Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Web, Ops, Data et Time Series - Octobre 2021
postgresql timeseries bi datatask dbt metabase singer timescale influxdb quasardb vector nomad clever-cloud yield pivot warp10 flows vscode kapacitor chronograf telegraf clickhouseBI
- Smart Data Analytics : Exploration des données comptables : pour changer des outils de séries temporelles, je me suis livré au même exercice d’ingestion et de traitement des FEC avec la Smart Data Analytics (SDA) de DataTask. Basée sur singer, dbt et metabase, la SDA permet via une Web UI de définir son flow d’ingestion et de transformation. Une fois ces transformations réalisées, il ne reste plus qu’à explorer les données avec Metabase et produire ses dashboards.
Code
- vscode.dev : l’ère de l’IDE dans le navigateur continue après gitpod ou githuab codspaces, c’est au tour de vscode.dev qui permet d’avoir une IDE dans son navigateur. Affaire à suivre…
Observabilité et monitoring
- Vector 0.17.0, Vector 0.17.1, Vector 0.17.2 & Vector 0.17.3 avec l’adaptive concurrency qui permet de gérer le “back pressure” pour les destinations accessibles via HTTP, et pour les sources une gestion simplifiée pour le décodage d’éléments et leur “framing”.
- Vector Remap Language : extension Vector pour VSCode
Orchestration & conteneurs
- damon, un dashboard pour nomad en ligne de commande.
- Announcing HashiCorp Nomad 1.2 Beta : ajout des “System Batch” qui sont des (petits) jobs globaux au cluster, des améliorations de l’interface et l’ajout des Nomad Pack, une sorte de catalogue d’applications prêtes à être déployées dans votre cluster.
SQL
- PostgreSQL 14 Released! ou en français PostgreSQL 14 ou un thread twitter pour découvrir les nouveautés de cette version : amélioration du support de JSONB, type multirange, fonctions autour des dates, etc.
Sécurité
- Popular NPM library hijacked to install password-stealers, miners : analyse de la librairie ua-parser-js compromise dans ses version 0.7.29, 0.8.0 et 1.0.0 avec l’ajout un mining de crypto et un voleur de mot de passes. Le passage en version 0.7.30 / 0.8.1 et 1.0.1 est à faire dans les plus brefs délais. Pour les dépendances indirectes, il est possible d’ajouter dans son fichier
package.json:"resolutions": { "ua-parser-js": "^0.7.30" }via Security issue: compromised npm packages of ua-parser-js (0.7.29, 0.8.0, 1.0.0) - Questions about deprecated npm package ua-parser-js
Time Series
Annonces & Produits :
- InfluxDB OSS 2.0.9
- InfluxDB OSS 1.8.10
- InfluxDB Entreprise 1.9.5 - avec des fixes sur l’utilisation mémoire et les index TSI :sourire_narquois:
- Telegraf 1.20.2 (avec un fix de memory leak sur le parser influx notamment)
- Kapacitor 1.6.2
- QuasarDB 3.10.0 Stable Released : Nouvelle version de la base QuasarDB avec son lot d’améliorations et de corrections ; pour une présentation de QuasarDB, voir Time Series France - Edition 2 - QuasarDB, les séries temporelles appliquées à la finance & aux transports.
- Announcing the new Timescale Cloud, and a new vision for the future of database services in the cloud et le thread twitter associé : Timescale partage sa vision de ce que doit être une base managée et de la developer experience qu’elle doit offrir. Timescale indique également avoir 3 millions de bases actives par mois (très loin devant les derniers chiffres d’InfluxData ; environ 6 fois mais faut-il encore s’accorder ce qu’est une base: une instance ? un schema ?). Timescale annonce les principes de Timescale Cloud (ex Timescale Forge) qui veut être simple, scalable, connu et flexible. Les deux premiers sont inspirés du monde serverless (découplage compute/storage, auto scalabilité, etc) et les deux derniers du monde de la base de données managiées (du SQL plutôt qu’une API et le fait de bénéficier de tout l’écosystème associé). 10 annonces sont prévues durant le mois d’octobre, quelques-une sont déjà en fin de billet.
- Announcing Time Series on Clever Cloud, with TARDIS, Clever Cloud lance son offre Time Series as a Service, basée sur Warp 10 et avec une compatiblité InfluxQL, PromQL, etc.
- FLoWS ♡ VS Code WarpScript extension 2.0.0 - SenX : nouvelle version de l’extension Warp 10 pour VSCode avec le support de FLoWS et Discovery.
- October 2021: Warp 10 release 2.9.0 : nouvelles capacités (CAPABILITY) autour de fetch & exec, GUARD doit éviter les fuites de données sensibles, ajout support de KML/GML en plus des habituels ajouts de fonctions, améliorations de fonctions et divers corrections de bugs
Articles & Vidéos :
- How NOT to Analyze Time Series : article sympathique sur les erreurs de jeunesse d’analyse de séries temporelles.
