Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Ma comptabilité, une série temporelle comme les autres - partie 2 - actualisation des données et des prévisions
warp10 timeseries comptabilité prévision forecastSuite de notre épopée :
- Partie 1 - Premier pas avec Warp 10, comptabilité et prévisions de fin d’année
- Partie 2 - Remise à jour des données, comparaison des données prévues vs réelles, prévisions 2021 (ce billet)
- Partie 3 - Récupération des données de la Sandbox dans notre instance locale
- Partie 4 - Dashboards
- Partie 5 - Les FEC et le compte 512
- Partie 6 - Les FEC et le compte de résultat
L’année dernière, nous avions travaillé sur Warp 10 et mes données de comptabilité et jouer un peu avec les algo de prévision.
Les données comptables ayant été un peu ajustées entre temps et la librairie de prévision ayant aussi évolué coté SenX, les résultats ne sont plus tout à fait les mêmes. Nous allons donc reprendre tout ça.
Rappel des fais et prévisions à fin 2020
En septembre dernier, nous avions ce code pour avoir les données jusqu’au mois de Mai 2020 et une prévision jusqu’à la fin d’année:
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de dépenses / chiffre d'affaires / résult pour la période du 01/01/2017 -> 31/05/2020
// Chaque série est stockée dans une variable
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// On affiche les trois courbes
$revenue
$exp
$result
// On génère et affiche les prévisions - on renomme les séries pour mieux les différencier ensuite au niveau dataviz
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_expense" RENAME
Au global :
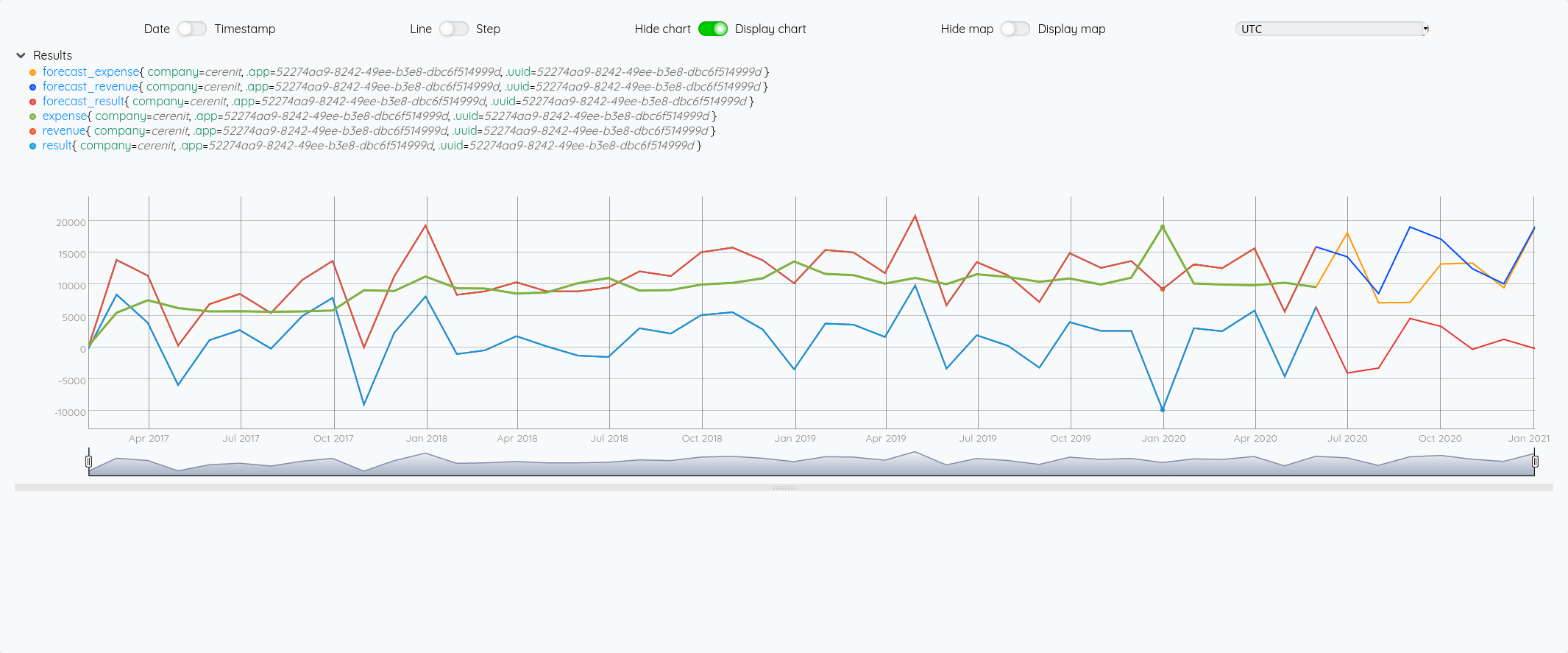
Focus 2020 avec la partie prévision à partir de juin :
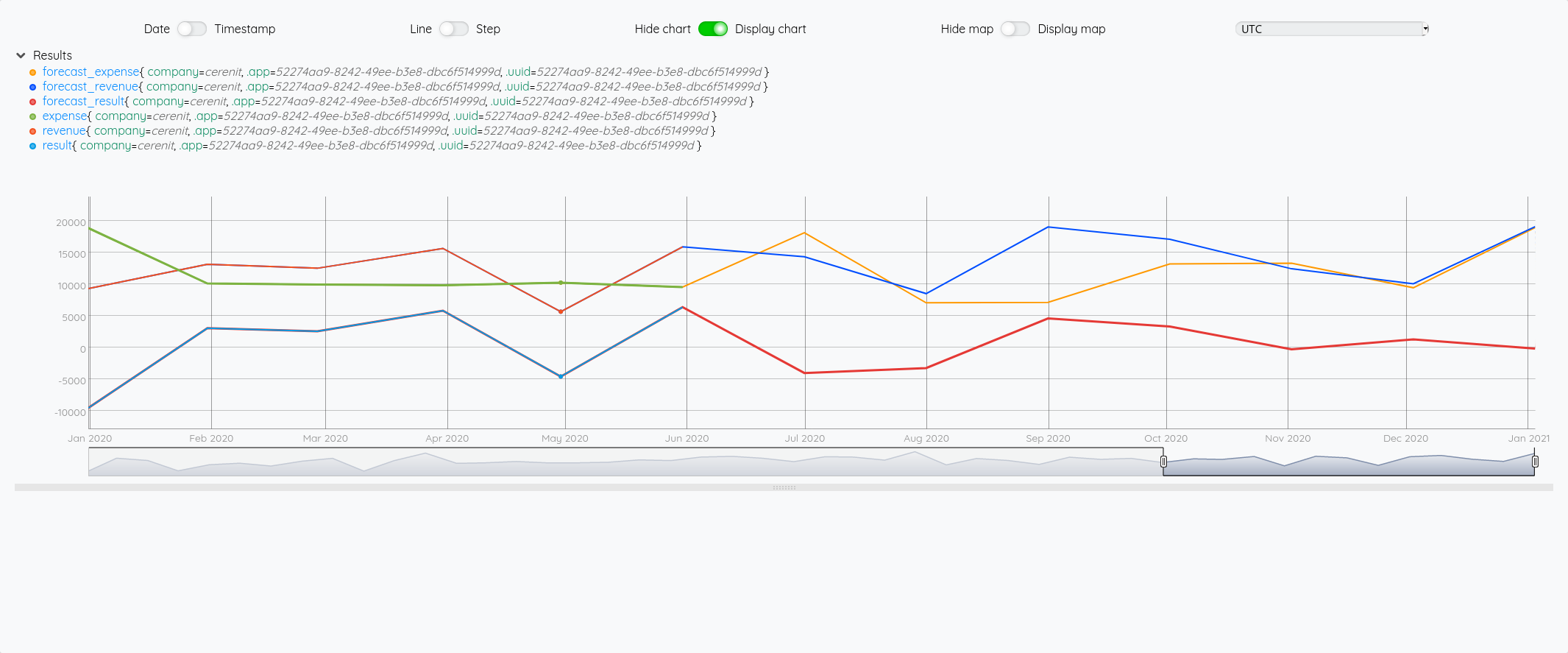
Si on fait la même chose en prenant un algo incluant un effet de saisonnalité :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de dépenses / chiffre d'affaires / résult pour la période du 01/01/2017 -> 31/05/2020
// Chaque série est stockée dans une variable
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// On affiche les trois courbes
$revenue
$exp
$result
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_expense" RENAME
