Architecte de vos plateformes/produits et agitateur de séries temporelles
Conception, développement, déploiement et exploitation de vos plateformes, applications et données.
Contactez-nous !
Web, Ops, IoT et Time Series - Décembre 2024
ia rpi pico raspberry warp10 anthropic mcp pydantic navigateurBienvenue dans cette dernière édition pour 2024 où l’IA prend une grande place et la question permanente de ses potentiels et ses risques pour un usage éclairé.
La tech est tout sauf uniquement technique, elle est éminemment politique et sociétale. Cette fin d’année avec les élections américaines l’a bien montré et les déclarations récentes du patron de Palantir indiquant que la révolution IA est américaine ne fait qu’enfoncer le clou et nous oblige à nous poser des questions sur le futur que l’on construit pour éviter l’accélérationnisme / le solutionnisme technologique naïf ou la décroissance et assimilés.
Dans les derniers épisodes du podcast Silicon Carne, Carlos Diaz note l’évolution d’un débat classique “gauche vs droite” vers “croissance vs décroissance” et questionne la notion de progrès. Dans ces podcasts, les épisodes sur le Silicon Valley partagés précédemment ainsi que le voyage de Mathieu Stefani aux USA, il apparait aussi le trait culturel de regarder vers le futur (aux USA) versus vers le passé (en Europe).
Si tout n’est pas rose outre-atlantique, sachons nous en inspirer pour dépasser nos contraintes/limites et faire évoluer nos postures pour construire un futur désirable.
IA
- Intelligence artificielle : le match perdu de l’université face au privé & IA, le cri d’alerte de Standford: Depuis 2023, la recherche universitaire n’a plus les moyens financiers et humains pour faire leurs recherches face aux entreprises privées. Stanford propose une loi “Create AI” pour permettre au monde académique de rester dans la course.
- PydanticAI : Pydantic se décline en version IA avec un framework pour créer des agents IA.
- L’horreur existentielle de l’usine à trombones : quand IA et usines de trombones ne font pas bon ménage - enfin en fonction de où on se place…
- Model Context Protocol : Anthropic publie le protocole client/serveur qui fait le pont entre les sources de données et les LLM et ce sous licence opensource. Des connecteurs sont mis à disposition : GDrive, Postgres, etc. Un pas de plus pour la simplification de création d’agents.
- compar:IA : beta.gouv.fr lance son comparateur d’IA afin de vous sensibiliser aux performances des différents modèles et les évaluer.
- Algorithmique : Un podcast produit par Next en 6 épisodes sur ce qu’est l’intelligence artificielle depuis ses origines à ses opportunités en passant par les débats et les interrogations qu’elle suscite. Des articles reprenant certaines interviews en format long sont également publiés en complément à l’écoute (il faut chercher un peu dans l’historique des articles de l’auteur).
- Will AI eat the brower ? : Depuis 20+ ans, nous accédions à la connaissance à travers un navigateur - l’IA va-t-elle le ringardiser et changer notre mode de consommation des données ?
Raspberry
- [Tuto] Raspberry Pi Pico 2 W : mise en route, Wi-Fi et première application : Prise en main et premières interactions avec le Raspberry Pico 2W.
- Raspberry Pi Compute Module 5 : jusqu’à 16 Go de LPDDR4X et 64 Go de MLC, dès 45 dollars : la déclinaison compacte et sans ports du RPi5 pour des usages industriels est disponible. Reste à trouver le modèle qui vous convient parmi les 32 variantes et voici comment installer Raspberry Pi OS sur l’eMMC.
Time Series
- Warp 10 3.4.x : Les améliorations de
FILLlui permettant de gérer plusieurs séries d’un coup et les apports deLOWERHULLetUPERHULLpour apprécier les seuils minimum et maximum de séries devraient permettre certaines analyses complémentaires.
🎄 Bonnes fêtes de fin d’année à tous et à l’année prochaine. 🎄
Rendez-vous à la fin du mois prochain pour une nouvelle édition.
Web, Ops, IoT et Time Series - Juin 2024
caddy reverse-proxy api https fastapi parquet postgres htmx python ruff queue lakehouse repository pattern warp10API
- Your API Shouldn’t Redirect HTTP to HTTPS : La redirection http > https est souvent vu comme un confort et une bonne pratique - mais finalement peut être pas tant que ça ?
Data
- Parquet & AI = 🙅♂️⛔️? : Rappel de ce qu’est le format parquet, ses limites et les nouveaux formats en cours d’élaboration (Lance & Nimble) pour les workloads IA (mais pas que ?)
- pg_lakehouse via Musings on Data Lakes and Kafka Connect: une extension Postgres pour manipuler vos fichiers Parquet/CSV/JSON/Avro stockés dans vos espaces de stockage objets (S3, etc)
- Announcing DuckDB 1.0.0 : Rien de nouveau hormis une étape importante du projet.
- Command Line Data Processing: Using DuckDB as a Unix Tool : Pas envie de faire du awk/sed/grep/…, alors faites le en duckdb 😏
- When and Why to Automate: A Data Engineer’s Perspective & Debugging Data Pipelines : hasard de publication mais une continuité logique : vous avez le quand, pourquoi et comment automatiser une tâche (data pipeline).
IoT
- Raspberry Pi AI Kit available now at $70 - Même le Raspberry Pi 5 succombe à l’IA… - Sortie d’un Kit Raspberry Pi AI à base de M2 HAT et de l’accélérateur AI Hailo 8L : Même le RPI se met à l’IA
- News from LoRaWAN Live Munich : Globalement, les déploiements s’intensifient et pour un usage princiapelemnt autour des mesures. Les fabricants comme STM ou Semtech proposent des cartes plus complètes et intégrées (SoC). Il y a des devices qui émergent pour des petits déploiements.
Python
- SqlAlchemy 1.4 async ORM with FastAPI : en 2022, nous avions utilisé cet article comme base pour les projets FastAPI. Il couvrait de bout en bout ce que l’on attendait : SQLAlechmy, Alembic (migrations), Async et Tests. Le petit plus est sur le pattern du Repository, fort utile pour avoir une abstraction au dessus de la base de données.
