elle semble plus simple à mettre en oeuvre que Rook/Ceph par ex mais sera moins complète que ce dernier.
- Understanding Kubernetes & Understanding Istio : Aurélie Vache réalise des sketchnotes pour vulgariser Kubernetes et Istio. Un joli travail de vulgarisation.
IoT
- 8GB Raspberry Pi 4 on sale now at $75 : Le Raspberry Pi 4 arrive en version 8Go de RAM, Raspberry PI OS arrive en 64 bits, le support du boot sur usb arrive aussi (adieu la SDCard) et plein d’autres choses. Le tout au prix de 75$.
Ops
- Sismology: Iguana Solutions’ Monitoring System : retour d’expérience sur une plateforme de monitoring initiée sur Prometheus et qui évolue vers VictoriaMetrics en prenant les aspects de stockage à long terme, le multi-tenant et la haute disponibilité de la plateforme.
Time Series
- Release Announcement: InfluxDB 2.0.0 Beta 12 : une beta de plus avec l’ajout notamment d’
influx stackspour faire du CRUD sur des groupes de ressources InfluxDB (dashboard, labels, tasks, etc). - Warp 10, The Most Advanced Time Series Platform, now provides multi-architecture docker images. : vous pouvez donc déployer des images docker warp10 sur des plateformes amd64/armv7/arm64.
- May 2020: Warp 10 release 2.6.0 : Pleins d’améliorations et de correctifs et notamment la capacité de dialoguer directement avec Warp10 via le protocole Protobuf ou via Arrow.
- Time series forecasts in WarpScript : Présentation de l’extension Warpscript permettant d’appliquer des algorithmes de prévisions (ARIMA, SARIMA, HOLTWINTERS, etc) sur des séries temporelles. Précision: il s’agit d’une extension propriétaire mais vous pouvez l’évaluer sur la sandbox Warp10 mise à disposition par SenX.
Web, Ops & Data - Avril 2020
traefik scaleway kubernetes telegraf cassandra kafka confluent helm influxdb warp10 timescaledb docker compose apache-pulsar pubsub deprek8 conftest opa raspberrypi gitlab sidecarCode et Outillage
- 18 GitLab features are moving to open source : Gitlab va rendre disponible dans sa version Open Source 18 fonctionnalités de sa version payante. C’est un peu la lutte avec Github et ses Github Actions ou ses dernières évolutions tarifaires.
Container & orchestration
- Announcing the Compose Specification : Docker Inc vient de lancer une spécificiation officielle autour de Compose (celle derrière les
docker-compose.yml) pour la rendre plus “cloud native” et plus générique avec une extension au provider cloud d’une part et d’autre part à des solutions comme kubernetes ou Amazone ECS par ex. - Announcing Traefik 2.2, ainsi que la version Entreprise TraefikEE 2.1 basée dessus : on notera le retour du support des annotations pour gérer les Ingress, le support de l’UDP (en plus de HTTP et TCP), le support d’Elastic APM, le support des stores KV (Consul, Etcd, Redis, etc) et le Dark Mode.
- Scaleway Kubernetes Kapsule : l’offre managée kubernetes de Scaleway est disponible. Dommage que les CPU des profils de machine
DEV*soient surprovisionnés et qu’il faille envisager des profilsGP*pour avoir des performances correctes. L’offre est du coup moins compétitive en termes de prix pour des petits clusters. - Kubernetes 1.18 : Fit & Finish : une version de consolidation
- How to detect outdated Kubernetes APIs : présentation de Deprek8 et de Conftest pour vous permettre d’évaluer les ressources kubernetes pour lesquelles vous n’êtes pas à jour au niveau des API.
- Helm 3.2.0 avec un correctif de sécurité sur les versions 3.0.x et 3.1.x et d’autres améliorations (comme le retour de certaines fonctionnalités non encore migrées depuis la 2.x)
- Cortex v1.0 released: The highly scalable, fast Prometheus implementation is generally available for production use : la solution de monitoring distribuée et avec un stockage de long terme basée sur Prometheus arrive en version 1.0. C’est l’occasion de se repencher sur son architecture et son fonctionnement.
- Build your very own self-hosting platform with Raspberry Pi and Kubernetes : une série d’articles pour déployer un cluster kubernetes sur vos raspberrypi avec la distributions k3s et y déployer différentes applications.