- Penser le monde en time series, la nouvelle solution à vos problèmes d’analyse (M.Herberts/Q.Adam) : conférence à DevoxxFR de Quentin et Mathias pour une introduction aux séries temporelles. Intéressant même si un peu au lance pierre sur la fin.
- Les TSDB ne sont pas toujours la bonne solution : approche db ou plateforme ? approche table ou séries ? faible ou forte profondeur d’analyse ? Revue de quelques critères pouvant impacter la façon dont vous manipulez vos séries temporelles.
- TL;DR InfluxDB Tech Tips: Multiple Aggregations with yield() in Flux :
yield()peut être très pratique pour débugguer son code flux mais permet aussi de récupérer le résultat de plusieurs requêtes pour faire des aggrégations - How to Pivot Your Data in Flux: Working with Columnar Data : InfluxDB, contrairement à une RDBMS, stocke ses valeurs via une approche colonne, qui peut dérouter dans un premier temps. Le billet montre comment utiliser
pivot()pour revenir à des manipulations en ligne. - Function pipelines: Building functional programming into PostgreSQL using custom operators : quand un Query Langage (ici SQL) ne suffit plus pour manipuler les séries temporelles, arrivent les fonctions et les opérateurs.
- What is ClickHouse, how does it compare to PostgreSQL and TimescaleDB, and how does it perform for time-series data? : un benchmark très complet pour se faire une opinion et même si ClickHouse n’est pas une TSDB.
Pour le retour sur les InfluxDays North America qui ont lieu cette semaine, ce sera pour un prochain billet ou édition du Time Series France Meetup
InfluxDB et les alertes : Tasks, Checks et Notifications
influxdb timeseries influxdata task flux check notifications kapacitor alertesCérénIT vient de finaliser la migration pour un de ses clients d’un socle InfluxDB/Chronograf/Kapacitor vers InfluxDB2. Ce billet est l’occasion de revenir sur la partie alerting et de la migration de Kapacitor vers des alertes dans InfluxDB2.
Dans le cadre du socle InfluxDB/Chronograf/Kapacitor, le fonctionnement était le suivant :
- Les utilisateurs créent une alerte via l’application métier en définissant un à plusieurs critères d’alertes ; ex: est-ce que l’unité est opérationnelle et est-ce que l’humidité est supérieure à tel taux ou la température supérieure à telle valeur.
- L’application métier traduisait l’alerte en TickScript et enregistrait l’alerte auprès de Kapacitor via son API HTTP
- Kapacitor, en mode streaming, évalue si l’alerte doit être levée ou pas au fur et à mesure de l’arrivée des données
- En cas de seuil franchi, Kapacitor envoie un message à l’application métier via l’API HTTP de cette dernière.
- L’application métier envoie ensuite un mail et/ou un SMS à l’auteur de l’alerte.
Avant d’envisager la migration InfluxDB2, un point de vocabulaire :
- une alerte est globalement composée d’un “check”, d’un endpoint de notiifcation et d’une règle de notification.
- un check est une task simplifiée. Elle permet de définir une requête mono critère, les niveaux de seuils associés (ok, crit, warn, etc) et sa fréquence d’exécution.
- une task est codée flux
- un endpoint de notification : service vers lequel sera envoyé l’alerte: slack, http, etc.
- une règle de notification : les conditions de notifications (ex je passe à un état critique), le check associé, la fréquence d’exécution, le message de notification et le endpoint de notification à utiliser.
Avec la migration InfluxDB2, nous avons voulu maintenir le même mécanisme. Toutefois :
- Les tasks en Flux ne fonctionnent pas en mode streaming, mais uniquement en mode batch et avec une certaine fréquence
- Les checks sont mono-critères et pas multi-critères
Heureusement, la documentation mentionne la possibilité de faire des “custom checks” et un billet très détaillé intitulé “InfluxDB’s Checks and Notifications System” permet de mieux comprendre ce qu’il est possible de faire et donne quelques exemples de code.
Dès lors, il s’agit de :
- développer une tâche “tout en un”, contenant l’ensemble de la logique de l’alerte,
- de conserver un historique des alertes pour permettre d’assurer un suivi des alertes pour l’équipe en charge du projet depuis InfluxDB
- d’être en mesure de notifier l’application métier via son API HTTP
Pour se faire, nous allons nous appuyer sur les mécanismes mis à disposition par Influxdata, à savoir les fonctions monitor.check(), monitor.from() et monitor.notify() et les mécanismes induits.