- Fast API — Repository Pattern and Service Layer : une version plus récente, rajoutant le concept de Service en plus de celui du Repository.
- FastCRUD : Un meta-package qui vous embarque tout pour générer dynamiquement vos endpoints d’API sur la base de vos modèles de données.
- FastHX, fastapi-htmx & Using HTMX with FastAPI : pour ceux qui veulent faire du FastAPI et du HTMX
- FastUI : un projet de l’équipe de Pydantic pour générer des interfaces web à partir de votre code Python.
- Summary of Major Changes Between Python Versions : Liste des principales évolutions et principaux apports d’une version majeure de Pytohn à une autre.
- Adopt-Ruff : un outil pour trouver les règles Ruff que votre projet ne respecte pas encore en vue de pouvoir les ajouer au fur et à mesure.
- Introduction to Polars : tout est dans le titre, une introduction à Polars.
Ops
- Caddy 2.8.x (dernière version: 2.8.4 : quelques fonctionnalités supplémentaires au niveau de HTTP/3 ou des certificats, mais surtout un gros travail de nettoyage et de rationnalisation de code (dépendances dépréciées / non maintenues, etc).
- Le projet Caddy-Docker-Proxy passe en version version 2.9.x en intégrant Caddy 2.8.
Time Series
- Announcing the Private Beta of SenX SaaS Platform : SenX lance son offre SaaS pour la suite Warp10 (Warp 10, Discovery,etc) et des fonctionnalités dédiées/avancées/améliorées des produits existants.
Web
- Queueing - An interactive study of queueing strategies : intéressant tant sur le fond que la forme sur la gestion des queues dans des requêtes HTTP et les différentes stratégies pouvant être mises en place.
Web, Ops, IoT et Time Series - Avril 2024
redis licence xz backdoor valkey ia http2 warp10 duckdb jq hashicorp ibm sxswData
- DuckDB as the new JQ : DuckDB pouvant lire des fichiers JSON, il était tentant pour certains de manipuler des fichiers JSON en SQL…
Database
- Redis Adopts Dual Source-Available Licensing | Redis - The race to replace Redis - Linux Foundation Launches Open Source Valkey Community : A compter de la version 7.4, Redis passe d’une version open source (licence BSD) à une double licence “Source Available” pour officiellement contrer les vilains méchants concurrents qui ne reversent pas à la communauté. Bizarrement, la “Common Clause” adoptée en 2018 pour les mêmes raisons n’a pas suffit. La réponse de la communauté ne s’est pas fait attendre avec la création du projet Valkey sous l’égide de la Linux Foundation. Si le passage d’un projet dans le giron d’une fondation peut rassurer ses utilisateurs et contributeurs sur la licence du projet, il n’en reste pas moins qu’il faut sécuriser les revenus de la société éditrice du projet. Cela pose aussi la question de notre attachement à l’Open Source - est-ce par philosophie ou par confort d’utilisation et la gratuité ? La fin de l’argent facile montre aussi les limites du financement des projets OSS via des VC ; certains ont fait évolué leur produit de façon plus subtile (ou pas) ou leur criticité est moindre pour ne pas provoquer une réaction comme pour Redis (Inc).
- Valkey 7.2.5 : Première version de Valkey, un Redis 7.2.4 nettoyé et avec quelques améliorations. Cela aura été rapide, mais avant de sauter le pas, il va falloir voir comment l’écosystème prend…
IA
- Ce que l’histoire du tracteur peut nous apprendre sur l’impact prévisible de l’IA : analogie entre l’adoption du tracteur et de l’IA - tant que le cout du tracteur est plus cher que les humains ou de leur quantité, le tracteur ne s’est pas développé. Dès qu’il y a eu pénurie de main d’oeuvre ou que le cout des tracteurs a baissé, son adoption s’est accélérée. En serat-t-il de même pour l’IA ?
- SXSW 2024 : face à l’IA, les entreprises en pleine gueule de bois & [Crash Tech] SXSW 2024 : surtout, don’t panic ! : retour sur le festival SXSW où les réflexions autour de l’IA sont nombreuses avec un petit coup de gueule de bois.
Infrastructure as Code
- HashiCorp joins IBM to accelerate multi-cloud automation : après le changement de licence en aout 2023, il semblait assez évident qu’HashiCorp cherchait à se faire racheter. IBM est donc l’heureux élu avec une valorisation d’HashiCorp à 6.4 Milliards de dollars. Après l’arrivée des projets OpenTofu (fork de Terraform) et OpenBao (fork de Vault) sous l’égide de la Linux Foundation, on pouvait se demander comment cela allait finir pour Hashicorp. Même si IBM contribue à l’open source, on aurait pu espérer meilleure maison pour HashiCorp. IBM n’est pas forcément perçu comme une zone d’innovation. Une piste qui pourrait néanmoins être intéressante avec cette acquisition et pour réconcilier la communauté, c’est que HashiCorp soit rattaché à Red Hat dans une division “Cloud & Automatisation / DevSecOps” au coté de projets comme Ansible par ex.
Sécurité
- backdoor in upstream xz/liblzma leading to ssh server compromise - Une backdoor bien critique découverte dans xz Utils / liblzma - XZ et liblzma: Faille de sécurité volontairement introduite depuis au moins deux mois - Who in the world is Jia Tan? : Au delà d’illustrer que toute l’infrastructure moderne dépend d’un petit projet maintenu par une seule et unique personne, l’arrivée de cette backdoor dans
xzvia les fichiers de tests est assez édifiante et digne d’un film d’espionnage tant cette opération semble préparée. - New HTTP/2 DoS attack can crash web servers with a single connection - HTTP/2 CONTINUATION Flood : une vulnérabilité HTTP/2 fort symathique pour vos frontaux mais aussi par ex vos cluster kubernetes
Time Series
- SenX, recognized as a leader in Time Series data management. : SenX, éditeur de la plateforme Warp 10 est (enfin) reconnu comme leader dans le monde des séries temporelles. J’ai bien fait de miser sur Warp 10 tiens !