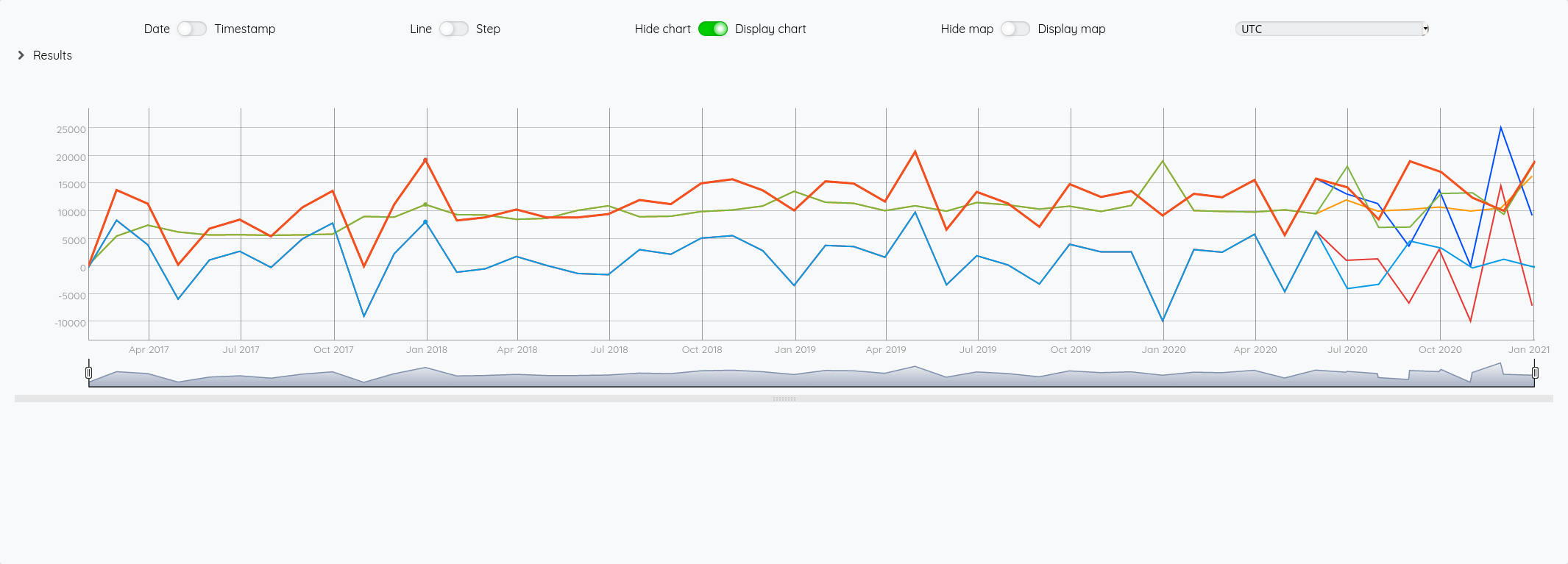
Au global :
Focus 2020 avec la partie prévision à partir de juin :
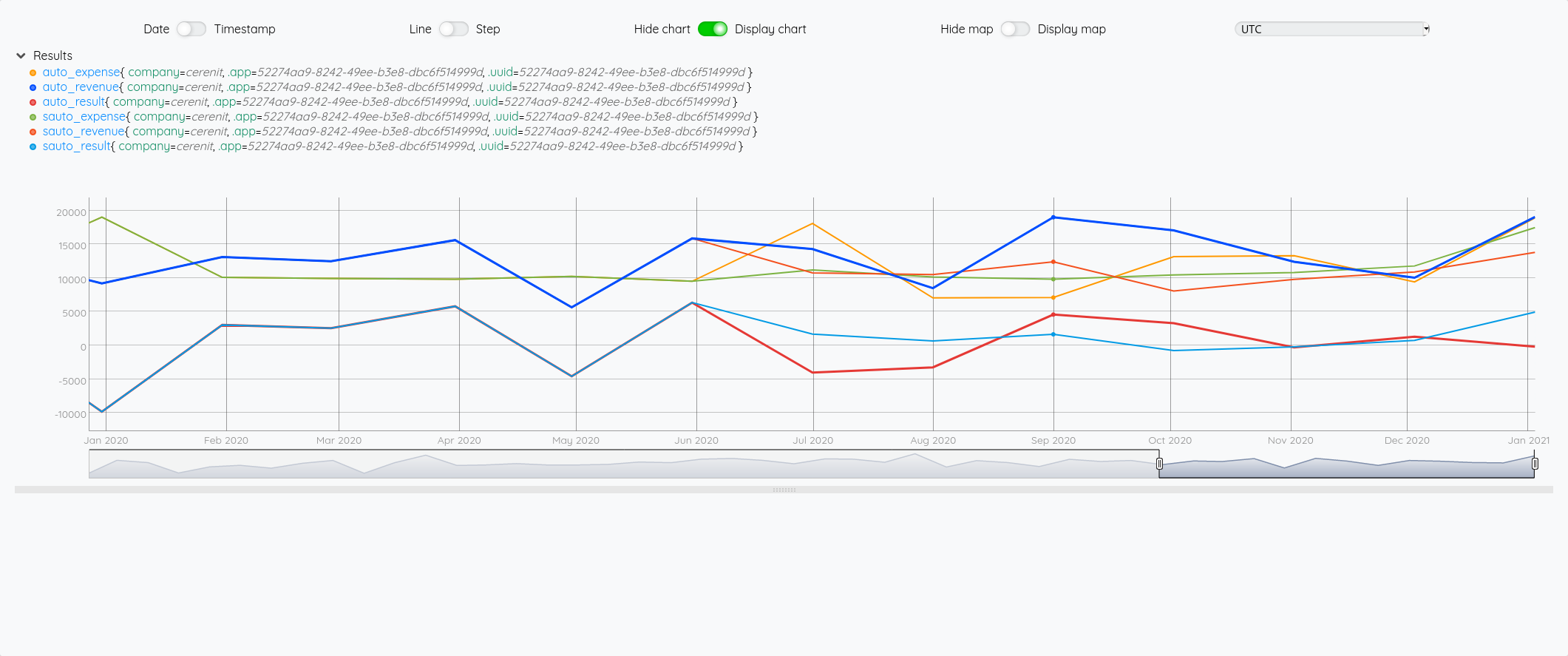
On a bien un petit écart de comportement sur la prévision entre les deux modèles (focus sur 2020 avec les différentes prévisions à partir de juin) :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de dépenses / chiffre d'affaires / résult pour la période du 01/01/2017 -> 31/05/2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_expense" RENAME
// On génère et affiche les prévisions - on renomme les séries pour mieux les différencier ensuite au niveau dataviz
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_expense" RENAME
Prévisions vs réalité
Comparons maintenant les prévisions à la réalité - je vais rajouter les requêtes pour avoir la vue complète des données - pour éviter de trop surcharger le graphique, comme les séries forecast_* reprennent les données sources et y ajoutent la prévision, je ne vais afficher que ces séries et les séries réelles :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de base qui serviront ensuite pour la prévision