C’est ce que nous allons voir maintenant :
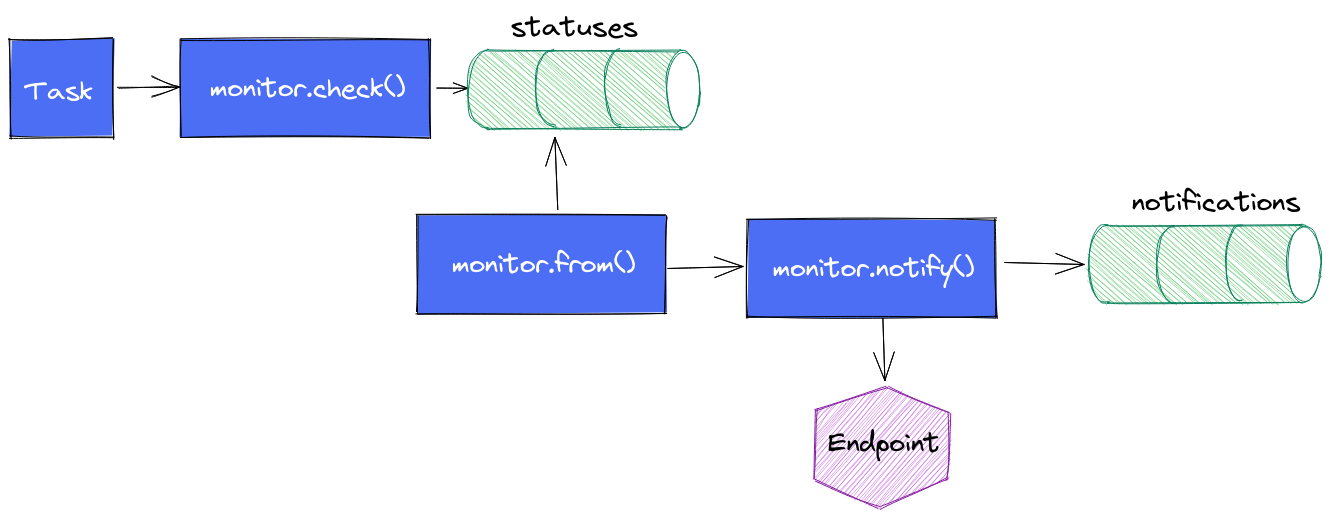
Le cycle de vie d’une alerte est le suivant :
- La task contient une requête en flux plus ou moins complexe en fonction de votre besoin ; ex: quelle est la valeur de la temperature du boitier X depuis la dernière exécution ?
- On appelle
monitor.check()en définissant les informations d’identification du check, le type de check que l’on utilise (threshold, deadman, custom), les différents seuils dont on a besoin, le message à envoyer au endpoint, les données issues de la requête flux. monitor.check()va alors stocker l’ensemble de ces données dans un measurementstatusesdans le bucket_monitoringet il s’arrête là.monitor.from()prend le relais, regarde s’il y a de nouveaux status depuis sa dernière exécution et en fonction des règles de notifications qui ont été définies, il va passer le relaismonitor.notify().monitor.notify()enverra une notification si la règle est validée et il insérera une entrée dans le measurementnotificationsdu bucket_monitoring
Une première version des alertes ont été implémentées sur cette logique. Des dashboards ont été réalisés pour suivre les status et les notifications. Cela fonctionne, pas de soucis ou presque.
Il se peut qu’il y ait un délai entre le moment où l’insertion issue du monitor.check() se fait et le moment où le monitor.from() s’exécute. Si monitor.from() fait sa requête avant l’insertion de données, alors l’alerte ne sera pas immédiatement levée. Elle sera levée à la prochaine exécution de la task, ce qui peut être problématique dans certains cas. Pour une tâche qui s’exécute toutes les minutes, cela ne se voit pas ou presque. Pour une tâche toutes les 5 minutes, ça commence à se voir.
Une version intermédiare de la task est alors née : une fois le monitor.check() exécuté, nous faisons appel à monitor.notify() pour envoyer le message vers le endpoint.