- Trace Plugin: the WarpScript Debugger is here! : SenX sort un plugin sous lience commerciale pour débugguer votre code WarpScript (mais pas que). Testable sur la sandbox
Web, Ops, IoT et Time Series - Mars 2024
python postgres warp10 datacontract golang psycopg ingestr mistral htmx http architecture organisation hackingCode
- One Billion Rows Challenge in Golang : une version très détaillée des optimisations apportées pour réussir le défi du moment du “One Billion Row Challenge” en Go. Certaines sont évidentes, d’autres sont plus surprenantes ou moins évidentes.
- Modern Git Commands and Features You Should Be Using : bon,
git switch, je l’avais déjà. Pour les autres…
Database
- Psycopg2 vs Psycopg3 Performance Benchmark : Passez à Psycopg3(+async) dans la plupart des cas. Et si ça vous suffit pas, asyncpg se disait globalement 5 fois plus rapide que psycopg3 en juin 2023.
- Ingester : un outil en CLI pour copier vos données d’une base vers une autre.
IA
- Mistral dans le giron de Microsoft : le défi du rattrapage européen dans l’IA reste ouvert et L’alliance entre Mistral et Microsoft met fin à l’illusion de l’indépendance technologique européenne : mise en perspective et bon résumé sur la situation Mistral / Europe / Microsoft - on en parle d’ailleurs avec Vincent dans l’épisode du BigDataHebdo : Episode 186 : plus jQuery que Terraform
- 25 recommandations pour l’IA en France.
Metadata
- DataContracts et DataContract CLI : si le sujet du DataContract m’a plutôt fait pensé à l’architecte d’entreprise qui urbanie son système d’information, en regardant de plus près, je me dis que dans le cadre d’un usage d’API, en complément du modèle fourni par OpenAPI/Swagger, cela pourrait donner une profondeur d’analyse aux API.
Organisation
- Context-switching - one of the worst productivity killers in the engineering industry : gestion du temps et des interruptions en tant que développeur / manager / manager de managers.
- Simplifying as much as possible is the way to go in the engineering industry : rendez-vous service et cherchez toujours la solution la plus simple pour répondre à un besoin métier. Fuyez la complexité. Mais garder un code simple ou répondre simplement à un besoin n’est pas toujours chose aisée.
Outillage
- Project Discovery - Open Source Tools : le Project Discovery, communauté autour du scan de vulnérabilité met un certain nombre d’outils à disposition. Cela peut être utile à des fins offensives/défensives mais aussi pour du debug.
- No Maintenance Intended : le badge qu’il vous faut aposer à vos projets si vous n’avez aucune intention de les maintenir.
Time Series
- Warp 10 3.2 : une version corrective et l’annonce de l’arrivée prochaine du Trace Plugin. Ce plugin doit aiser le debug de votre code WarpScript. Il sera soumis à licence et évaluable sur la Sandbox.
Web
- HTTP > Headers > Connection : vous voulez que votre serveur de destination ferme à coup sur la connection après vous avoir répondu dans le cadre d’un appel HTTP/1.1 ? Alors l’entête
Connection: closeest fait pour vous. La connection HTTP/1.1 est par défaut en modekeep-alive. Si vous avez des reverse proxy au milieu, cela peut éviter qu’il cherche à maintenir des connections ouvertes alors que cela n’a plus lieu d’être. - HTMX via Django REST Framework and Vue versus Django and HTMX: Pour ceux qui veulent l’interactivité de Javascript, mais sans faire du Javascript
IoT - Qualité de l'air avec un esp32 (TTGo T-Display), le service ThingSpeak, du MQTT, Warp 10 et Discovery
iot mqtt arduino warp10 thingspeak co2 esp32 discovery dashboardLe projet Nous Aérons propose de réaliser ses propres détecteurs de CO2 avec un ESP32 avec un écran comme le Lilygo TTGo T-Display et un capteur Senseair S8-LP.
L’idée est donc de déployer plusieurs capteurs, faire remonter les valeurs via ThingSpeak et ensuite les ingérer puis analyser avec Warp 10 et faire un dashboard avec Discovery.
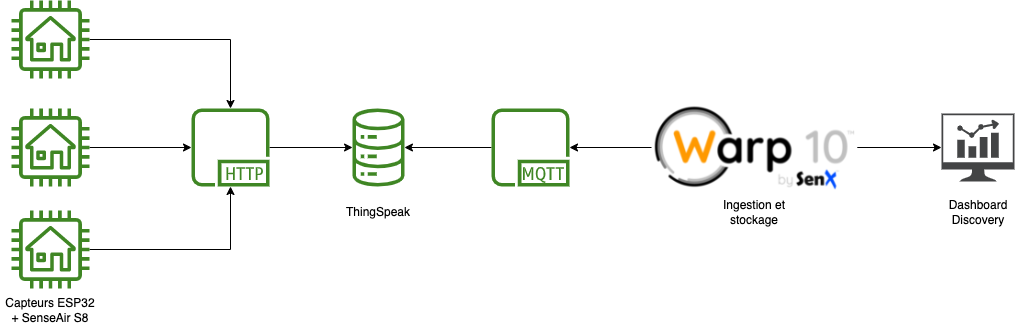
Montage
Pour le montage, je vous invite à consuler principalement :
- Capteur de CO2 et le code
- Les instructions des projets “BEL AIR” et “GRAND AIR” à récupérer via le site de Nous Aérons
- Premiers pas ESP32 : Application de démo du TTGO T-Display : pour la configuration d’Arduino IDE - pour l’application de démo, les chemins ont changé par contre.
- Sous OSX, j’ai du récupérer la version 1.6+ du driver du chipset et être en mesure d’avoir le port
/dev/cu.wchusbserial*afin de pouvoir uploader le code depuis Arduino IDE vers l’ESP32.
ThingSpeak
L’exemple de code fourni utilise le service ThingSpeak pour la remontée des valeurs. Comme il s’agit de mon premier projet Arduino et que cela fonctionne, j’ai cherché à rester dans les clous du code proposé et tester par la même occasion ce service. J’aurais pu directement poster les valeurs sur mon instance Warp 10 mais c’est aussi l’occasion de tester la récupération d’informations via le client MQTT de Warp 10.