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// Récupération des données réelles de la période 01/01/2017 > 31/12/2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_result' STORE
// Génération des prévisions
// Pour SAUTO, il faut définir en plus un cycle, ici 12 mois
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"forecast_expense" RENAME
$real_result
$real_revenue
$real_exp
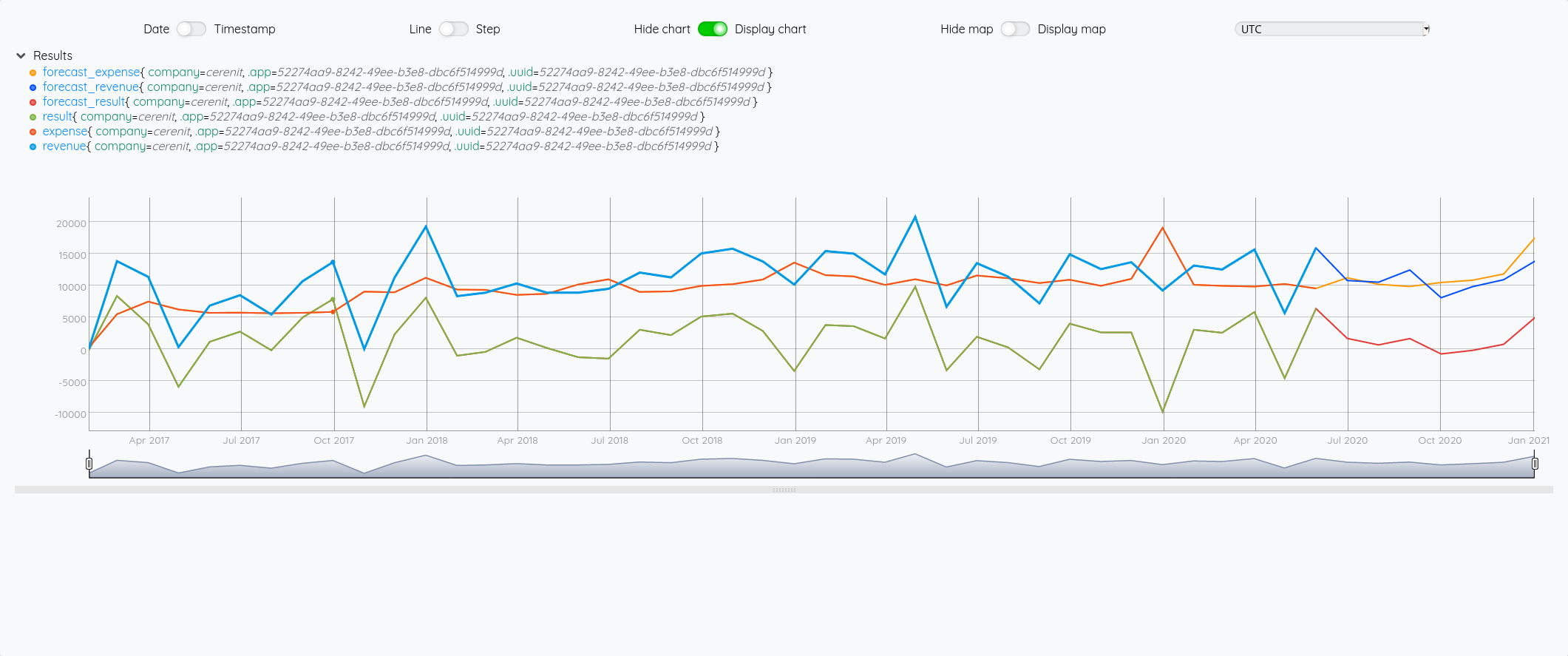
Ce qui nous donne au global :
et avec le focus 2020 :
Si on fait la même chose avec SAUTO
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des données de base qui serviront ensuite pour la prévision
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// Récupération des données réelles de la période 01/01/2017 > 31/12/2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_result' STORE
// Génération des prévisions
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_result" RENAME
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_revenue" RENAME
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"forecast_expense" RENAME