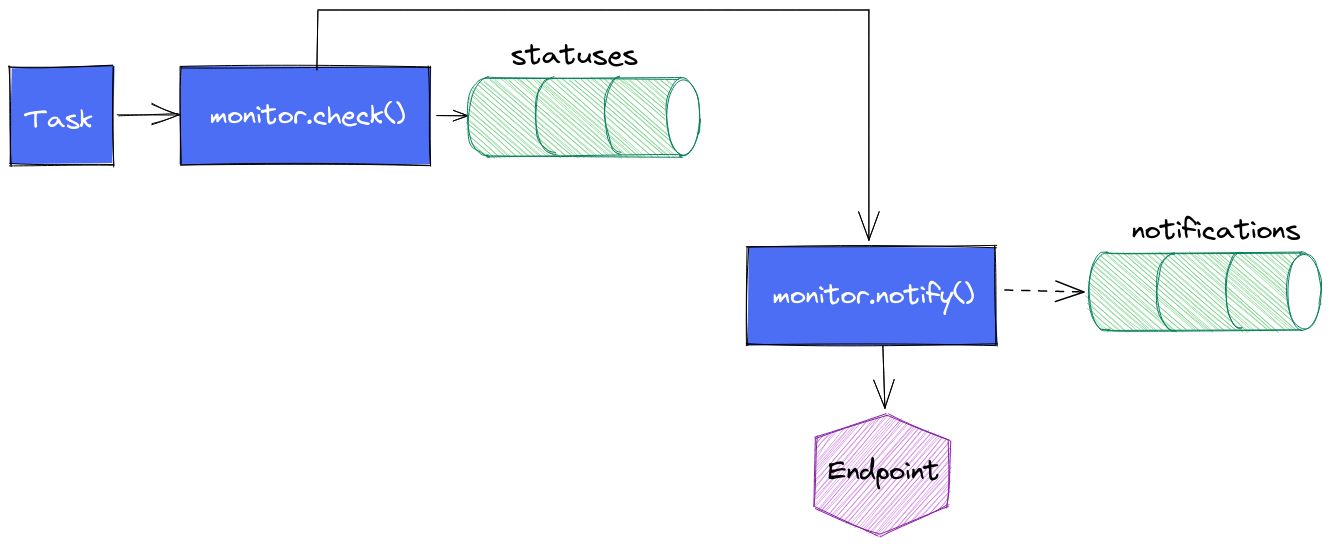
Avantage :
- la notification se déclenche sans délais
Inconvénients :
- cela ne remplit pas le measurement
notificationsde la même façon que précédemment (d’où les pointillés) vu que les données insérées dans le measurementstatusesn’existent pas encore. On perd la visibilité sur les notifications envoyées (mais on a toujours le suivi des statuts ; nous supposons que si on a le statut, alors on sait si la notification a été envoyée) - cela aboutit à un peu de duplication de code sur la gestion des seuils et des messages.
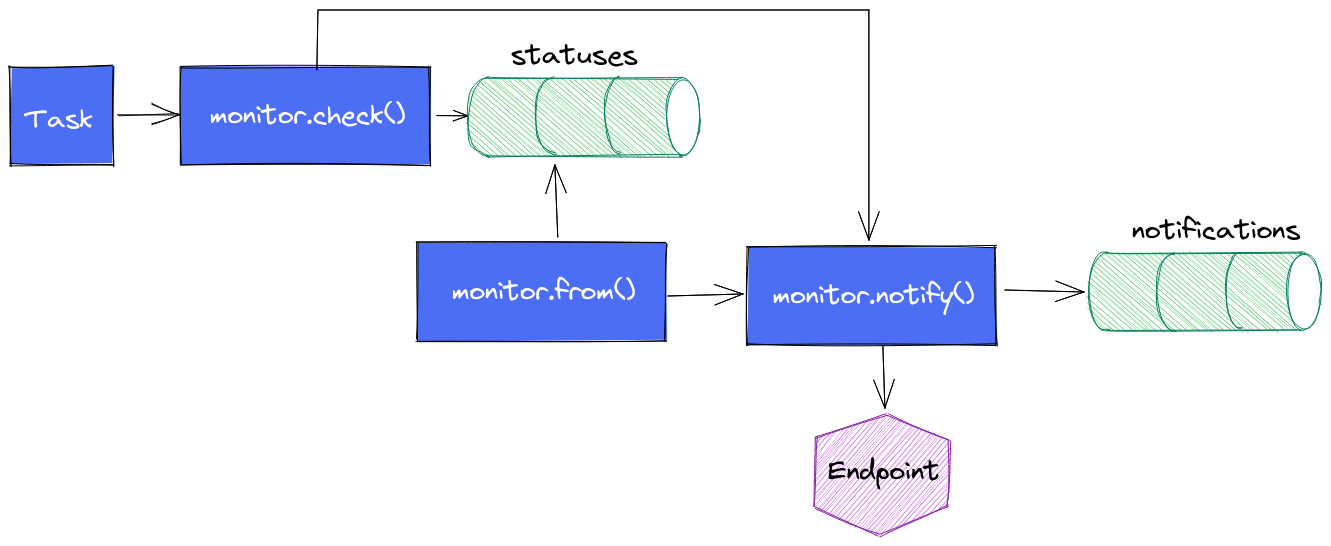
Une variante non essayée à ce stade : elle consiste à faire cette notification au plus tôt mais de conserver le mécanisme de monitor.from() + monitor.notify() pour avoir le measurement notifications correctement mise à jour. A voir si les alertes ne sont pas perturbées par ce double appel à monitor.notify(). Dans le cas présent, c’est l’application métier qui envoie les alertes après que la task InfluxDB ait appelé son API HTTP. Si chaque monitor.notify() en vient à lever une alerte, cela est sans impact pour l’utilisateur. En effet, une fois qu’une alerte est levée, elle est considérée comme levée tant qu’elle n’est pas acquittée. Donc même si la task provoque 2 appels, seul le premier lévera l’alerte et la seconde ne fera rien de plus.