Il vous faut :
- Créer un compte
- Créer un channel avec le champ 1 qui accueillera vos données
- Récupérer la clé d’API en écriture
- Noter votre Channel ID
Code Arduino
Disclaimer : c’est mon premier projet Arduino.
En repartant du code fourni sur le site Capteur de CO2, j’ai fait quelques ajustements :
- Remplacer l’appel HTTP par la librairie ThingSpeak
- La librairie retourne des status code :
200si c’est OK,40xsi incorrect et-XXXsi erreur ; j’ai un amélioré le message de debug pour savoir si l’insertion était OK ou KO. - Ajustement de positionnement du “CO2” et du “ppm” sur l’écran pour une meilleure lisibilité.
Il vous faut modifier :
- la configuration wifi :
ssid1,password1et éventuellementssid2,password2 - la configuration ThingSpeak :
channelID,writeAPIKey
Compiler le tout et uploader le code sur votre ESP32.
/************************************************
*
* Capteur de CO2 par Grégoire Rinolfi
* https://co2.rinolfi.ch
*
***********************************************/
#include <TFT_eSPI.h>
#include <SPI.h>
#include <Wire.h>
#include <WiFiMulti.h>
#include <ThingSpeak.h>
WiFiMulti wifiMulti;
TFT_eSPI tft = TFT_eSPI(135, 240);
/************************************************
*
* Paramètres utilisateur
*
***********************************************/
#define TXD2 21 // série capteur TX
#define RXD2 22 // série capteur RX
#define BOUTON_CAL 35
#define DEBOUNCE_TIME 1000
const char* ssid1 = "wifi1";
const char* password1 = "XXXXXXXXXXXXXXXX";
const char* ssid2 = "wifi2";
const char* password2 = "XXXXXXXXXXXXXXXX";
unsigned long channelID = XXXXXXXXXXXXXXXX;
char* readAPIKey = "XXXXXXXXXXXXXXXX";
char* writeAPIKey = "XXXXXXXXXXXXXXXX";
unsigned int dataFieldOne = 1; // Field to write temperature data
const unsigned long postingInterval = 12L * 1000L; // 12s
unsigned long lastTime = 0;
// gestion de l'horloge pour la validation des certificats HTTPS
void setClock() {
configTime(0, 0, "pool.ntp.org", "time.nist.gov");
Serial.print(F("Waiting for NTP time sync: "));
time_t nowSecs = time(nullptr);
while (nowSecs < 8 * 3600 * 2) {
delay(500);
Serial.print(F("."));
yield();
nowSecs = time(nullptr);
}
Serial.println();
struct tm timeinfo;
gmtime_r(&nowSecs, &timeinfo);
Serial.print(F("Current time: "));
Serial.print(asctime(&timeinfo));
}
/************************************************
*
* Thinkgspeak functions
* https://fr.mathworks.com/help/thingspeak/read-and-post-temperature-data.html
*
***********************************************/
float readTSData( long TSChannel,unsigned int TSField ){
float data = ThingSpeak.readFloatField( TSChannel, TSField, readAPIKey );
Serial.println( " Data read from ThingSpeak: " + String( data, 9 ) );
return data;
}
// Use this function if you want to write a single field.
int writeTSData( long TSChannel, unsigned int TSField, float data ){
int writeSuccess = ThingSpeak.writeField( TSChannel, TSField, data, writeAPIKey ); // Write the data to the channel
if(writeSuccess == 200){
Serial.println("Channel updated successfully!");
}
else{
Serial.println("Problem updating channel. HTTP error code " + String(writeSuccess));
}
return writeSuccess;
}
// Use this function if you want to write multiple fields simultaneously.
int write2TSData( long TSChannel, unsigned int TSField1, long field1Data, unsigned int TSField2, long field2Data ){
ThingSpeak.setField( TSField1, field1Data );
ThingSpeak.setField( TSField2, field2Data );
int writeSuccess = ThingSpeak.writeFields( TSChannel, writeAPIKey );
if(writeSuccess == 200){
Serial.println("Channel updated successfully!");
}
else{
Serial.println("Problem updating channel. HTTP error code " + String(writeSuccess));
}
return writeSuccess;
}
/************************************************
*
* Code de gestion du capteur CO2 via ModBus
* inspiré de : https://github.com/SFeli/ESP32_S8
*
***********************************************/
volatile uint32_t DebounceTimer = 0;
byte CO2req[] = {0xFE, 0X04, 0X00, 0X03, 0X00, 0X01, 0XD5, 0XC5};
byte ABCreq[] = {0xFE, 0X03, 0X00, 0X1F, 0X00, 0X01, 0XA1, 0XC3};
byte disableABC[] = {0xFE, 0X06, 0X00, 0X1F, 0X00, 0X00, 0XAC, 0X03}; // écrit la période 0 dans le registre HR32 à adresse 0x001f
byte enableABC[] = {0xFE, 0X06, 0X00, 0X1F, 0X00, 0XB4, 0XAC, 0X74}; // écrit la période 180
byte clearHR1[] = {0xFE, 0X06, 0X00, 0X00, 0X00, 0X00, 0X9D, 0XC5}; // ecrit 0 dans le registe HR1 adresse 0x00
byte HR1req[] = {0xFE, 0X03, 0X00, 0X00, 0X00, 0X01, 0X90, 0X05}; // lit le registre HR1 (vérifier bit 5 = 1 )
byte calReq[] = {0xFE, 0X06, 0X00, 0X01, 0X7C, 0X06, 0X6C, 0XC7}; // commence la calibration background
byte Response[20];
uint16_t crc_02;
int ASCII_WERT;
int int01, int02, int03;
unsigned long ReadCRC; // CRC Control Return Code