- Rook v1.3: Storage Operator Improvements : si vous n’êtes pas dans un environnement cloud, il y a de fortes chances pour que vous utilisiez Rook. La version 1.3 vient de sortir et apporte son lot d’améliorations.
- Sidecar container lifecycle changes in Kubernetes 1.18 : dans la version 1.19, le cycle de vie des sidecars dans kubernetes sera améliorée. Ainsi, ils démarreront avant le conteneur principal et s’arrêteront après. Le billet revient sur les problèmes existant et comment ce nouveau cycle de vie va améliorer la situation.
(Big) Data
- Confluent Raises $250M and Kicks Off Project Metamorphosis : Confluent, la soéciété éditrice de la Confluent Platform et d’Apache Kafka, vient de lever 250 millions de dollars et annonce le projet Metamorphosis et prévoit des annonces tous les mois sur Apache Kafka, Confluent Platform et ce projet à compter du mois de Mai. On en reparlera très certainement sur BigData Hebdo.
- Cassandra: The Definitive Guide, 3rd Edition : nouvelle édition de l’ouvrage de référence sur Cassandra, mis à jour notamment pour Cassandra 4.0 (version à venir)
- Announcing Kafka-on-Pulsar: bring native Kafka protocol support to Apache Pulsar : On en parle dans le prochain épisode de BigData Hebdo, mais Pulsar est une plateforme vraiment intéressante (Pulsar 101 en français ou en anglais) et les équipes d’OVHCloud viennent de publier un connecteur qui permet d’utliser l’API Kafka mais que les messages soient stockés dans Pulsar. Il existe aussi une vidéo sur Kafka on Pulsar et un article sur le blog d’OVHCloud.
Time Series
- Release Announcement: Telegraf 1.14.0 : 9 nouveaux inputs, 3 nouveaux processors et 1 nouvel output warp10 sont au programme de cette version. Les versions 1.14.1 et 1.14.2 sont sorties également avec quelques corrections.
- Release Announcement: InfluxDB 1.8.0 with Long-Awaited Features : la branche 1.x d’InfluxDB se voit donc dotée d’une version récente de flux qui se veut “production ready” et les endpoints d’InfluxDB 2.x sont aussi disponibles. Ce qui permet d’utiliser les nouveaux clients officiels InfluxDB prévus pour la 2.x d’une part et de faire des requêtes en Flux d’autre part.
- Release Announcement: InfluxDB 2.0.0 Beta 9 : mise à jour de Flux, autocomplétion flux dans l’éditeur de requêtes et amélioration de la CLI.
- InfluxDB Templates: Easily Share Your Monitoring Expertise : le billet a pour intérêt de présenter des bonnes pratiques sur la réalisation de templates InfluxDB. Pour rappel, les templates InfluxDB sont des “ressources” que l’on peut déclarer, exporter et importer dans une instance InfluxDB 2.x. Cela concerne des variables, labels, tasks, dashboards, alertes, etc.
- April 2020: Warp 10 release 2.5.0 : La version 2.5 de Warp10 apporte notamment un Accelerator c’est à dire un cache en mémoire pour les versions standalones. D’autres corrections et améliorations font également partie de cette release.
- WarpScript ❤️ Kafka Streams : si vous utiliser Kafka Streams et que vous voulez utiliser Warpscript pour consommer, processer et envoyer des données vers Kafka, c’est possible.
- Forecasting : Microsoft publie des exemples et des bonnes pratiques autour de la prévision à base de séries temporelles. Il y a des exemples en Python / R et quelques exemples avec Azure-ML.
- TimescaleDB 1.7: fast continuous aggregates with real-time views, PostgreSQL 12 support, and more Community features : Nouvelle version de TimeScaleDB apportant la compatibilité avec Postgresql 12.x, des aggrégats en temps réel et des fonctionnalités de gestion de données (réordonnancement et rétention) de la version Entreprise sont maintenant disponibles dans la version Community.
Web
- jQuery 3.5.0 Released! : une faille XSS a été identifiée sur
jQuery.htmlFilterpour toutes les versions inférieures à 3.5.0 ; il est vivement encouragé de mettre à jour vos sites. Pour le reste, je vous renvoie à la lecture de l’article.