Enfin dernière variante (testée) : s’affranchir complètement de monitor.notify() pour faire directement appel à http.endpoint() et http.post() et faire complètement l’impasse sur le suivi dans notifications.
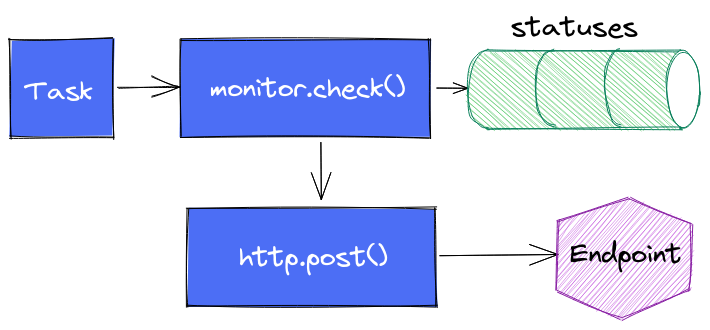
Tout est une histoire de compromis.
En conclusion, nous pouvons retenir que :
- Une alerte est composée d’un check, d’un endpoint de notification et d’une règle de notification
- En 2.0, le principe est que les alertes sont des séries temporelles via le bucket
_monitoringet les measurementsstatusesetnotifications. - Toute personne s’intéressant au sujet doit lire au préalable InfluxDB’s Checks and Notifications System pour bien comprendre les concepts et les rouages.
- Via la UI, les alertes (checks) sont assez basiques (requête monocritère)
- Il est possible de faire des “custom checks” via des tasks en flux
- Les fonctions du package monitor permettent de gérer des alertes
- Les exécutions dans la même task (ou dans des tasks concomittentes) de
monitor.check()etmonitor.from()peuvent conduire à des décalages de levées d’alertes
Web, Ops, Data et Time Series - Mai 2021
hashicorp nomad ovh time leap second gitlab-ci python dbt metabase datatask warp10 monitoring wasm sécurité spectre timescale sql cli readme bootstrap influxdata kapacitor chronografCI
- GitLab CI Python Library : une librairie en python pour créer des pipelines Gitlab-CI plutôt qu’en YAML.
Cloud
Conteneur et orchestration
- Announcing General Availability of HashiCorp Nomad 1.1 : 10 nouvelles fonctionnalités au programme (7 en OSS, 3 en entreprise) : surallocation de mémoire (soft et hard limit), les CPU peuvent être réservés en tant que tel (et non plus uniquement via une fraction), amélioration d’UI, amélioration coté support CSI, distinction entre les “readyness checks” et “liveness checks” au niveau des health checks, exécution distante sur AWS Lambda et AWS ECS (tech preview). Pour la version entreprise : supper des namespaces consul, chargement automatique des licences lors du déploiement de nouveaux noeuds, amélioration de l’autoscaling.
Data
- Hosting SQLite databases on Github Pages : avec une petite pointe de WASM, exemple de pouvoir utiliser une base sqlite en lecture hébergé en statique et un peu de javascript. Intéressant pour mettre à disposition des applications en “lecture seule” et leur scalabilité.
- DataTask pour construire une self-service BI, Revue des principaux concepts de dbt et création d’un premier modèle dans DataTask, DBT : Workflows, Matérialisations et Documentation, Metabase : Les concepts de question, visualisation et dashboard, DBT et la gouvernance des données : tests de validité/qualité et documentation : S&rie de billets sur la mise en place d’une solution de BI avec dbt et Metabase et l’intégration au sein de la plateforme DataTask
- xo/usql (via MACI #42) : une CLI universelle pour des bases SQL comme MySQL, Postgres, SQLite mais aussi des solutions SaaS comme Snowflake, Spanner et même SAP Hana.
Docs
- readme.so (via MACI #42) : Vous ne savez pas quoi mettre dans votre README ? Ce site est fait pour vous et peut aussi vous aider à réorganiser vos fichiers.
Europe
- Souveraineté et cloud, quel rapport ? : remise en perspective du cloud souverain et implications des décisions européenes. La remise en cause du Privacy Shield et les clauses contractuelles font qu’au final : “tout transfert de données personnelles sous juridiction américaine est illégal.”. La reglementation européene, centré sur le respect des droits des personnes permettrait de fiare un protectionnisme reglementaire dans l’idée de développer un écosystème numérique européen et conforme aux valeurs européennes. A lire et méditer !
License
- Third Party Dependencies that have been Relicensed to AGPL : la position de la CNCF sur les projets passant sous licence AGPL et leur éventuelle intégration dans des projets CNCF. Plutôt mal parti…
Système
- negative leap second news! : une seconde est intercallée de temps à autre pour se resynchroniser avec la rotation terrestre. En général, on ajoutait une seconde. Là, on va retirer une seconde - c’est apparemment la première fois que cela se passe.