void send_Request (byte * Request, int Re_len)
{
while (!Serial1.available())
{
Serial1.write(Request, Re_len); // Send request to S8-Sensor
delay(50);
}
Serial.print("Requete : ");
for (int02 = 0; int02 < Re_len; int02++) // Empfangsbytes
{
Serial.print(Request[int02],HEX);
Serial.print(" ");
}
Serial.println();
}
void read_Response (int RS_len)
{
int01 = 0;
while (Serial1.available() < 7 )
{
int01++;
if (int01 > 10)
{
while (Serial1.available())
Serial1.read();
break;
}
delay(50);
}
Serial.print("Reponse : ");
for (int02 = 0; int02 < RS_len; int02++) // Empfangsbytes
{
Response[int02] = Serial1.read();
Serial.print(Response[int02],HEX);
Serial.print(" ");
}
Serial.println();
}
unsigned short int ModBus_CRC(unsigned char * buf, int len)
{
unsigned short int crc = 0xFFFF;
for (int pos = 0; pos < len; pos++) {
crc ^= (unsigned short int)buf[pos]; // XOR byte into least sig. byte of crc
for (int i = 8; i != 0; i--) { // Loop over each bit
if ((crc & 0x0001) != 0) { // If the LSB is set
crc >>= 1; // Shift right and XOR 0xA001
crc ^= 0xA001;
}
else // else LSB is not set
crc >>= 1; // Just shift right
}
} // Note, this number has low and high bytes swapped, so use it accordingly (or swap bytes)
return crc;
}
unsigned long get_Value(int RS_len)
{
// Check the CRC //
ReadCRC = (uint16_t)Response[RS_len-1] * 256 + (uint16_t)Response[RS_len-2];
if (ModBus_CRC(Response, RS_len-2) == ReadCRC) {
// Read the Value //
unsigned long val = (uint16_t)Response[3] * 256 + (uint16_t)Response[4];
return val * 1; // S8 = 1. K-30 3% = 3, K-33 ICB = 10
}
else {
Serial.print("CRC Error");
return 99;
}
}
// interruption pour lire le bouton d'étalonnage
bool demandeEtalonnage = false;
void IRAM_ATTR etalonnage() {
if ( millis() - DEBOUNCE_TIME >= DebounceTimer ) {
DebounceTimer = millis();
Serial.println("Etalonnage manuel !!");
tft.fillScreen(TFT_BLACK);
tft.setTextSize(3);
tft.setTextColor(TFT_WHITE);
tft.drawString("Etalonnage", tft.width() / 2, tft.height()/2);
demandeEtalonnage = true;
}
}
// nettoie l'écran et affiche les infos utiles
void prepareEcran() {
tft.fillScreen(TFT_BLACK);
// texte co2 à gauche
tft.setTextSize(4);
tft.setTextColor(TFT_WHITE);
tft.drawString("CO",25, 120);
tft.setTextSize(3);
tft.drawString("2",60, 125);
// texte PPM à droite ppm
tft.drawString("ppm",215, 120);
// écriture du chiffre
tft.setTextColor(TFT_GREEN,TFT_BLACK);
tft.setTextSize(8);
}
void setup() {
// bouton de calibration
pinMode(BOUTON_CAL, INPUT);
// ports série de debug et de communication capteur
Serial.begin(115200);
Serial1.begin(9600, SERIAL_8N1, RXD2, TXD2);
// initialise l'écran
tft.init();
delay(20);
tft.setRotation(1);
tft.fillScreen(TFT_BLACK);
tft.setTextDatum(MC_DATUM); // imprime la string middle centre
// vérifie l'état de l'ABC
send_Request(ABCreq, 8);
read_Response(7);
Serial.print("Période ABC : ");
Serial.printf("%02ld", get_Value(7));
Serial.println();
int abc = get_Value(7);
// active ou désactive l'ABC au démarrage
if(digitalRead(BOUTON_CAL) == LOW){
if(abc == 0){
send_Request(enableABC, 8);
}else{
send_Request(disableABC, 8);
}
read_Response(7);
get_Value(7);
}
tft.setTextSize(2);
tft.setTextColor(TFT_BLUE,TFT_BLACK);
tft.drawString("Autocalibration", tft.width() / 2, 10);
if( abc != 0 ){
tft.drawString(String(abc)+"h", tft.width() / 2, 40);
}else{
tft.drawString("OFF", tft.width() / 2, 40);
}
// gestion du wifi
wifiMulti.addAP(ssid1, password1);
wifiMulti.addAP(ssid2, password2);
Serial.print("Connexion au wifi");
tft.setTextSize(2);
tft.setTextColor(TFT_WHITE,TFT_BLACK);
tft.drawString("Recherche wifi", tft.width() / 2, tft.height() / 2);
int i = 0;
while(wifiMulti.run() != WL_CONNECTED && i < 3){
Serial.print(".");
delay(500);
i++;
}
if(wifiMulti.run() == WL_CONNECTED){
tft.setTextColor(TFT_GREEN,TFT_BLACK);
Serial.println("Connecté au wifi");
Serial.println("IP address: ");
Serial.println(WiFi.localIP());
tft.drawString("Wifi OK", tft.width() / 2, 100);
setClock();
}else{
tft.setTextColor(TFT_RED,TFT_BLACK);
Serial.println("Echec de la connexion wifi");
tft.drawString("Pas de wifi", tft.width() / 2, 100);
}
delay(3000); // laisse un temps pour lire les infos
// préparation de l'écran
prepareEcran();
//interruption de lecture du bouton
attachInterrupt(BOUTON_CAL, etalonnage, FALLING);
}
unsigned long ancienCO2 = 0;
int seuil = 0;
void loop() {
// effectue l'étalonnage si on a appuyé sur le bouton
if( demandeEtalonnage ){
demandeEtalonnage = false;
// nettoye le registre de verification
send_Request(clearHR1, 8);
read_Response(8);
delay(100);
// demande la calibration
send_Request(calReq, 8);
read_Response(8);
delay(4500); // attend selon le cycle de la lampe
// lit le registre de verification
send_Request(HR1req, 8);
read_Response(7);
int verif = get_Value(7);