$real_result
$real_revenue
$real_exp
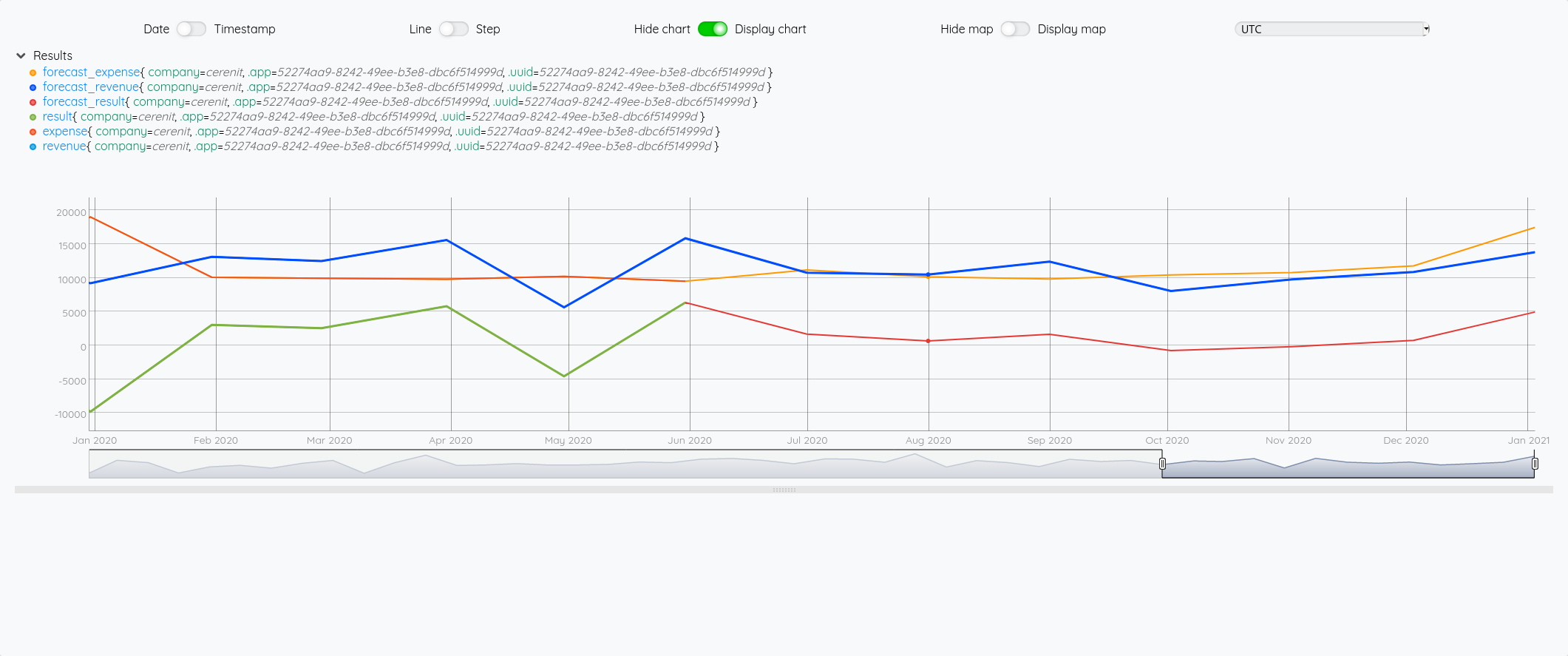
Au global :
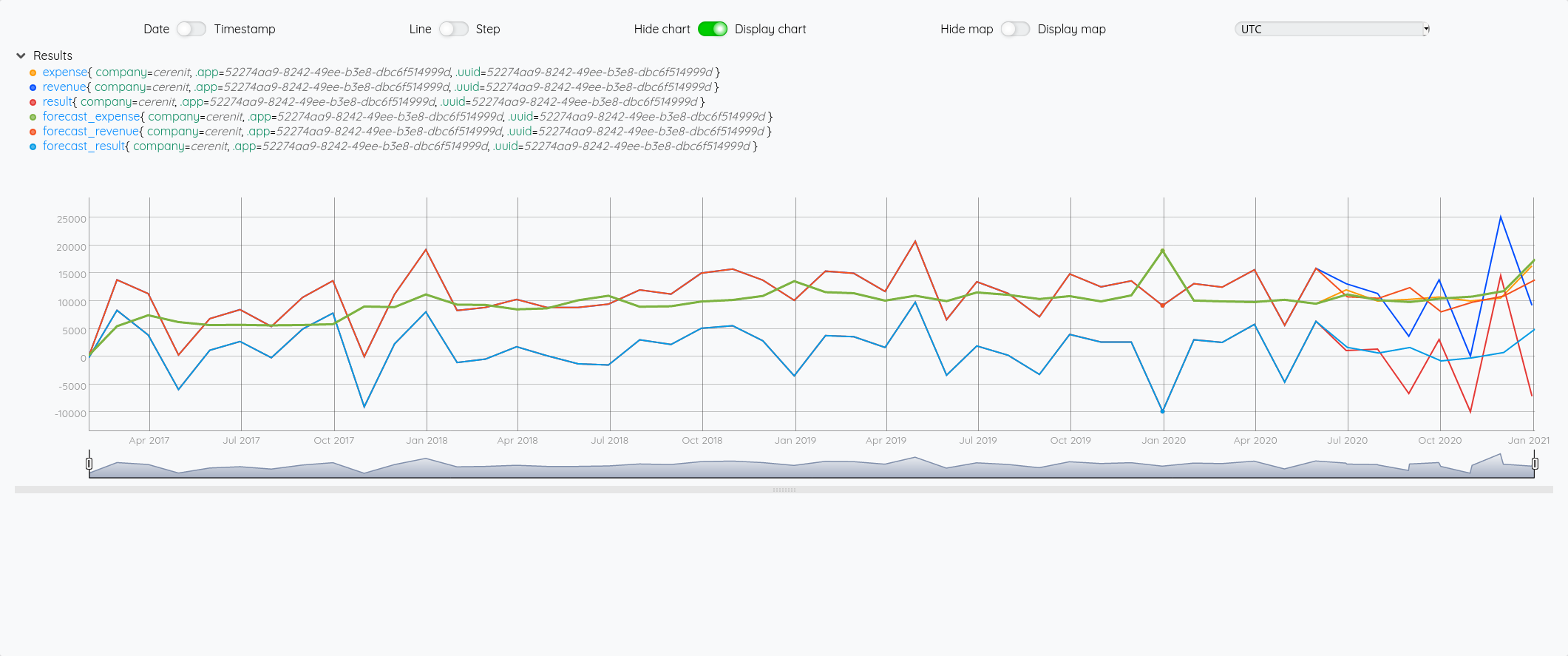
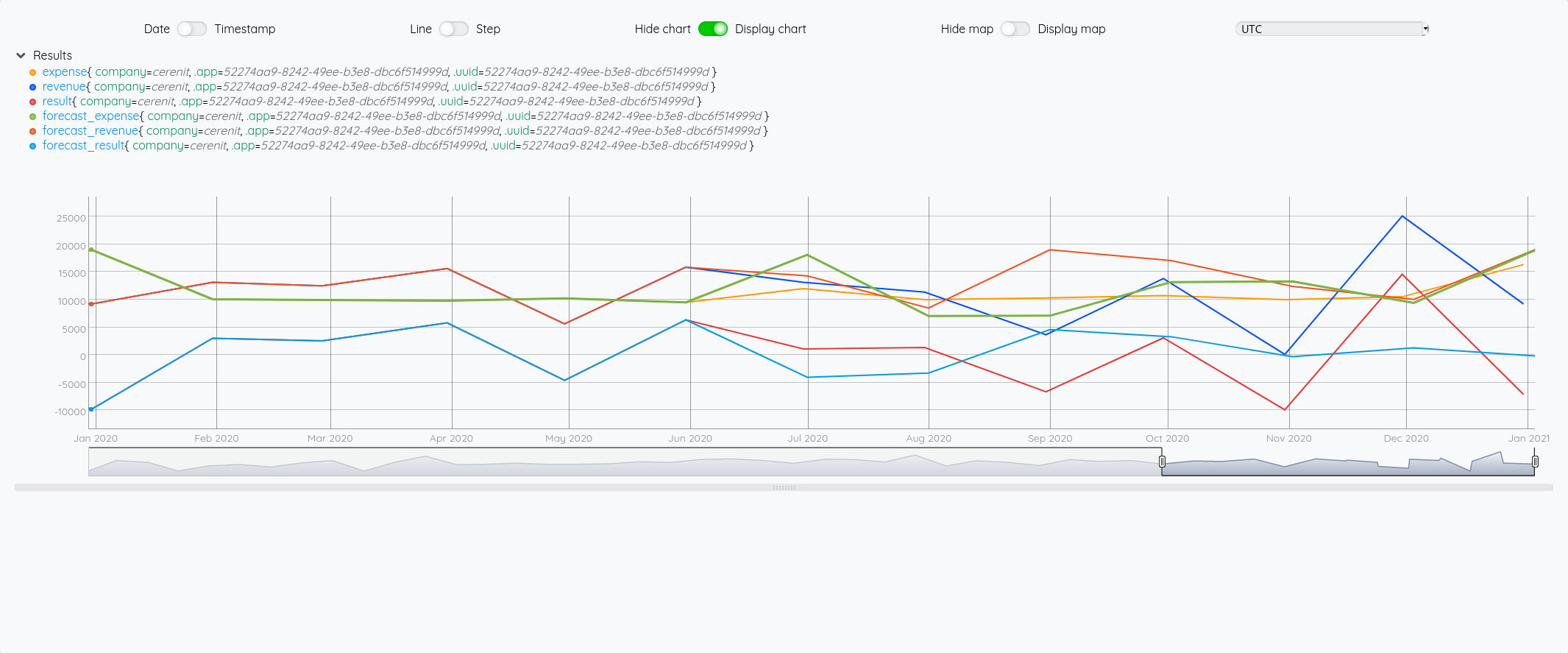
Focus 2020 avec la partie prévision à partir de juin :
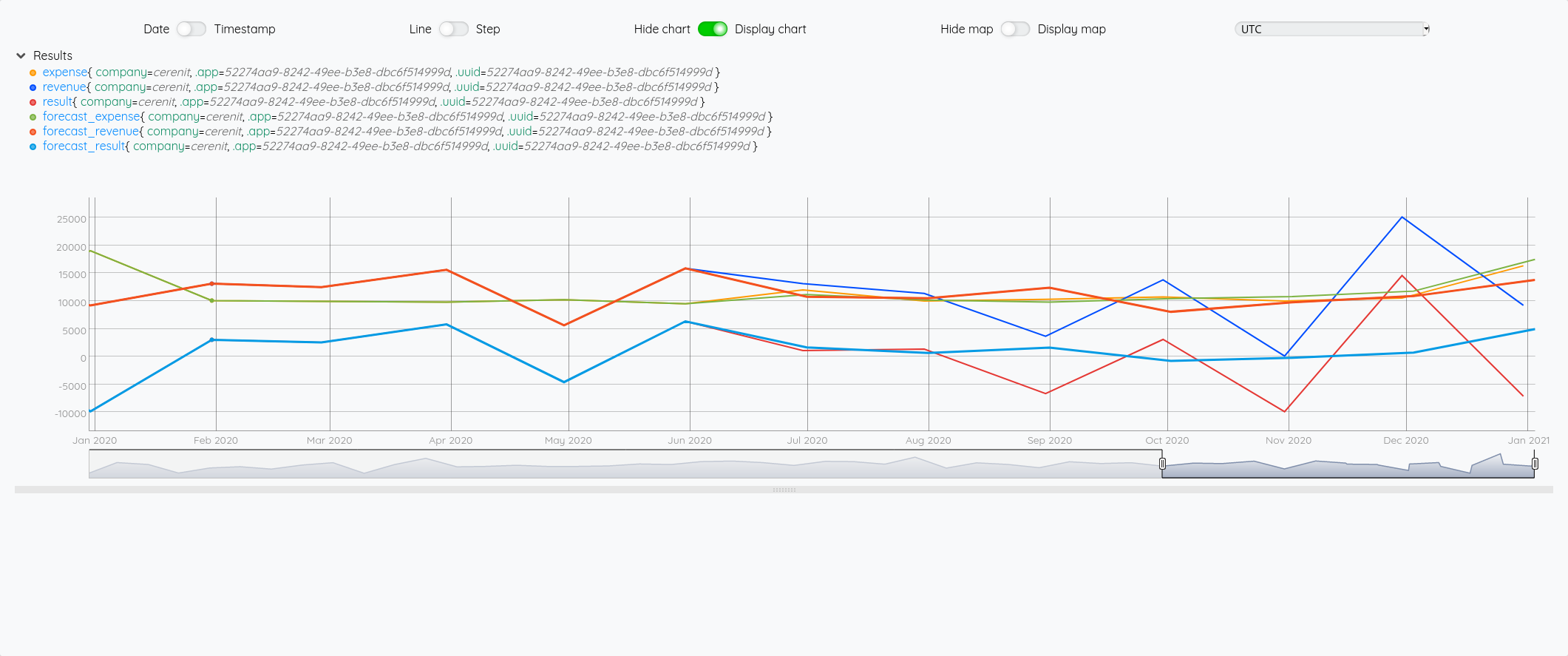
Essayons d’analyser tout ça (il faut regarder les fins de mois - les points sont en date du dernier jour du mois) :
- Pour Juin/Juillet, la prévision est plutôt bonne.
- Pour Aout : l’écart vient du fait que j’ai pris mes vacances en aout et pas à cheval sur juillet/aout comme les autres années
- Pour Septembre, c’est correct
- Pour Octobre, il faut voir que j’ai tardé à éditer mes factures - elles ont donc été pris en compte sur Novembre - si on divise le montant de Novembre en deux, on retombe à peu près sur nos points
- Pour décembre, un effet vacances également.
La pertinence est prévisions est donc plutôt correct au global et les écarts sont expliquables.
Consolidation annuelle
Et au niveau annuel ? Est-ce que les prévisions de chiffres d’affaires / dépenses / résultats sont bonnes si on ne tient plus compte des petits écarts de temps ci-dessus ?