Sécurité
- Defenseless: UVA Engineering Computer Scientists Discover Vulnerability Affecting Computers Globally : Vous pensiez en avoir fini avec SPECTRE ? Les correctifs arrivaient assez tard dans la chaine de traitement, des chercheurs ont réussi à intervenir avant pour récupérer des informations. Publications à compter du mois de juin.
- Everything Old is New Again: Binary Security of WebAssembly : si certains pensaient être sauvés par WebAssembley, c’est raté. La VM WebAssembly peut avoir ses propres failles d’une part et d’autre part, un code source vulnérable en WebAssembly présenterait les mêmes failles une fois compilé.
Time Series
- $40 million to help developers measure everything that matters : Timescale annonce une levée en série B de 40 Millions de dollars - environ 2 millions d’instances actives et une dizaine de sorties produits pour le mois de Mai.
- How we made DISTINCT queries up to 8000x faster on PostgreSQL : dans le cadre de la sortie de TimescaleDB 2.2.1, l’arrivée de “Skip Scan” permet d’accélérer les
SELECT DISTINCTentre 28x et 8000x. Cela est valable tant pour les données Timescale que les données natives Postgres. Une contribution upstream est prévue. - TimescaleDB 2.3: Improving columnar compression for time-series on PostgreSQL : Après le rajout des ALTER/RENAME des colonnes compressées en 2.1 - le rajout des INSERT avec une compression en deux temps (compression de l’insert en lui même puis recompaction des données au niveau du chunk)
- QuestDB 6.0 : implémentation de la gestion du Out Of Order, amélioration sur le InfluxDB Inline Protocol ainsi que sur l’UI et la couche SQL.
- How we achieved write speeds of 1.4 million rows per second : retour plus détaillé sur la gestion du Out Of Order dans QuestDB.
- InfluxDB OSS and Enterprise Roadmap Update from InfluxDays EMEA : InfluxData juge qu’à partir de la version 2.0.6, la mise à jour depuis une version 1.8 est stable. La version 1.8 sera donc maintenue jusqu’à la fin d’année. Au-delà de cette date, les correctifs ajoutés seront dans la branche master mais il n’y aura plus de packaging de la version 1.8 OSS. Seule la version 1.8 Entreprise aura de nouveaux binaires. Abandon des binaires en 32 bits pour InfluxDB 2.x. Concernant la version Entreprise, InfluxDB 1.9 va apporter des améliorations notamment concernant le support de Flux. Par ailleurs Chronograf 1.9 et Kapacitor 1.6 vont sortir en juin avec diverses améliorations. Ces deux produits seront compatibles avec InfluxDB 2.x pour aider à la montée de version vers InfluxDB 2.x. Enfin, InfluxDB 0SS 2.1 va sortir aussi en juin avec notamment l’ajout des notebooks, les annotations sur les dashboards et des améliorations de Flux.
- Release Announcement: InfluxDB OSS and InfluxDB Enterprise 1.8.6 : version de maintenance avec une faille de sécurité pour la version Entreprise.
- Monitorer son infra avec Warp 10 - Partie 1, Partie 2, Partie 3 : Mise en oeuvre des outils de la plateforme Warp 10 pour monitorer son infrastructure. Cela couvre l’installation, la collecte des métriques, l’exploration des données et calcul des premiers métriques, et pour finir la création des dashboards.
- Mon Linky dans Warp 10 avec un joli dashboard : Ingestion des données issues du Linky dans Warp 10 et présentation de ces données dans un Dashboard Discovery.
- May 2021: Warp 10 releases 2.8.0 and 2.8.1 - SenX : En résumé (liste non exhaustive, va falloir qqs billets plus détaillés pour comprendre toutes les nouveautés) : Gestion plus fine des “capabilities” au niveau des tokens, Utilisation de FLoWS simplifié, Intégration avec la blockchain Ethereum, Des fonctions de crypto / signature / …, Des améliorations sur la manipulation de JSON, Une fonction HTTP pour permettre des appels distants, Ajout de mapper.geo.fence pour voir si un point est dans/en dehors d’une zone, Des choses autours des MACRO et plein d’autres améliorations/corrections.
- Working with GEOSHAPEs: code contest results : le corrigé du concours lancé par SenX autour des GEOSHAPEs dans Warp 10. Concours que j’ai remporté et voici mes réponses : partie 1 & partie 2
- Wikipedia / Warp 10 : Warp 10 dispose de sa page Wikipedia
- « Le bateau qui vole » : l’analytique en temps réel au service d’un skipper : de l’utilité des séries temporelles dans le monde de la course au large pour une meilleure appréhension du fonctionnement du bateau et de ses performances. Ce retour d’expérience sera le thème d’une prochaine édition du Time Series France !