Serial.println("resultat calibration "+String(verif));
if(verif == 32){
tft.setTextColor(TFT_GREEN);
tft.drawString("OK", tft.width() / 2, tft.height()/2+30);
}else{
tft.setTextColor(TFT_RED);
tft.drawString("Erreur", tft.width() / 2, tft.height()/2+20);
}
delay(3000);
prepareEcran();
seuil = 0;
}
// lecture du capteur
send_Request(CO2req, 8);
read_Response(7);
unsigned long CO2 = get_Value(7);
String CO2s = "CO2: " + String(CO2);
Serial.println(CO2s);
// efface le chiffre du texte
if(CO2 != ancienCO2){
tft.fillRect(0,0, tft.width(), 60, TFT_BLACK);
}
if( CO2 < 800 ){
tft.setTextColor(TFT_GREEN,TFT_BLACK);
if( seuil != 1 ){
tft.setTextSize(2);
tft.fillRect(0,61, tft.width(), 25, TFT_BLACK);
tft.drawString("Air Excellent", tft.width() / 2, tft.height() / 2 + 10);
}
seuil = 1;
}else if( CO2 >= 800 && CO2 < 1000){
tft.setTextColor(TFT_ORANGE,TFT_BLACK);
if( seuil != 2 ){
tft.setTextSize(2);
tft.fillRect(0,61, tft.width(), 25, TFT_BLACK);
tft.drawString("Air Moyen", tft.width() / 2, tft.height() / 2 + 10);
}
seuil = 2;
}else if (CO2 >= 1000 && CO2 < 1500){
tft.setTextColor(TFT_RED,TFT_BLACK);
if( seuil != 3 ){
tft.setTextSize(2);
tft.fillRect(0,61, tft.width(), 25, TFT_BLACK);
tft.drawString("Air Mediocre", tft.width() / 2, tft.height() / 2 + 10);
}
seuil = 3;
}else{
tft.setTextColor(TFT_RED,TFT_BLACK);
if( seuil != 4 ){
tft.setTextSize(2);
tft.fillRect(0,61, tft.width(), 25, TFT_BLACK);
tft.drawString("Air Vicie", tft.width() / 2, tft.height() / 2 + 10);
}
seuil = 4;
}
tft.setTextSize(8);
tft.drawString(String(CO2), tft.width() / 2, tft.height() / 2 - 30);
// envoi de la valeur sur le cloud
if((millis() - lastTime) >= postingInterval) {
if((wifiMulti.run() == WL_CONNECTED)) {
WiFiClient client;
ThingSpeak.begin( client );
writeTSData( channelID , dataFieldOne , CO2 );
lastTime = millis();
}
}
ancienCO2 = CO2;
delay(10000); // attend 10 secondes avant la prochaine mesure
}
MQTT
Sur ThingSpeak, aller dans Devices > MQTT et compléter si besoin avec la lecture de la documentation MQTT Basics:
- Créer un device,
- Ajouter la/les channel(s) voulu(s),
- Limiter les droits à la partie “subscribe” ; notre client en effet n’est pas prévu pour publier des données sur ThingSpeak,
- Conserver précautionneusement vos identifiants MQTT.
Sur l’instance Warp 10, déployer le plugin MQTT :
Avec le script /path/to/warp10/mqtt/test.mc2 :
// subscribe to the topics, attach a WarpScript™ macro callback to each message
// the macro reads ThingSpeak message to extract the first byte of payload,
// the server timestamp, the channel id and the value
'Loading MQTT ThingSpeak Air Quality Warpscript™' STDOUT
{
'host' 'mqtt3.thingspeak.com'
'port' 1883
'user' 'XXXXXXXXXX'
'password' 'XXXXXXXXXX'
'clientid' 'XXXXXXXXXX'
'topics' [
'channels/channelID 1/subscribe'
'channels/channelID 2/subscribe'
'channels/channelID 3/subscribe'
]
'timeout' 20000
'parallelism' 1
'autoack' true
'macro'
<%
//in case of timeout, the macro is called to flush buffers, if any, with NULL on the stack.
'message' STORE
<% $message ISNULL ! %>
<%
// message structure :
// {elevation=null, latitude=null, created_at=2022-01-11T10:02:27Z, field1=412.00000, field7=null, field6=null, field8=null, field3=null, channel_id=1630275, entry_id=417, field2=null, field5=null, field4=null, longitude=null, status=null}
$message MQTTPAYLOAD 'ascii' BYTES-> JSON-> 'TSmessage' STORE
$TSmessage 'created_at' GET TOTIMESTAMP 'ts' STORE
$TSmessage 'channel_id' GET 'channelId' STORE
$TSmessage 'field1' GET 'sensorValue' STORE
$message MQTTTOPIC ' ' +
$ts ISO8601 + ' ' +
$channelId TOSTRING + ' ' +
$sensorValue +
STDOUT // print to warp10.log
%> IFT
%>
}
Vous devriez avoir dans /path/to/warp10/log/warp10.log :
Loading MQTT ThingSpeak Air Quality Warpscript™
channels/<channelID 1>/subscribe 2022-01-11T10:30:51.000000Z <channelID 1> 820.00000
channels/<channelID 2>/subscribe 2022-01-11T10:30:53.000000Z <channelID 2> 715.00000
channels/<channelID 3>/subscribe 2022-01-11T10:30:54.000000Z <channelID 3> 410.00000
Maintenant que l’intégration MQTT est validée, supprimez ce fichier et passons à la gestion de la persistence des données dans Warp 10.
Avec le script suivant :
// subscribe to the topics, attach a WarpScript™ macro callback to each message
// the macro reads ThingSpeak message to extract the first byte of payload,
// the server timestamp, the channel id and the value.
{
'host' 'mqtt3.thingspeak.com'
'port' 1883
'user' 'XXXXXXXXXX'
'password' 'XXXXXXXXXX'
'clientid' 'XXXXXXXXXX'
'topics' [
'channels/channelID 1/subscribe'
'channels/channelID 2/subscribe'
'channels/channelID 3/subscribe'
]
'timeout' 20000
'parallelism' 1
'autoack' true
'macro'
<%
//in case of timeout, the macro is called to flush buffers, if any, with NULL on the stack.