Voyons celà :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des différentes séries comme précédemment
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2020-06-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'real_result' STORE
// Calcul des prévisions comme précédemment
// Petit ajout, on stocke le résultat sous la forme d'une variable pour être réutilisé ultérieurement
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_result" RENAME
'auto_result' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_revenue" RENAME
'auto_revenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 7 FORECAST.ADDVALUES
"auto_expense" RENAME
'auto_expense' STORE
// Aggrégation annuelle
// Utilisation de BUCKETIZE.CALENDAR et de la macro BUCKETIZE.byyear qui s'appuie dessus et qui permet de faire une aggrégation annuelle sur des données
// bucketizer.sum permet d'appliquer une somme sur les données regroupées par année
// UNBUCKETIZE.CALENDAR permet de retransformer l'indice issue de BUCKETIZE.CALENDAR en timestamp
[ $real_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $real_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $real_exp bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $auto_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $auto_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $auto_expense bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
// Meme chose pour SAUTO
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_result" RENAME
'sauto_result' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_revenue" RENAME
'sauto_revenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 7 FORECAST.ADDVALUES
"sauto_expense" RENAME
'sauto_expense' STORE
[ $sauto_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $sauto_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
[ $sauto_expense bucketizer.sum ] @senx/cal/BUCKETIZE.byyear UNBUCKETIZE.CALENDAR
Pour expliciter un peu au dessus :
On veut obtenir un résultat annuel couvant la période du 01/01 au 31/12 d’une année. Il faut donc prendre tous les points de l’année en question et en fait la somme.