Web
- Bootstrap 5 : nouvelle version majeure du framework Boostrap avec la suppression de la dépendance à JQuery et la fin de support de plein de vieux navigateurs notamment.
Web, Ops & Data - Février 2021
java repository artefact timescale postgres kapacitor grafana nomad hashicorp podman docker compose registry docker golang vscode warp10 dataviz transformation vector linterContainer et orchrestration
- Running Nomad for home server : pour avoir mené une expérience très similaire sur le mois de janvier, je me retrouve complètement dans ce retour d’expérience sur nomad (vs kubernetes dans une certaine mesure). Le trio nomad/consul/vault permet de faire des choses assez proches de ce que l’on peut faire avec kubernetes et parfois même de façon plus simple. Et ce, avec moins de couches intermédiaires (CSI, CNI, etc) mais aussi quelques fonctionnalités en moins. Un compromis assez réussi je trouve entre un docker nu et/ou avec docker-compose et un kubernetes.
- Podman 3.0 has been released! : support de docker-compose, support des noms courts d’image, amélioration sur le réseau, apport de la dernière version de buildah, correction d’une CVE, etc.
- Donating Docker Distribution to the CNCF : Docker Inc donne sa registry à la fondation CNCF pour fédérer les initiatives autour d’un même standard et élargir le champ des contributeurs/mainteneurs.
- Panorama des outils de sécurité autour des conteneurs : comparaison des outils de bonnes pratiques et d’analyses de vulnérabilités des containers docker pour améliorer la sécurité de vos conteneurs.
Code
- Gopls on by default in the VS Code Go extension - The Go Blog : amélioration du support de Go dans VSCode.
- Awesome Linters : si vous cherchez un linter, vous devriez le trouver dans ce dépot
- Into the Sunset on May 1st: Bintray, JCenter, GoCenter, and ChartCenter : JFrog va arrêter les services Bintray, JCenter, GoCenter et ChartCenter le 1er mai. La proposition est de migrer sur l’offre JFrog Cloud ou de trouver une alternative.
Monitoring & observabilité
- Datadog Acquires Timber Technologies | Datadog : Datadog achète la société Timber Technologies qui édite le project vector. Pourvu que cela ne nuise pas au projet.
- Datadog Signs Definitive Agreement to Acquire Sqreen | Datadog : Datadog achète aussi Sqreen qui était dans le domaine de la sécurité.
- Vector Remap Language : la version 0.12 de vector va apporter un nouveau langage plus fonctionnel pour définir le traitement sur ses logs. A tester !
- Building a Telegraf Assistant – UC Berkeley Codebase : des étudiants de l’universite de Berkeley ont travaillé sur la capacité de pousser une configuration à distance à telegraf. A voir si le code arrive jusque dans le produit telegraf, ce serait sympathique en tous cas !
Time Series
- Time-Series Analytics for PostgreSQL: Introducing the Timescale Analytics Project : Timescale va publier des fonctions orientées time series sous la forme d’extensions postgres. A priori réutilisable sans utiliser le reste de la base Timescale (à confirmer). De quoi simplifier certaines manipulations ?!
- TimescaleDB 2.0 is now Generally Available : annonce officielle de la sortie de TimescaleDB 2.0 même si la 2.0.0 est sortie à Noel et la 2.0.1 fin janvier.
- Grafana 7.4 released: Next-generation graph panel with 30 fps live streaming, Prometheus exemplar support, trace to logs, and more : amélioration des panels, mode livrestream pour un panel, support des variables dans les notifications d’alertes et plein d’autres choses.
- Kapacitor 1.5.8 — Rollback Announcement | InfluxData : Rollback de la version 1.5.8 de Kapacitor (la couche de processing en mode batch/streaming dans un contexte InfluxDB 1.x) pour cause d’opération pouvant conduire à de la perte de données. Un correctif est attendu sous peu.
- TL;DR InfluxDB Tech Tips – How to Monitor States with InfluxDB : ce billet est intéressant pour compléter le billet sur le calcul de la durée d’un état avec des timeseries. Notamment, l’apport de la fonction
monitor.stateChanges()etmonitor.stateChangesOnly(). - Warp 10 2.7.3 : version de maintenance.
- A review of smoothing transforms in WarpLib : revue des possibilités de “lissage” de vos séries avec différents algorithmes inclus dans Warp 10 de la moyenne glissante simple à des algorithmes capables d’excluer les anomalies et pics ponctuels.
Si vous êtes en manque de news, vous pouvez aller consulter (et vous abonner) aux brèves du BigData Hebdo
Web, Ops & Data - Juin 2018
mysql redis kubernetes aws terraform cdc debezium kafka azure elasticsearch ksql kapacitor docker docker compose docker-app buildkit hashicorp consul service-mesh istioBig Data, Machine Learning & co
- Level Up Your KSQL : Confluent met à disposition une série de vidéos pour la prise en main de KSQL.