'message' STORE
<% $message ISNULL ! %>
<%
// message structure :
// {elevation=null, latitude=null, created_at=2022-01-11T10:02:27Z, field1=412.00000, field7=null, field6=null, field8=null, field3=null, channel_id=1630275, entry_id=417, field2=null, field5=null, field4=null, longitude=null, status=null}
$message MQTTPAYLOAD 'ascii' BYTES-> JSON-> 'TSmessage' STORE
$TSmessage 'created_at' GET TOTIMESTAMP 'ts' STORE
$TSmessage 'channel_id' GET 'channelId' STORE
$TSmessage 'field1' GET 'sensorValue' STORE
// Tableau de correspondance entre mes channel IDs et mes devices en vue de définir des labels pour les GTS
{
<channelID 1> 'air1'
<channelID 2> 'air2'
<channelID 3> 'air3'
} 'deviceMap' STORE
// Récupération du nom du device dans la variable senssorId
$deviceMap $channelId GET 'sensorId' STORE
// Création d'une GTS air.quality.home
// Le label "device" aura pour valeur le nom du device, via la variable sensorId
// On crée une entrée qui correspond à la valeur que nous venons de récupérer
// sensorValue est une string, il faut la repasser sur un format numérique
// Une fois la GTS reconstituée avec son entrée, on la periste en base via UPDATE
'<writeToken>' 'writeToken' STORE
NEWGTS 'air.quality.home' RENAME
{ 'device' $sensorId } RELABEL
$ts NaN NaN NaN $sensorValue TODOUBLE TOLONG ADDVALUE
$writeToken UPDATE
%> IFT
%>
}
Depuis le WarpStudio, vérifiez la disposnibilité de vos données :
'<readToken>' 'readToken' STORE
[ $readToken 'air.quality.home' {} NOW -1000 ] FETCH
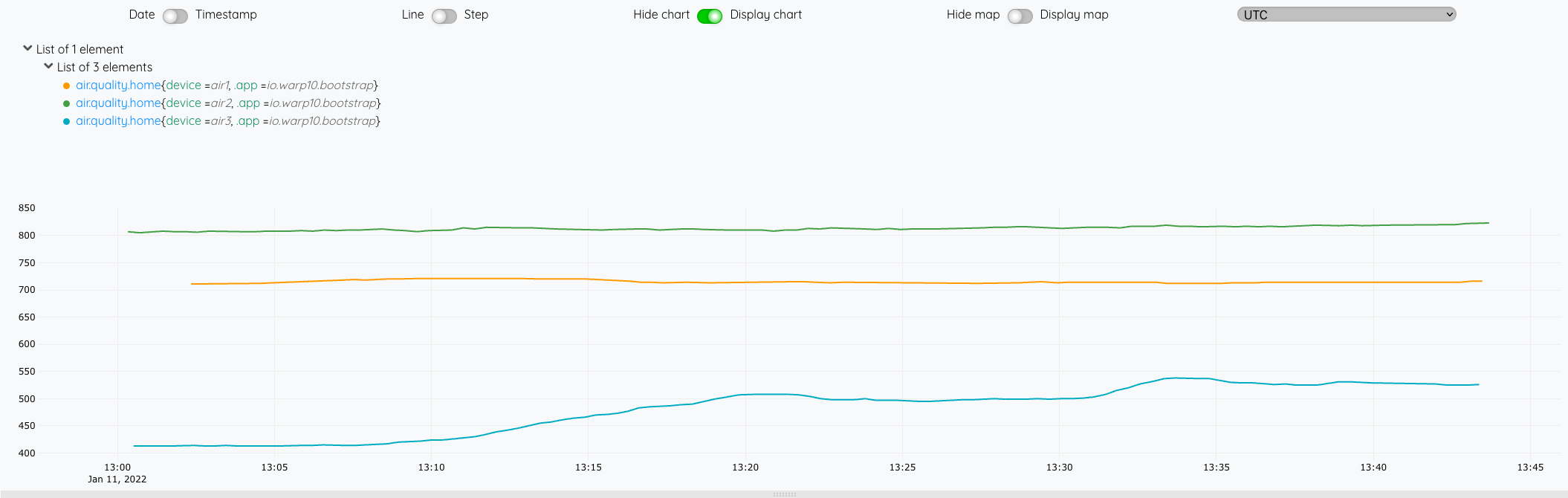
Ensuite, il nous reste plus qu’à faire une petite macro et un dashboard pour présenter les données.
Pour la macro :
- On lui passe un nom de device en paramètre qui servira à filtrer sur le label
- Elle retourne une GTS avec l’ensemble des valeurs disponibles
<%
{
'name' 'cerenit/iot/co2'
'desc' 'Provide CO2 levels per device'
'sig' [ [ [ [ 'device:STRING' ] ] [ 'result:GTS' ] ] ]
'params' {
'device' 'String'
'result' 'GTS'
}
'examples' [
<'
air1 @cerenit/iot/co2
'>
]
} INFO
// Actual code
SAVE 'context' STORE
'device' STORE // Save parameter as year
'<readToken>' 'readToken' STORE
[ $readToken 'air.quality.home' { 'device' $device } MAXLONG MINLONG ] FETCH
0 GET
$context RESTORE
%>
'macro' STORE
$macro
Et pour le dashboard Discovery :
- Chaque tile utilise la macro que l’on vient de réaliser en lui passant le device en paramètre,
- Chaque tile affiche un système de seuils avec des couleurs associées.