Si on fait:
[ $real_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear
On obtient :
[{"c":"revenue","l":{"company":"cerenit",".app":"52274aa9-8242-49ee-b3e8-dbc6f514999d",".uuid":"52274aa9-8242-49ee-b3e8-dbc6f514999d"},"a":{".buckettimezone":"UTC",".bucketduration":"P1Y",".bucketoffset":"0"},"la":1612528364518,"v":[[47,100850],[48,132473],[49,151714],[50,139146]]}]
Les valeus obtenues sont :
[[47,100850],[48,132473],[49,151714],[50,139146]]
Les indices 47, 48, 49, 50 sont en fait un delta par rapport au 01/01/70. En effet, 2020 = 1970 + 50
En appliquant UNBUCKETIZE.CALENDAR, on retransforme ce 50 par ex en son équivalent sous la forme d’un timestamp : 1609459199999999.
On peut aussi utiliser TIMESHIFT de la façon suivante :
[ $real_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
Pour obtenir pour la partie valeur :
[[2017,100850],[2018,132473],[2019,151714],[2020,139146]]
Pour en savoir plus sur BUCKETIZE.CALENDAR et ses utilisations : Aggregate by calendar duration in WarpScript
Une fois qu’on reprend toutes ses données, on peut essayer de mesurer les écarts entre le réél et les prévisions des deux modèles :
| AUTO | SAUTO | Réel | AUTO vs Réel | SAUTO vs Réel | |
|---|---|---|---|---|---|
| Chiffre d’affaires | 144.029 | 125.128 | 139.146 | -3,39% | +11,20% |
| Dépénses | 117.701 | 113.765 | 129.464 | +9,99% | +13,80% |
| Résultat | 14.754 | 16.893 | 9.682 | -34,38% | -42,69% |
| Résultat corrigé | 26.328 | 11.363 | 9.682 | -63,23% | -14,79% |
Intéressant, la prévision de résultat n’est pas égale à la différence entre la prévision de chiffre d’affaires et la prévision des dépenses ! C’est la raison de la ligne “Résultat corrigé”.
A ce stade, il ne me semble pas possible de privilégier un modèle plus qu’un autre - même si du fait de la récurrence des vacances, on peut supposer que le modèle avec saisonnalité pourrait être plus pertinent.
Prévisions pour 2021
Pour aller au bout de cet exerice, il ne reste plus qu’à voir ce que nos algoritmes prévoient pour 2021 :
'<read token>' 'readToken' STORE
'<write token>' 'writeToken' STORE
// Récupération des séries 2017 > 2020
[ $readToken 'expense' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'exp' STORE
[ $readToken 'revenue' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'revenue' STORE
[ $readToken 'result' { 'company' '=cerenit' } '2016-12-01T00:00:00Z' '2021-01-01T00:00:00Z' ] FETCH
0 GET
'result' STORE
// Prévision sur les 12 prochains mois
[ $result mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_result" RENAME
'auto_result' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_revenue" RENAME
'auto_revenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
AUTO 12 FORECAST.ADDVALUES
"auto_expense" RENAME
'auto_expense' STORE
// Consolidation annuelle avec AUTO
[ $auto_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ $auto_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ $auto_expense bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
// Prévisions avec SAUTO
[ $result mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_result" RENAME
'sauto_result' STORE
[ $revenue mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_revenue" RENAME
'sauto_revenue' STORE
[ $exp mapper.todouble 0 0 0 ] MAP
12 SAUTO 12 FORECAST.ADDVALUES
"sauto_expense" RENAME
'sauto_expense' STORE
// Consolidation annuelle avec SAUTO
[ $sauto_revenue bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ $sauto_result bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
[ $sauto_expense bucketizer.sum ] @senx/cal/BUCKETIZE.byyear 1970 TIMESHIFT
On passe tout ça dans le shaker et on obtient :
| Prévu avec AUTO | Prévu avec SAUTO | |
|---|---|---|
| Chiffre d’affaires | 78.230 | 129.465 |
| Dépénses | 118.383 | 110.434 |
| Résultat prévu | 5.730 | 4.049 |
| Résultat corrigé | -40.153 | 19.031 |
Rendez-vous à la fin de l’année pour voir ce qu’il en est… et on peut espérer que la réalité sera proche du modèle avec saisonnalité !
Pour le moment, on travalle toujours dans le WarpStudio et on voudrait bien avoir des (jolis) dashboards qui font tout ça pour nous plutôt que de copier/coller du Warpscript. Ce sera le sujet de la partie 3.