- Rounding Up Kafka Summit London 2018 : Confluent a égalemient mis à disposition les vidéos du dernier Kafka Summit à Londres.
- Introducing Confluent Hub : Confluent lance une plateforme communautaire autour de Kafka Connect.
Cloud
- Amazon EKS – Now Generally Available : l’offre managée Kubernetes d’AWS sort en version stable.
- Azure Kubernetes Service (AKS) GA – New regions, more features, increased productivity : Pas de jaloux - Azure est aussi prêt pour son offre managée kubernetes.
- Announcing Terraform Support for Kubernetes Service on AWS : Hashicorp profite de l’annonce d’AWS pour annoncer également que Terraform permet de provisionner un cluster EKS.
- GKE vs AKS vs EKS – Hasura : comparatif synthétique des solutions managées kubernetes de Google, Azure et AWS.
Container & Orchestration
- Making Compose Easier to Use with Application Packages : Docker Inc. sort un nouveau produit appelé “docker-app”. Il se veut comme une surcouche à docker-compose en permettant d’injecter des variables dans vos fichiers docker-compose.yml. Ainsi, vous n’auriez plus qu’un seul fichier docker-compose avec ses variables et les valeurs de ses variables dans des fichiers additionnels. Lors de l’exécution du container, docker-app réconcilie les deux et lance le conteneur avec les bonnes valeurs. Docker Swarm et Kubernetes seraient supportés si l’on en croit les exemples. Rigolo, sur le principe, c’est exactement ce que je fais pour une mission actuellement…
- Découverte de Buildkit : dans le cadre du découpage de Docker en programme modulaire indépendant, Moby avait lancé Buildkit. Il s’agit du builder d’images. L’article présente son fonctionnement et son architecture.
- HashiCorp Consul 1.2: Service Mesh : Hashicorp sort en beta son offre de service mesh basé sur Consul. Après le “Service Discovery” et le “Service Configuration”, voilà le Service Mesh. A voir dans la vraie vie mais on retrouve apparemment pas mal de fonctionnalités disponibles dans Istio.
(No)SQL
- Vitess : J’en avais entendu parler, j’ai profité d’un épisode de Software Engineering Daily pour en savoir un petit peu plus : Je ne suis pas encore au bout du podcast mais cela semble être une couche entre l’application et la DB - elle analyse la requête et la distribue ensuite au sein du cluster. Vitess permettrait notamment que le développeur n’ait pas à connaitre la logique de clustering/sharding des données. L’overhead n’a pas encore été mentionné.
- Redis 5.0 RC1 : la version 5.0 de Redis pointe le bout de son nez avec notamment le type de donnée Stream - cf Introduction to redis streams
- Streaming Data out of the Monolith: Building a Highly Reliable CDC Stack : un CDC, Change Data Capture, est un système qui capture les changements de données (INSERT, UPDATE, DELETE) d’une source de données. BlaBlaCar explique ici comment ils ont mis en place leur CDC sur la base de Debezium et Kafka. Un des défis à relever étant la gestion de la déduplication des données.
- Elasticsearch 6.3.0 Released : plein de nouveautés mais la plus symoblique étant un début de support d’un requêtage SQL dans Elasticsearch.
Sécurité
- Attacking Private Networks from the Internet with DNS Rebinding : TL;DR Following the wrong link could allow remote attackers to control your WiFi router, Google Home, Roku, Sonos speakers, home thermostats and more. il est donc possible d’abuser un navigateur via un DNS malicieux et donc être en mesure de scanner le réseau local de la personne abusée. Il faut donc considérer le réseau local comme une zone hostile et y appliquer les bonnes pratiques habituelles (authentification, urls en https, etc)
Timeseries
- Les capacités d’alerting de Kapacitor : un billet sur l’utilisation de kapacitor pour générer des alertes. J’aurais bien aimé pouvoir l’avoir écrit…
- “Metrics First” Approach to Log Analysis : avec la version 1.7 de Telegraf (l’agent de collecte), un nouveau plugin syslog permet d’exposer les logs sous la forme d’événements. Et avec Chonograf 1.5, il est possible de voir ses données sous un format tabulaire. Pour autant, TICK n’a pas vocation à devenir une centrale de logs (à la ELK & co).
Astuce(s) du mois
Faîtes-vous plaisir et écouter le podcast Artisan Développeur - dans des formats de 10mn environ, un sujet autour de l’agilité, des tests, du TDD, de la responsabilité des développeurs, de SaFE, et de tout ce qui fait partie de notre quotidien de développeurs sont abordés. Depuis quelques épisodes, cela se fait en duo avec d’autres personnes (comme JP Lambert) ce qui rend les échanges encore plus intéressants. Vous retrouvez le podcast sur Soundcloud, Pocketcasts, etc.