<%
{
'title' 'Home CO2 Analysis'
'description' 'esp32 + Senseair S8 sensors at home'
'options' {
'scheme' 'CHARTANA'
}
'tiles' [
{
'title' 'Informations'
'type' 'display'
'w' 6 'h' 1 'x' 0 'y' 0
'data' {
'data' 'Détails et informations complémentaires : <a href="https://www.cerenit.fr/blog/air-quality-iot-esp32-senseair-thingspeak-mqtt-warp10-discovery/">IoT - Qualité de l air avec un esp32 (TTGo T-Display), le service ThingSpeak, du MQTT, Warp 10 et Discovery</a>'
}
}
{
'title' 'Device AIR1'
'type' 'line'
'w' 6 'h' 2 'x' 0 'y' 1
'macro' <% 'air1' @cerenit/macros/co2 %>
'options' {
'thresholds' [
{ 'value' 400 'color' '#008000' }
{ 'value' 600 'color' '#329932' }
{ 'value' 800 'color' '#66b266' }
{ 'value' 960 'color' '#ffdb99' }
{ 'value' 1210 'color' '#ffa500' }
{ 'value' 1760 'color' '#ff0000' }
]
}
}
{
'title' 'Device AIR2'
'type' 'line'
'w' 6 'h' 2 'x' 6 'y' 1
'macro' <% 'air2' @cerenit/macros/co2 %>
'options' {
'thresholds' [
{ 'value' 400 'color' '#008000' }
{ 'value' 600 'color' '#329932' }
{ 'value' 800 'color' '#66b266' }
{ 'value' 960 'color' '#ffdb99' }
{ 'value' 1210 'color' '#ffa500' }
{ 'value' 1760 'color' '#ff0000' }
]
}
}
{
'title' 'Device AIR3'
'type' 'line'
'w' 6 'h' 2 'x' 0 'y' 3
'macro' <% 'air3' @cerenit/macros/co2 %>
'options' {
'thresholds' [
{ 'value' 400 'color' '#008000' }
{ 'value' 600 'color' '#329932' }
{ 'value' 800 'color' '#66b266' }
{ 'value' 960 'color' '#ffdb99' }
{ 'value' 1210 'color' '#ffa500' }
{ 'value' 1760 'color' '#ff0000' }
]
}
}
]
}
{ 'url' 'https://w.ts.cerenit.fr/api/v0/exec' }
@senx/discovery2/render
%>
Le résultat est alors :
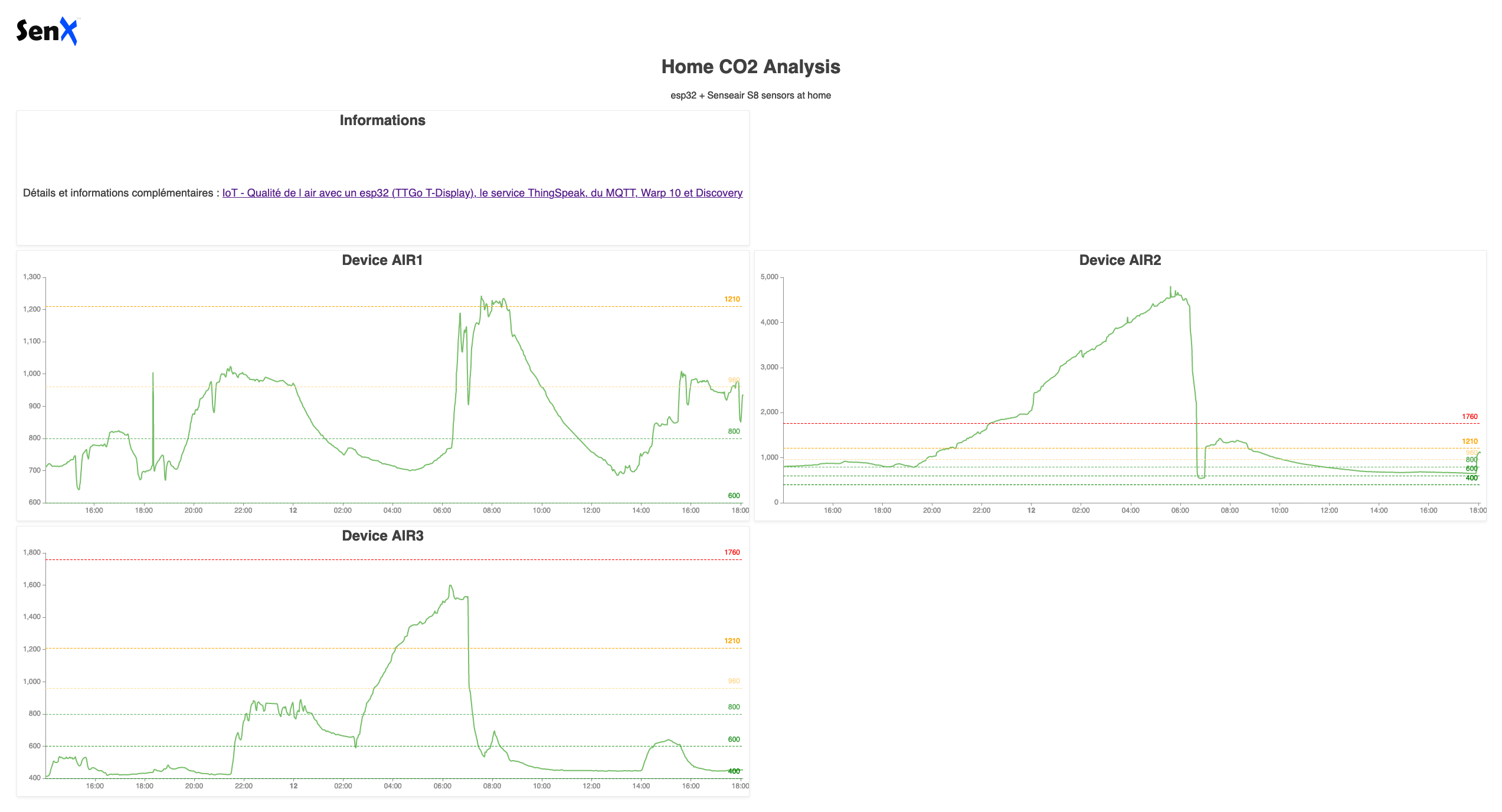
Bilan de ce que nous avons vu :
- Comment monter son capteur de CO2 en profitant des ressources mises à disposition par le projet “Nous Aérons”,
- Comment envoyer les données du capteur vers le service ThingSpeak,
- Comment récupérer les données du service ThingSpeak via le protoole MQTT et les stocker dans Warp 10,
- Comment créer un dashboard Discovery avec une macro permettant de récupérer les données et mettre en place un système de seuils.
